序列化(二)之Dubbo实现
本文基于 Dubbo 2.6.1 版本,望知悉。
1. 概述
本文分享基于 Dubbo 自己实现的序列化拓展。要实现序列化的高性能,需要考虑两方面:
- 序列化和反序列化速度快
- 从传输体积小 角度,数据压缩效果好,即序列化后的数据量
旁白君:从以下开始,Dubbo 指的是 Dubbo 序列化拓展,而不是 Dubbo PRC 框架。请注意。
在 《用户指南 —— 性能测试报告》 和 《在Dubbo中使用高效的Java序列化(Kryo和FST)》 中,我们可以看到,Dubbo 是一种相对优秀的实现方式。虽然,在最新版本的 Dubbo 项目中,dubbo-serialize 模块已经去除了 Dubbo 序列化的实现,猜测因为引入 Kryo 和 FST ,相比来说更优秀。
当然,即使如此,艿艿觉得了解下 Dubbo 序列化是如何实现的,是一种非常棒的眼界提升,特别是序列化的数据压缩,在很多场景下都会使用,例如 Lucene 的数据存储。
下面,我们跟着代码,一起愉快的玩耍把。本文涉及代码如下:
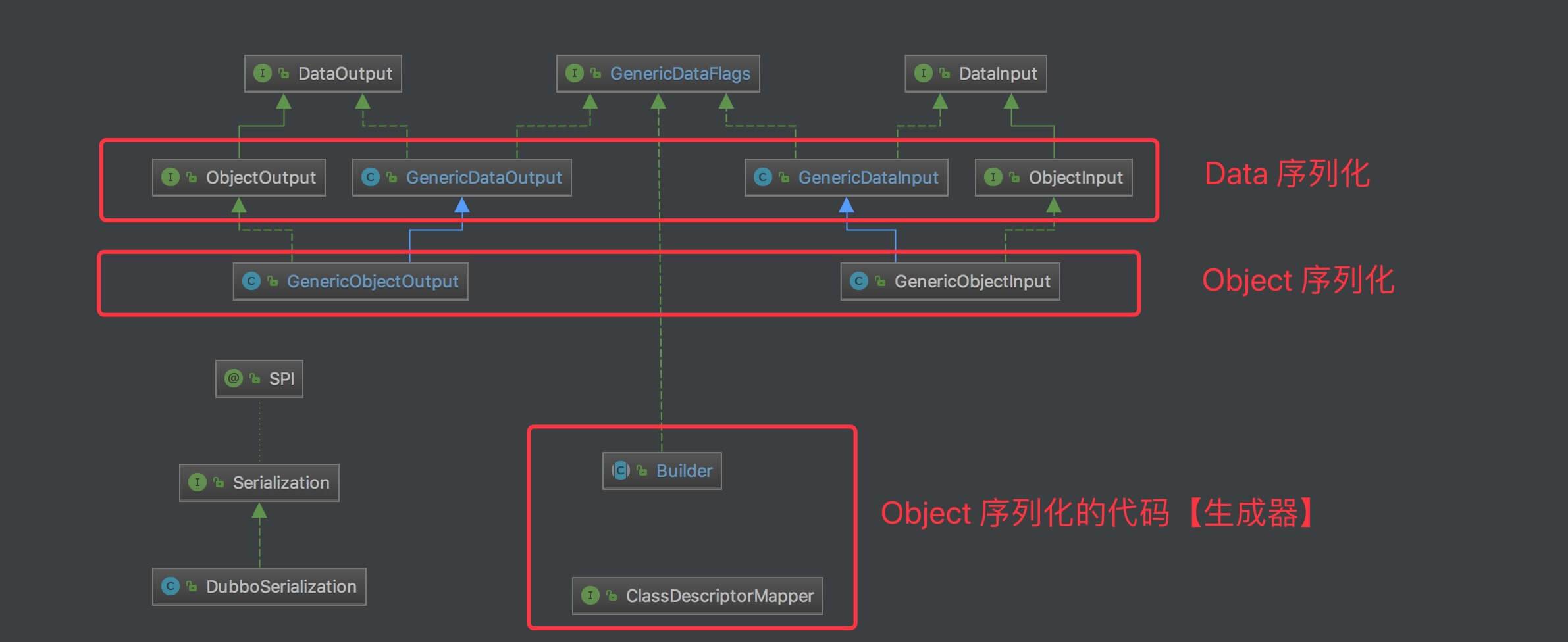
类图
写的有点匆忙,也有点着急,如果有错误,或者不清晰的地方,请往死里抽(告诉)我。哈哈哈。
2. GenericDataFlags
Dubbo ,是一种有序、紧凑的序列化方式。如下是序列化后的二进制数据流的示意图:

二进制数据流
- 不同于 JSON / XML 等序列化方式,无需序列化每个属性名具体 。通过 Builder 对象,创建每个类的序列化和反序列化的 代码。
- 这样,我们就避免了属性名 的序列化,提升了速度,减少了数据的体积。
- 当然,反过来说,如果对象发生了变化不兼容顺序 ( 增加或删除属性 ),可能会出现 Client 和 Server 序列化的 ,因为属性的 发生了变化。
- 属性值和属性值之间无间隔标志位 ,通过属性值的 Flag 保证,也就是本小节要分享的 GenericDataFlags 。
下面,我们来看看 com.alibaba.dubbo.common.serialize.support.dubbo.GenericDataFlags ,通用数据标记位枚举,代码如下:
```plain text plain public interface GenericDataFlags { // prefix three bits byte VARINT = 0, // 0 数字 OBJECT = (byte) 0x80; // -128 对象 // varint tag byte VARINT8 = VARINT, VARINT16 = VARINT | 1, VARINT24 = VARINT | 2, VARINT32 = VARINT | 3; byte VARINT40 = VARINT | 4, VARINT48 = VARINT | 5, VARINT56 = VARINT | 6, VARINT64 = VARINT | 7; // varint contants byte VARINT_NF = VARINT | 10, VARINT_NE = VARINT | 11, VARINT_ND = VARINT | 12; byte VARINT_NC = VARINT | 13, VARINT_NB = VARINT | 14, VARINT_NA = VARINT | 15, VARINT_N9 = VARINT | 16; byte VARINT_N8 = VARINT | 17, VARINT_N7 = VARINT | 18, VARINT_N6 = VARINT | 19, VARINT_N5 = VARINT | 20; byte VARINT_N4 = VARINT | 21, VARINT_N3 = VARINT | 22, VARINT_N2 = VARINT | 23, VARINT_N1 = VARINT | 24; byte VARINT_0 = VARINT | 25, VARINT_1 = VARINT | 26, VARINT_2 = VARINT | 27, VARINT_3 = VARINT | 28; byte VARINT_4 = VARINT | 29, VARINT_5 = VARINT | 30, VARINT_6 = VARINT | 31, VARINT_7 = VARINT | 32; byte VARINT_8 = VARINT | 33, VARINT_9 = VARINT | 34, VARINT_A = VARINT | 35, VARINT_B = VARINT | 36; byte VARINT_C = VARINT | 37, VARINT_D = VARINT | 38, VARINT_E = VARINT | 39, VARINT_F = VARINT | 40; byte VARINT_10 = VARINT | 41, VARINT_11 = VARINT | 42, VARINT_12 = VARINT | 43, VARINT_13 = VARINT | 44; byte VARINT_14 = VARINT | 45, VARINT_15 = VARINT | 46, VARINT_16 = VARINT | 47, VARINT_17 = VARINT | 48; byte VARINT_18 = VARINT | 49, VARINT_19 = VARINT | 50, VARINT_1A = VARINT | 51, VARINT_1B = VARINT | 52; byte VARINT_1C = VARINT | 53, VARINT_1D = VARINT | 54, VARINT_1E = VARINT | 55, VARINT_1F = VARINT | 56; // object tag byte OBJECT_REF = OBJECT | 1, OBJECT_STREAM = OBJECT | 2, OBJECT_BYTES = OBJECT | 3; byte OBJECT_VALUE = OBJECT | 4, OBJECT_VALUES = OBJECT | 5, OBJECT_MAP = OBJECT | 6; byte OBJECT_DESC = OBJECT | 10, OBJECT_DESC_ID = OBJECT | 11; // object constants byte OBJECT_NULL = OBJECT | 20, OBJECT_DUMMY = OBJECT | 21; }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
---
是不是有点一脸懵逼?!我们把枚举做一次规整,如下图所示:
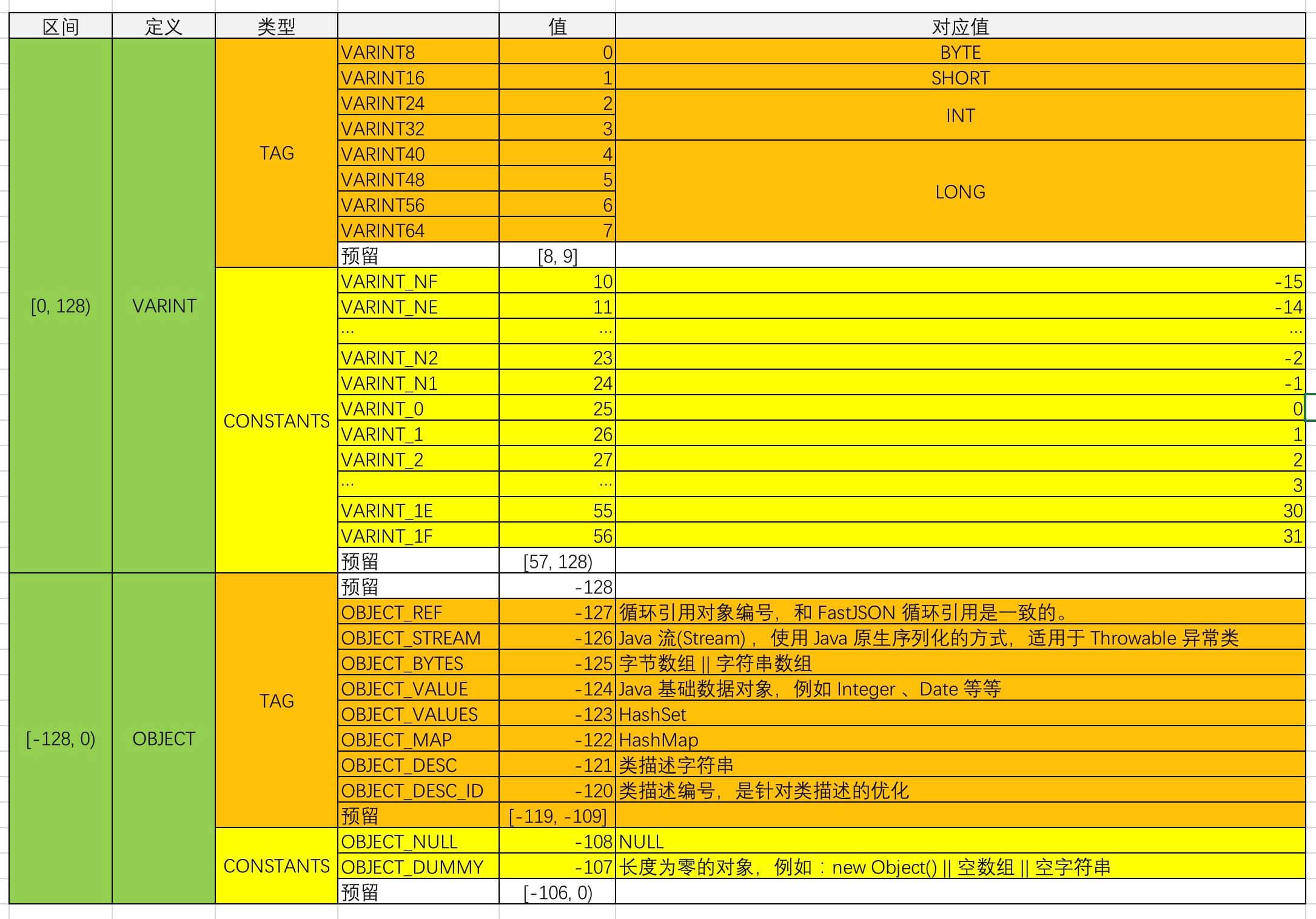
协议整理
- 在每个属性值( 即 field )的**首个 Byte 位标志位 Flag**
,称为
。目前我们分成两大类( 图中,绿色部分 ):
- Varint ,**变长数字**
,占用 Byte 值的
[0, 128)
区间。
- Object ,**对象**
,占用 Byte 值的
[-128, 0)
区间。
- 标志位 Flag 根据**用途类型不重叠**
,可以分成两种
(注意,值是
的):
- Tag ,**标签**
( 图中,橙色部分 )。
- 以 VarInt 举例子,**数字多少变长Long100LVARINT8100L**
分成 BYTE、SHORT、INT、LONG 四种数据类型。 通过标记位,表示数字占用
Byte ,从而实现
,节省 Byte 的占用。例如,属性值类型为
,但是值是
,那么只需要要 1 Byte( 标记位为
) + 1 Byte(
) = 2 Byte 。
- 当然,这种方式也有缺点,对于**大整数标记位小整数**
,会多占用一个
,例如
Integer.MAX_VALUE
。从统计上来说,业务系统更多的是
。所以,这个缺点也是能够接受的。
- CONSTANTS , **枚举常用**
( 图中,黄色部分 ),用于
属性值。
- 以 Varint 举例子,在业务系统中,**非常常用**
[ -15, 31 ]
是
。通过枚举,进一步减少数据提及,提升序列化速度。所以 Varint 的二进制数据流示意图如下:

二进制数据流
可能有胖友会问,上面只提到了数字怎么序列化,**那么对象怎么序列化呢**?我们以 POJO 为例子,简单说下。实际上,我们可以把对象理解成**一个属性值的集合**,通过下面会看到的 Builder 类,生成该对象的序列化和反序列化的过程的代码即可。
当然,对象不仅仅有 POJO ,还有 MAP,数组等等,下面我们都会看到具体的处理代码。
嗯,哔哔了这么多,让我们愉快的开始看代码把。
# 3. Data
## 3.1 GenericDataOutput
[com.alibaba.dubbo.common.serialize.support.dubbo.GenericDataOutput](https://github.com/YunaiV/dubbo/blob/master/dubbo-common/src/main/java/com/alibaba/dubbo/common/serialize/support/dubbo/GenericDataOutput.java) ,实现 DataOutput,GenericDataFlags 接口,Dubbo 数据输出实现类。
### 3.1.1 构造方法
```plain text
plain /** * 默认 {@link #mCharBuf} 大小 */ private static final int CHAR_BUF_SIZE = 256; /** * 序列化字符串的临时结果的 Buffer 数组,用于 {@link #writeUTF(String)} 中。 */ private final char[] mCharBuf = new char[CHAR_BUF_SIZE]; /** * 序列化 Varint 的临时结果的 Buffer 数组,用于 {@link #writeVarint32(int)} 和 {@link #writeVarint64(long)} 中。 */ private final byte[] mTemp = new byte[9]; /** * 序列化结果的 Buffer 数组 */ private final byte[] mBuffer; /** * {@link #mBuffer} 容量大小 */ private final int mLimit; /** * {@link #mBuffer} 当前写入位置 */ private int mPosition = 0; /** * 结果输出 */ private final OutputStream mOutput;
- mCharBuf字符串 属性,序列化 的临时结果的 Buffer 数组,用于 #writeUTF(String v) 方法中。
- #CHAR_BUF_SIZE静态 属性,默认大小。
- mTempVarint 属性,序列化 的临时结果的 Buffer 数组,用于 #writeVarint32(int) 和 #writeVarint64(long) 方法中。
- 数组大小为 9 ,因为 Varint 最大占用 9 字节,Tag( 1 Byte ) + Long( 8 Bytes ) 。
- mBuffer结果 属性,序列化 的 Buffer 数组。
- mPosition当前 属性, 写入位置。
- mLimit 属性,容量大小。
- mOutput 属性,结果输出, mBuffer => mOutput 中。
3.1.2 writeBool
```plain text plain @Override public void writeBool(boolean v) throws IOException { write0(v ? VARINT_1 : VARINT_0); }
1
2
3
4
5
6
7
8
9
10
11
12
13
---
- 通过 1 表示 TRUE ,0 表示 FALSE 。占用 1 Byte ,使用 **CONSTANTS**
( VARINT_1、VARINT_0 ) 即可。
- 调用
#write0(byte b)
方法,写入
mBuffer
中。代码如下:
```plain text
plain protected void write0(byte b) throws IOException { // 超过 mBuffer 容量上限,刷入 mOutput 中 if (mPosition == mLimit) { flushBuffer(); } // 写入 mBuffer 中。 mBuffer[mPosition++] = b; }
```plain text
- #flushBuffer() 方法,代码如下:
```
```plain text plain @Override public void flushBuffer() throws IOException { if (mPosition > 0) { // 写入 mOutput mOutput.write(mBuffer, 0, mPosition); // 重置当前写入位置 mPosition = 0; } }
1
2
3
4
5
6
7
---
### 3.1.3 writeByte
```plain text
plain 1: @Override 2: public void writeByte(byte v) throws IOException { 3: switch (v) { 4: // TODO 【8034】为什么没有负数的枚举 5: // 符合 Varint 枚举值,写入对应的枚举值 6: case 0: 7: write0(VARINT_0); 8: break; 9: // ... 省略中间,[1, 30] 重复的 case 处理 10: case 31: 11: write0(VARINT_1F); 12: break; 13: // 不符合 Varint 枚举值,写入 Tag + 具体值 14: default: 15: // 写入 VARINT8 16: write0(VARINT8); 17: // 写入 BYTE 具体值 18: write0(v); 19: } 20: }
- 第 4 行:// TODO 【8034】为什么没有负数的枚举
- 第 5 至 12 行:符合 Varint CONSTANTSCONSTANTS ,写入对应的 。
- 第 13 至 19 行:不符合 Varint CONSTANTS ,调用两次 VARINT8 #write0(byte b) 方法,写入
- 具体值 v 。
3.1.4 writeShort
```plain text plain @Override public void writeShort(short v) throws IOException { writeVarint32(v); }
1
2
3
4
5
6
7
8
9
---
- 调用
#writeVarint32(int v)
方法,写入。代码如下:
```plain text
plain 1: private void writeVarint32(int v) throws IOException { 2: switch (v) { 3: // 符合 Varint 枚举值,写入对应的枚举值 4: case -15: 5: write0(VARINT_NF); 6: break; 7: // ... 省略中间,[-14, 30] 重复的 case 处理 8: case 31: 9: write0(VARINT_1F); 10: break; 11: // 不符合 Varint 枚举值,写入 Tag + 具体值 12: default: 13: int t = v, // 值 14: ix = 0; // 当前写入位置 15: byte[] b = mTemp; 16: // 顺序读取字节,存到 mTemp 中 17: while (true) { 18: b[++ix] = (byte) (v & 0xff); // 大于等于 128 时,会截取到最高位的 1 ,变成负数。 19: if ((v >>>= 8) == 0) { // 无可读字节 20: break; 21: } 22: } 23: 24: if (t > 0) { // 正数 25: // [ 0a e2 => 0a e2 00 ] [ 92 => 92 00 ] 26: // 最后一次取余,大于等于 128 时,在 (byte) 转换后,变成了负数,需要补一个 0 的 BYTE 到 mTemp 中,否则反序列化后会被误认为负数。 27: if (b[ix] < 0) { 28: b[++ix] = 0; 29: } 30: } else { // 负数 31: // [ 01 ff ff ff => 01 ff ] [ e0 ff ff ff => e0 ] 32: // 负数使用补码表示,高位是大量的 1 ,需要去除。 33: // 另外,LONG 的位数比 INT 更多,所以,相同数字,LONG 型会比 INT 型更多,例如 long v = -662L 和 int v = -662 。 34: while (b[ix] == (byte) 0xff && b[ix - 1] < 0) { 35: ix--; 36: } 37: } 38: 39: // 写入 Tag ,到首 Byte 位 40: b[0] = (byte) (VARINT + ix - 1); 41: // 写入 Tag + Bytes 到 mBuffer 中 42: write0(b, 0, ix + 1); 43: } 44: }
- 第 5 至 12 行:符合 Varint CONSTANTSCONSTANTS ,写入对应的 。
- 第 11 至 43 行:不符合 Varint CONSTANTS ,写入 TAG
- 具体值 。
- 第 16 至 22 行:顺序循环每个字节 读取 ,存到 b 数组中。
- 第 18 行:先 一个字节(byte)高位截取反序列化高位的 1 0xff 做 %256 取余,获取到 。再 转换成 BYTE 值。因为,BYTE 数据范围为 [-128, 127] ,所以取余的结果为 [128, 255] 范围时,则会被 ,变成负数。例如,255 会变成 -1 。也因此, 时,需要做一次 0xff | 操作,来补齐 。
- 第 18 行:TAG b[++ix] ,先增加 ix 的值,在写入 b 数组中。因为,首 Byte 位为 。
- 第 19 至 21 行:无可读字节,结束循环。
- 第 24 至 29 行:最后一次取余,大于等于 128 时,在 (byte) 转换后,变成了负数,需要补一个 0 到 b 中,否则反序列化后会被误认为负数。例如: v = 255 。
- 第 30 至 37 行:负数使用补码表示,高位是大量的 1 ,需要循环 去除。另外,LONG 的位数比 INT 更多,所以,相同数字,LONG 型会比 INT 型更多,例如 long v = -662L 和 int v = -662 。示例如下:
- 第 16 至 22 行:顺序循环每个字节 读取 ,存到 b 数组中。
```plain text plain INT -110 -3 -1 -1 LONG -110 -3 -1 -1 -1 -1 -1 -1
1
2
3
4
5
6
7
8
---
```plain text
* <font style="color:rgb(51, 51, 51);">x</font>
- <font style="color:rgb(51, 51, 51);">涉及大量的</font>**<font style="color:rgb(51, 51, 51);">位操作</font>**<font style="color:rgb(51, 51, 51);">,不熟悉的胖友,请 Google 复习下大学课程。</font>
- <font style="color:rgb(51, 51, 51);">第 40 行:写入 </font>**<font style="color:rgb(51, 51, 51);">TAG</font>**<font style="color:rgb(51, 51, 51);"> ,到 </font><font style="color:rgb(51, 51, 51);">b</font><font style="color:rgb(51, 51, 51);"> 的首位。</font>
- <font style="color:rgb(51, 51, 51);">第 42 行:调用 </font><font style="color:rgb(51, 51, 51);">#write0(byte[] b, int off, int le)</font><font style="color:rgb(51, 51, 51);"> 方法,</font>**<font style="color:rgb(51, 51, 51);">批量</font>**<font style="color:rgb(51, 51, 51);">写入 </font><font style="color:rgb(51, 51, 51);">mBuffer</font><font style="color:rgb(51, 51, 51);"> 中。代码如下:</font>
```plain text plain protected void write0(byte[] b, int off, int len) throws IOException { int rem = mLimit - mPosition; // 未超过 mBuffer 容量上限,批量写入 mBuffer 中 if (rem > len) { System.arraycopy(b, off, mBuffer, mPosition, len); mPosition += len; } else { // 部分批量写满 mBuffer 中 System.arraycopy(b, off, mBuffer, mPosition, rem); mPosition = mLimit; // 刷入 mOutput 中 flushBuffer(); off += rem; // 新的开始位置 len -= rem; // 新的长度 // 未超过 mBuffer 容量上限,批量写入 mBuffer 中 if (mLimit > len) { System.arraycopy(b, off, mBuffer, 0, len); mPosition = len; // 超过 mBuffer 容量上限,批量写入 mOutput 中 } else { mOutput.write(b, off, len); } } }
1
2
3
4
5
6
7
---
### 3.1.5 writeInt
```plain text
plain @Override public void writeInt(int v) throws IOException { writeVarint32(v); }
3.1.6 writeLong
```plain text plain @Override public void writeInt(int v) throws IOException { writeVarint64(v); }
1
2
3
4
5
6
7
8
9
---
- 调用
#writeVarint64(long v)
方法,写入。代码如下:
```plain text
plain 1: private void writeVarint64(long v) throws IOException { 2: // 数据范围在 INT 内 3: int i = (int) v; 4: if (v == i) { 5: writeVarint32(i); 6: // 数据范围在 LONG 内,不符合 Varint 枚举值,写入 Tag + 具体值。和 writeVarint32 是一致的 7: } else { 8: long t = v; 9: int ix = 0; 10: byte[] b = mTemp; 11: 12: while (true) { 13: b[++ix] = (byte) (v & 0xff); 14: if ((v >>>= 8) == 0) 15: break; 16: } 17: 18: if (t > 0) { 19: // [ 0a e2 => 0a e2 00 ] [ 92 => 92 00 ] 20: if (b[ix] < 0) 21: b[++ix] = 0; 22: } else { 23: // [ 01 ff ff ff => 01 ff ] [ e0 ff ff ff => e0 ] 24: while (b[ix] == (byte) 0xff && b[ix - 1] < 0) 25: ix--; 26: } 27: 28: b[0] = (byte) (VARINT + ix - 1); 29: write0(b, 0, ix + 1); 30: } 31: }
- 第 2 至 5 行:当 v 数据范围在 INT 内时,调用 #writeVarint32(int v) 处理。
- 第 7 至 30 行:当 CONSTANTSTAG后半段 v 数据范围在 LONG 内时, 不符合 Varint ,写入
- 具体值,和 #writeVarint32(int v) 的代码是一致的。
3.1.7 writeFloat
```plain text plain @Override public void writeFloat(float v) throws IOException { writeVarint32(Float.floatToRawIntBits(v)); }
1
2
3
4
5
6
7
---
### 3.1.8 writeDouble
```plain text
plain @Override public void writeDouble(double v) throws IOException { writeVarint64(Double.doubleToRawLongBits(v)); }
3.1.9 writeUInt
```plain text plain public void writeUInt(int v) throws IOException { byte tmp; // 循环写入 while (true) { // 获得最后 7 Bits tmp = (byte) (v & 0x7f); // 无后续的 Byte ,修改 tmp 首 Bit 为 1 ,写入 mBuffer 中,并结束。 if ((v »>= 7) == 0) { write0((byte) (tmp | 0x80)); return; // 有后续的 Byte ,写入 mBuffer 中 } else { write0(tmp); } } }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
---
- UInt ,Unsingned Int ,无符号整数( **正数变长数字不同正整数Byte 最高位的 1后续的 BYTE**
)。被用于表示字符串、数组的长度。序列化时,和上文我们看到的 Varint 一样,也是
,但是方式
。因为是
,所以可以使用
,原来用来表示负数,现在来表示是否有
,也是正整数的一部分。
- 代码已经添加注释,胖友自己看看哈。
- 推荐阅读 [《数值压缩存储方法Varint》](https://www.cnblogs.com/smark/archive/2012/05/03/2480034.html)**Zag 算法不同**[《 Protocol Buffer 序列化原理大揭秘 - 为什么Protocol Buffer性能这么好?》](https://blog.csdn.net/carson_ho/article/details/70568606)
,里面 Varint 和 UInt 一样采用最高位来表示是否有后续数字,但是更加强大通用,使用
解决负数问题,在 Protobuf 中采用该方式。 文章中的 Varint 和本文我们看到的 Varint
。如果胖友对 Protobuf 的实现感兴趣,推荐阅读
。
### 3.1.10 writeBytes
```plain text
plain 1: @Override 2: public void writeBytes(byte[] b) throws IOException { 3: // NULL ,使用 OBJECT_NULL 写入 mBuffer 4: if (b == null) { 5: write0(OBJECT_NULL); 6: // 其他,写入 mBuffer 7: } else { 8: writeBytes(b, 0, b.length); 9: } 10: } 11: 12: @Override 13: public void writeBytes(byte[] b, int off, int len) throws IOException { 14: // 空数组,使用 OBJECT_DUMMY 写入 mBuffer 15: if (len == 0) { 16: write0(OBJECT_DUMMY); 17: // 数组非空,写入 OBJECT_BYTES + Length + 具体数据到 mBuffer 18: } else { 19: write0(OBJECT_BYTES); 20: writeUInt(len); // UInt 21: write0(b, off, len); 22: } 23: }
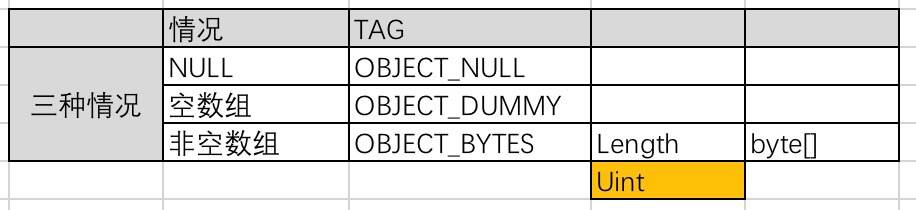
writeBytes
3.1.11 writeUTF
```plain text plain 1: @Override 2: public void writeUTF(String v) throws IOException { 3: // NULL ,使用 OBJECT_NULL 写入 mBuffer 4: if (v == null) { 5: write0(OBJECT_NULL); 6: } else { 7: // 空字符串,使用 OBJECT_DUMMY 写入 mBuffer 8: int len = v.length(); 9: if (len == 0) { 10: write0(OBJECT_DUMMY); 11: // 字符串非空,写入 OBJECT_BYTES + Length + 具体数据到 mBuffer 12: } else { 13: // 写入 OBJECT_BYTES 到 mBuffer 中 14: write0(OBJECT_BYTES); 15: // 写入 Length 到 mBuffer 中 16: writeUInt(len); 17: 18: int off = 0, 19: limit = mLimit - 3, // -3 的原因,因为若 Char 在 [2048, 65536) 范围内,需要占用三个字节,事先无法得知。 20: size; 21: char[] buf = mCharBuf; 22: do { 23: // 读取数量,不超过 CHAR_BUF_SIZE 上限,同时不超过可读上限 24: size = Math.min(len - off, CHAR_BUF_SIZE); 25: // 读取字符串到 buf 中 26: v.getChars(off, off + size, buf, 0); 27: 28: // 写入数据到 mBuffer 中 29: for (int i = 0; i < size; i++) { 30: char c = buf[i]; 31: // Java Character 数据范围为 [0, 65535] 32: if (mPosition > limit) { 33: if (c < 0x80) { // [0, 128) ASCII 码 34: // 0X80 => 10 00 00 00 取七位 [0, 64) 35: 36: write0((byte) c); 37: } else if (c < 0x800) { // [128, 2048) 38: // 0xC0 => 11 00 00 00 取六位 [0, 32) 39: // 0x80 => 10 00 00 00 取七位 [0, 64) 40: 41: // 0x1F => 00 01 11 11 42: // 0x3F => 00 11 11 11 43: 44: write0((byte) (0xC0 | ((c » 6) & 0x1F))); 45: write0((byte) (0x80 | (c & 0x3F))); 46: } else { // [2048, 65536) 47: // 0xE0 => 11 10 00 00 取五位 [0, 15] 48: // 0x80 => 10 00 00 00 取七位 [0, 63] 49: // 0x80 => 10 00 00 00 取七位 [0, 63] 50: 51: // 0x0F => 00 00 11 11 52: // 0x3F => 00 11 11 11 53: // 0x3F => 00 11 11 11 54: 55: write0((byte) (0xE0 | ((c » 12) & 0x0F))); 56: write0((byte) (0x80 | ((c » 6) & 0x3F))); 57: write0((byte) (0x80 | (c & 0x3F))); 58: } 59: } else { 60: if (c < 0x80) { 61: mBuffer[mPosition++] = (byte) c; 62: } else if (c < 0x800) { 63: mBuffer[mPosition++] = (byte) (0xC0 | ((c » 6) & 0x1F)); 64: mBuffer[mPosition++] = (byte) (0x80 | (c & 0x3F)); 65: } else { 66: mBuffer[mPosition++] = (byte) (0xE0 | ((c » 12) & 0x0F)); 67: mBuffer[mPosition++] = (byte) (0x80 | ((c » 6) & 0x3F)); 68: mBuffer[mPosition++] = (byte) (0x80 | (c & 0x3F)); 69: } 70: } 71: } 72: 73: // 计算 buf 新的开始读取位置。 74: off += size; 75: } while (off < len); 76: } 77: } 78: }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
---
- 字符串和字节数组,**二进制数据流每个字符**
的结构是一致的,差异点在字符串的
,写入到
mBuffer
中,即【第 18 至 75 行】。
- 第 19 行:**字符三个一致一个判断两段**
- 3
的原因,因为每个
最多需要占用
字节,事先无法得知。而【第 32 至 58 行】和【第 59 至 69 行】,逻辑上是
的,相比来说【第 32 至 58 行】的
#write0(byte b)
方法,多
,考虑到性能,就分成了
的逻辑,也就因此,多了这里的
- 3
。
- 第 22 至 25 行:**循环多次重用**
读取字符到
buf
中。因为每次读取有
CHAR_BUF_SIZE
最大限制,所以超过时,需要
读取。读取完一批,处理完一批,不断
buf
数组。
- 第 28 至 71 行:写入 **CharacterBYTE三种**
buf
到
mBuffer
中。因为 Java
的数据范围为
[0, 65535]
,超过
上限。所以写入每个字符时,分成
情况:
- 第 33 至 36 行:
[0, 128)
,占用一个字符。取七位,2 的 七次方为 128 ,从而满足数据范围。
- 第 37 至 45 行:
[128, 2048)
,占用两个字符。取六位、七位,2 的十三次方为 2048 ,从而满足数据范围。
- 第 46 至 58 行:
[2048, 65536)
,占用三个字符。取五位、七位、七位,2 的十九次方为 65536 ,从而满足数据范围。
- **为什么首位取的不同的位数呢高位这是一种针对当前场景实现的变长整数**
?在反序列化时,可以根据首位数的
来判断,到底完整的字符,占用了几个字节。 或者,我们可以理解成,
。
- 第 74 行:计算 **读取**
buf
新的开始
位置。
## 3.2 GenericDataInput
[com.alibaba.dubbo.common.serialize.support.dubbo.GenericDataInput](https://github.com/YunaiV/dubbo/blob/master/dubbo-common/src/main/java/com/alibaba/dubbo/common/serialize/support/dubbo/GenericDataInput.java) ,实现 DataInput,GenericDataFlags 接口,Dubbo 数据输入实现类。
### 3.2.1 构造方法
```plain text
plain /** * 空字符串 */ private static final String EMPTY_STRING = ""; /** * 空字节数组 */ private static final byte[] EMPTY_BYTES = {}; /** * 输入流 */ private final InputStream mInput; /** * 读取 Buffer 数组 */ private final byte[] mBuffer; /** * {@link #mBuffer} 当前读取位置 */ private int mRead = 0; /** * {@link #mBuffer} 最大可读取位置 */ private int mPosition = 0; public GenericDataInput(InputStream is) { this(is, 1024); } public GenericDataInput(InputStream is, int buffSize) { mInput = is; mBuffer = new byte[buffSize]; }
- mBuffer 属性,读取 Buffer 数组。
- mRead 属性,当前读取位置。
- mPosition 属性,最大可读取位置。
- mInput 属性,输入流。
3.2.2 readBool
```plain text plain @Override public boolean readBool() throws IOException { // 读取字节 byte b = read0(); // 判断 true / false switch (b) { case VARINT_0: // false return false; case VARINT_1: // true return true; default: // 非法 throw new IOException(“Tag error, expect BYTE_TRUE|BYTE_FALSE, but get “ + b); } }
1
2
3
4
5
6
7
8
9
---
- 调用
#read0()
方法,读取字节。代码如下:
```plain text
plain protected byte read0() throws IOException { // 读取到达上限,从 mInput 读取到 mBuffer 中。 if (mPosition == mRead) { fillBuffer(); } // 从 mBuffer 中,读取字节。 return mBuffer[mPosition++]; }
```plain text
- #fillBuffer() 方法,代码如下:
```
```plain text plain private void fillBuffer() throws IOException { // 重置 mPosition mPosition = 0; // 读取 mInput 到 mBuffer 中 mRead = mInput.read(mBuffer); // 未读取到,抛出 EOFException 异常 if (mRead == -1) { mRead = 0; throw new EOFException(); } }
1
2
3
4
5
6
7
---
### 3.2.3 readByte
```plain text
plain 1: @Override 2: public byte readByte() throws IOException { 3: // 读取字节 4: byte b = read0(); 5: switch (b) { 6: // 不符合 Varint 枚举值,读取字节返回 7: case VARINT8: 8: return read0(); 9: // 符合 Varint 枚举值,返回对应的值 10: case VARINT_0: 11: return 0; 12: // ... 省略中间,[1, 30] 重复的 case 处理 13: case VARINT_1F: 14: return 31; 15: default: // 非法,抛出 IOException 异常 16: throw new IOException("Tag error, expect VARINT, but get " + b); 17: } 18: }
- 第 4 行:调用 #read0() 方法,读取字节。
- 第 6 至 8 行:不符合 Varint CONSTANTS ,调用 #read0() 方法,读取字节返回。
- 第 9 至 14 行:符合 Varint CONSTANTS,返回对应的值。
3.2.4 readShort
```plain text plain @Override public short readShort() throws IOException { return (short) readVarint32(); }
1
2
3
4
5
6
7
8
9
---
- 调用
#readVarint32()
方法,读取。代码如下:
```plain text
plain 1: private int readVarint32() throws IOException { 2: // 读取首位 Byte 字节 3: byte b = read0(); 4: // 5: switch (b) { 6: // 不符合 Varint 枚举值,读取 Tag + 具体值 7: case VARINT8: 8: return read0(); 9: case VARINT16: { 10: byte b1 = read0(), b2 = read0(); 11: return (short) ((b1 & 0xff) | 12: ((b2 & 0xff) << 8)); 13: } 14: case VARINT24: { 15: byte b1 = read0(), b2 = read0(), b3 = read0(); 16: int ret = (b1 & 0xff) | 17: ((b2 & 0xff) << 8) | 18: ((b3 & 0xff) << 16); 19: if (b3 < 0) { // 补齐负数的高位 20: return ret | 0xff000000; 21: } 22: return ret; 23: } 24: case VARINT32: { 25: byte b1 = read0(), b2 = read0(), b3 = read0(), b4 = read0(); 26: return ((b1 & 0xff) | 27: ((b2 & 0xff) << 8) | 28: ((b3 & 0xff) << 16) | 29: ((b4 & 0xff) << 24)); 30: } 31: // 符合 Varint 枚举值,返回对应的值 32: case VARINT_NF: 33: return -15; 34: // ... 省略中间,[-14, 30] 重复的 case 处理 35: case VARINT_1F: 36: return 31; 37: default: 38: throw new IOException("Tag error, expect VARINT, but get " + b); 39: } 40: }
- 第 3 行:调用 首位 #read0() 方法,读取 Byte 字节。
- 第 6 至 30 行:不符合 Varint CONSTANTSTAG ,读取
- 具体值。
- & 0xff被截取最高的 1原数 操作,补回 ,从而恢复 ,对应 #writeVarint32(int v) 方法的【第 18 位】。
- | 0xff000000高位 操作,补齐负数的 ,对应 #writeVarint32(int v) 方法的【第 30 至 36 位】。
- 第 31 至 36 行:符合 Varint CONSTANTS ,返回对应的值。
3.2.5 readInt
```plain text plain @Override public int readInt() throws IOException { return readVarint32(); }
1
2
3
4
5
6
7
---
### 3.2.6 readLong
```plain text
plain @Override public long readLong() throws IOException { return readVarint64(); }
- #readVarint64() 和 #readVarint32() 基本一致,胖友自己查看。
3.2.7 readFloat
```plain text plain @Override public float readFloat() throws IOException { return Float.intBitsToFloat(readVarint32()); }
1
2
3
4
5
6
7
---
### 3.2.8 readDouble
```plain text
plain @Override public double readDouble() throws IOException { return Double.longBitsToDouble(readVarint64()); }
3.2.9 readUInt
```plain text plain public int readUInt() throws IOException { // 读取字节 byte tmp = read0(); // 用于暂存当前读取结果 // 【第一次】 if (tmp < 0) { // 负数,意味着无后续 return tmp & 0x7f; } int ret = tmp & 0x7f; // 最终结果 // 【第二次】 if ((tmp = read0()) < 0) { // 负数,意味着无后续 ret |= (tmp & 0x7f) « 7; // 拼接 tmp + ret } else { ret |= tmp « 7; // 【第三次】 if ((tmp = read0()) < 0) { // 负数,意味着无后续 ret |= (tmp & 0x7f) « 14; } else { ret |= tmp « 14; // 【第四次】 if ((tmp = read0()) < 0) { // 负数,意味着无后续 ret |= (tmp & 0x7f) « 21; // 【第五次】5 * 7 > 32 ,所以可以结束 } else { ret |= tmp « 21; ret |= (read0() & 0x7f) « 28; } } } return ret; }
1
2
3
4
5
6
7
---
### 3.2.10 readBytes
```plain text
plain @Override public byte[] readBytes() throws IOException { // 读取字节 byte b = read0(); switch (b) { case OBJECT_BYTES: // 数组非空 return read0(readUInt()); case OBJECT_NULL: // NULL return null; case OBJECT_DUMMY: // 数组为空 return EMPTY_BYTES; default: throw new IOException("Tag error, expect BYTES|BYTES_NULL|BYTES_EMPTY, but get " + b); } }
- #read0(int len) 方法,批量读取字节。代码如下:
```plain text plain protected byte[] read0(int len) throws IOException { int rem = mRead - mPosition; byte[] ret = new byte[len]; // 未超过 mBuffer 剩余可读取,批量写入 mBuffer 中。mBuffer => ret if (len <= rem) { System.arraycopy(mBuffer, mPosition, ret, 0, len); mPosition += len; } else { // 部分批量写入 ref 中。mBuffer => ret System.arraycopy(mBuffer, mPosition, ret, 0, rem); mPosition = mRead; len -= rem; int read, pos = rem; // 新的 ret 读取起点 // mInput => ret while (len > 0) { read = mInput.read(ret, pos, len); if (read == -1) { throw new EOFException(); } pos += read; // 新的 ret 读取起点 len -= read; } } return ret; }
1
2
3
4
5
6
7
---
### 3.2.11 readUTF
```plain text
plain 1: @Override 2: public String readUTF() throws IOException { 3: // 读取字节 4: byte b = read0(); 5: switch (b) { 6: // 字符串非空 7: case OBJECT_BYTES: 8: // 读取长度 9: int len = readUInt(); 10: // 反序列化出字符串 11: StringBuilder sb = new StringBuilder(); 12: for (int i = 0; i < len; i++) { 13: // 读取首位 14: byte b1 = read0(); 15: if ((b1 & 0x80) == 0) { // [0, 128) ASCII 码 16: sb.append((char) b1); 17: } else if ((b1 & 0xE0) == 0xC0) { // [128, 2048) 18: byte b2 = read0(); 19: sb.append((char) (((b1 & 0x1F) << 6) | (b2 & 0x3F))); 20: } else if ((b1 & 0xF0) == 0xE0) { // [2048, 65536) 21: byte b2 = read0(), b3 = read0(); 22: sb.append((char) (((b1 & 0x0F) << 12) | ((b2 & 0x3F) << 6) | (b3 & 0x3F))); 23: } else 24: throw new UTFDataFormatException("Bad utf-8 encoding at " + b1); 25: } 26: return sb.toString(); 27: // NULL 28: case OBJECT_NULL: 29: return null; 30: // 字符串为空 31: case OBJECT_DUMMY: 32: return EMPTY_STRING; 33: default: 34: throw new IOException("Tag error, expect BYTES|BYTES_NULL|BYTES_EMPTY, but get " + b); 35: } 36: }
- 第 13 至 25 行:反序列化每个字符高位 ,通过首位数的 来判断,到底完整的字符,占用了几个字节:
- 第 15 至 16 行:数据范围是 [0, 128) ,最大数 127 的二进制为 01 11 11 11 ,使用 & 0x80 运算后,会等于 0 。
- 第 17 至 19 行:数据范围是 [128, 2048) ,因为首位数取六位,并且使用 0xC0 | 运算后,所以二进制为 11 XX XX XX ,使用 & 0xE0 运算后,会等于 0XC0 。
- 【第 15 至 16 行】如果使用 & 0x80 运算, 不会等于 0 ,不符合要求。
- 第 20 至 22 行:数据范围是 [2048, 65536) ,因为首位数取五位,并且使用 0xE0 | 运算后,所以二进制为 11 1X XX XX ,使用 & 0xF0 运算后,会等于 0xE0 。
- 【第 15 至 16 行】如果使用 & 0x80 运算, 不会等于 0 ,不符合要求。
- 【第 17 至 19 行】如果使用 & 0xE0 运算,不会等于 0xC0 ,不符合要求。
- 【第 15 至 16 行】如果使用 & 0x80 运算, 不会等于 0 ,不符合要求。
4. Object
4.1 GenericObjectOutput
com.alibaba.dubbo.common.serialize.support.dubbo.GenericObjectOutput ,实现 ObjectOutput 接口,继承 GenericObjectOutput 类,Dubbo 对象输出实现类。
4.1.1 构造方法
```plain text plain /** * 对象是否允许不实现 {@link java.io.Serializable} 接口 */ private final boolean isAllowNonSerializable; /** * 类描述匹配器 */ private ClassDescriptorMapper mMapper; /** * 循环引用集合 * * KEY :对象 * VALUE :引用编号 */ private Map<Object, Integer> mRefs = new ConcurrentHashMap<Object, Integer>();
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
---
- isAllowNonSerializable**不允许**
属性,对象是否允许不实现 Serializable 接口。Dubbo 序列化无需强制实现 Serializable 接口。考虑到通用性,默认
false
。
- mMapper**注册DEFAULT_CLASS_DESCRIPTOR_MAPPER**
属性,类描述匹配器。通过该匹配器,可以将类描述,转换成对应的描述编号,从而加速序列化的速度,减少体积,类似 Kryo 的
。默认使用 Builder 的
实现类。
- mRefs[《循环引用》](https://github.com/alibaba/fastjson/wiki/%E5%BE%AA%E7%8E%AF%E5%BC%95%E7%94%A8)**循环引用**
属性,循环引用集合,和 FastJSON 的
上,概念是一致的。在 AbstractObjectBuilder 中,我们会看到
的实现。
### 4.1.2 writeObject
```plain text
plain 1: @Override 2: @SuppressWarnings({"unchecked", "rawtypes"}) 3: public void writeObject(Object obj) throws IOException { 4: // NULL ,使用 OBJECT_NULL 写入 mBuffer 5: if (obj == null) { 6: write0(OBJECT_NULL); 7: return; 8: } 9: // 空对象,使用 OBJECT_DUMMY 写入 mBuffer 10: Class<?> c = obj.getClass(); 11: if (c == Object.class) { 12: write0(OBJECT_DUMMY); 13: } else { 14: // 获得类描述 15: String desc = ReflectUtils.getDesc(c); 16: // 查询类描述编号 17: int index = mMapper.getDescriptorIndex(desc); 18: // 不存在,使用 OBJECT_DESC + 类描述 写入 mBuffer 19: if (index < 0) { 20: write0(OBJECT_DESC); 21: writeUTF(desc); 22: // 存在,使用 OBJECT_DESC_ID + 类描述编号 写入 mBuffer 23: } else { 24: write0(OBJECT_DESC_ID); 25: writeUInt(index); 26: } 27: // 获得类对应的序列化 Builder 28: Builder b = Builder.register(c, isAllowNonSerializable); 29: // 序列化到 mBuffer 中 30: b.writeTo(obj, this); 31: } 32: }
- 【第一种】第 4 至 8 行:对象为 NULL ,写入 OBJECT_NULL 到 mBuffer 。
- 【第二种】第 9 至 12 行:对象为 Object 类型,写入 OBJECT_DUMMY 到 mBuffer 。
- 【第三种】第 13 至 30 行:对象非空,写入 类描述 + 对象 到 mBuffer 。
- 第 15 行:调用 ReflectUtils#getDesc(c) 方法,获得类描述。代码如下:
```plain text plain public static String getDesc(Class<?> c) { StringBuilder ret = new StringBuilder(); // Array while (c.isArray()) { ret.append(‘[’); c = c.getComponentType(); } // 基本类型 if (c.isPrimitive()) { String t = c.getName(); if (“void”.equals(t)) ret.append(JVM_VOID); else if (“boolean”.equals(t)) ret.append(JVM_BOOLEAN); else if (“byte”.equals(t)) ret.append(JVM_BYTE); else if (“char”.equals(t)) ret.append(JVM_CHAR); else if (“double”.equals(t)) ret.append(JVM_DOUBLE); else if (“float”.equals(t)) ret.append(JVM_FLOAT); else if (“int”.equals(t)) ret.append(JVM_INT); else if (“long”.equals(t)) ret.append(JVM_LONG); else if (“short”.equals(t)) ret.append(JVM_SHORT); // 类 } else { ret.append(‘L’); ret.append(c.getName().replace(‘.’, ‘/’)); ret.append(‘;’); } return ret.toString(); }
1
2
3
4
5
6
7
8
9
10
11
---
```plain text
* <font style="color:rgb(51, 51, 51);">x</font>
- <font style="color:rgb(51, 51, 51);">第 17 行:调用 </font><font style="color:rgb(51, 51, 51);">ClassDescriptorMapper#getDescriptorIndex(desc)</font><font style="color:rgb(51, 51, 51);"> 方法,获得类描述</font>**<font style="color:rgb(51, 51, 51);">编号</font>**<font style="color:rgb(51, 51, 51);">。</font>
* <font style="color:rgb(51, 51, 51);">【不存在】第18 至 21 行:写入 </font>**<font style="color:rgb(51, 51, 51);">OBJECT_DESC</font>**<font style="color:rgb(51, 51, 51);"> + </font>**<font style="color:rgb(51, 51, 51);">类描述</font>**<font style="color:rgb(51, 51, 51);">(字符串) 到 </font><font style="color:rgb(51, 51, 51);">mBuffer</font><font style="color:rgb(51, 51, 51);"> 中。</font>
* <font style="color:rgb(51, 51, 51);">【已存在】第 22 至 26 行:写入 </font>**<font style="color:rgb(51, 51, 51);">OBJECT_DESC_ID</font>**<font style="color:rgb(51, 51, 51);"> + </font>**<font style="color:rgb(51, 51, 51);">类描述编号</font>**<font style="color:rgb(51, 51, 51);">(编号) 到 </font><font style="color:rgb(51, 51, 51);">mBuffer</font><font style="color:rgb(51, 51, 51);"> 中。</font>
* <font style="color:rgb(51, 51, 51);"> 很明显,第二种的性能和体积都更好。当然,需要保证 Server 和 Client 的类描述编号是一致的。大多数情况下,我们只注册</font>**<font style="color:rgb(51, 51, 51);">常用</font>**<font style="color:rgb(51, 51, 51);">的数据类型到 ClassDescriptorMapper 中。</font>
- <font style="color:rgb(51, 51, 51);">第 28 行:调用 </font><font style="color:rgb(51, 51, 51);">Builder#register(Class<T> c, boolean isAllowNonSerializable)</font><font style="color:rgb(51, 51, 51);"> 方法,获得类</font>**<font style="color:rgb(51, 51, 51);">对应</font>**<font style="color:rgb(51, 51, 51);">的 Builder 对象。</font>
- <font style="color:rgb(51, 51, 51);">第 30 行:调用 </font><font style="color:rgb(51, 51, 51);">Builder#writeToT obj, GenericObjectOutput out)</font><font style="color:rgb(51, 51, 51);"> 方法,</font>**<font style="color:rgb(51, 51, 51);">序列化</font>**<font style="color:rgb(51, 51, 51);">对象到 GenericObjectOutput 中的输出流。</font>**<font style="color:rgb(51, 51, 51);">为什么可以这么做</font>**<font style="color:rgb(51, 51, 51);">?看完 </font>[「6. Builder」](http://svip.iocoder.cn/Dubbo/serialize-2-dubbo/#)<font style="color:rgb(51, 51, 51);"> 的分享,胖友就会找到答案。 卖个小关子。</font>
4.1.3 addRef
```plain text plain /** * 添加循环引用 * * @param obj 对象 */ public void addRef(Object obj) { mRefs.put(obj, mRefs.size() /** 引用编号 **/ ); }
1
2
3
4
5
6
7
---
### 4.1.4 getRef
```plain text
plain /** * 获得循环引用编号 * * @param obj 对象 * @return 引用编号 */ public int getRef(Object obj) { Integer ref = mRefs.get(obj); if (ref == null) { return -1; } return ref; }
4.2 GenericObjectInput
com.alibaba.dubbo.common.serialize.support.dubbo.GenericObjectInput ,实现 ObjectInput 接口,继承 GenericDataInput 类,Dubbo 对象输入实现类。
4.2.1 构造方法
```plain text plain /** * {@link #skipAny()} 空对象 */ private static Object SKIPPED_OBJECT = new Object(); /** * 类描述匹配器 */ private ClassDescriptorMapper mMapper; /** * 循环引用数组 */ private List
1
2
3
4
5
6
7
---
### 4.2.2 readObject
```plain text
plain 1: @Override 2: public Object readObject() throws IOException { 3: String desc; 4: // 读取字节 5: byte b = read0(); 6: switch (b) { 7: case OBJECT_NULL: // NULL 8: return null; 9: case OBJECT_DUMMY: // 空对象 10: return new Object(); 11: case OBJECT_DESC: { // 类描述 12: desc = readUTF(); 13: break; 14: } 15: case OBJECT_DESC_ID: { // 类描述编号 16: // 读取类描述编号 17: int index = readUInt(); 18: // 获得类描述 19: desc = mMapper.getDescriptor(index); 20: if (desc == null) { 21: throw new IOException("Can not find desc id: " + index); 22: } 23: break; 24: } 25: default: 26: throw new IOException("Flag error, expect OBJECT_NULL|OBJECT_DUMMY|OBJECT_DESC|OBJECT_DESC_ID, get " + b); 27: } 28: try { 29: // 获得类 30: Class<?> c = ReflectUtils.desc2class(desc); 31: // 获得类对应的序列化 Builder 32: // 反序列化成对象返回 33: return Builder.register(c).parseFrom(this); 34: } catch (ClassNotFoundException e) { 35: throw new IOException("Read object failed, class not found. " + StringUtils.toString(e)); 36: } 37: }
- 第 30 行:调用 ReflectUtils#desc2class(desc) 方法,获得类。
- 第 33 行:调用 对应 Builder#register(Class c, boolean isAllowNonSerializable) 方法,获得类 的 Builder 对象。
- 第 33 行:调用 对象 Builder#parseFrom(GenericObjectInput) 方法,反序列化成 返回。
4.2.3 addRef
```plain text plain /** * 添加循环引用 * * @param obj 对象 */ public void addRef(Object obj) { mRefs.add(obj); }
1
2
3
4
5
6
7
---
### 4.2.4 getRef
```plain text
plain /** * 获得循环引用 * * @param index 引用编号 * @return 对象 * @throws IOException 当发生 IO 异常时 */ public Object getRef(int index) throws IOException { if (index < 0 || index >= mRefs.size()) { return null; } // 获得对象 Object ret = mRefs.get(index); // 在 skyAny() 设置 if (ret == SKIPPED_OBJECT) { throw new IOException("Ref skipped-object."); } return ret; }
4.2.5 skipAny
【TODO 8035】1、已经限制的大小,这块代码没用了啊?!
胖友可先无视这个方法。
5. ClassDescriptorMapper
com.alibaba.dubbo.common.serialize.support.dubbo.ClassDescriptorMapper ,类描述匹配器接口。方法如下:
```plain text plain // 根据类描述编号,获得类描述 String getDescriptor(int index); // 根据类描述,获得类描述编号 int getDescriptorIndex(String desc);
1
2
3
4
5
6
7
8
9
---
## 5.1 DEFAULT_CLASS_DESCRIPTOR_MAPPER
DEFAULT_CLASS_DESCRIPTOR_MAPPER 是 Builder 的内部属性。
```plain text
plain /** * 类描述数组 */ private static final List<String> mDescList = new ArrayList<String>(); /** * 类描述映射 */ private static final Map<String, Integer> mDescMap = new ConcurrentHashMap<String, Integer>(); /** * ClassDescriptorMapper 默认实现类 */ public static ClassDescriptorMapper DEFAULT_CLASS_DESCRIPTOR_MAPPER = new ClassDescriptorMapper() { @Override public String getDescriptor(int index) { if (index < 0 || index >= mDescList.size()) { return null; } return mDescList.get(index); } @Override public int getDescriptorIndex(String desc) { Integer ret = mDescMap.get(desc); return ret == null ? -1 : ret; } };
在 Builder 的 static 代码块,会初始化 mDescMap 属性,代码如下:
```plain text plain static { addDesc(boolean[].class); addDesc(byte[].class); addDesc(char[].class); addDesc(short[].class); addDesc(int[].class); addDesc(long[].class); addDesc(float[].class); addDesc(double[].class); addDesc(Boolean.class); addDesc(Byte.class); addDesc(Character.class); addDesc(Short.class); addDesc(Integer.class); addDesc(Long.class); addDesc(Float.class); addDesc(Double.class); addDesc(String.class); addDesc(String[].class); addDesc(ArrayList.class); addDesc(HashMap.class); addDesc(HashSet.class); addDesc(Date.class); addDesc(java.sql.Date.class); addDesc(java.sql.Time.class); addDesc(java.sql.Timestamp.class); addDesc(java.util.LinkedList.class); addDesc(java.util.LinkedHashMap.class); addDesc(java.util.LinkedHashSet.class); // … 省略无关代码 } private static void addDesc(Class<?> c) { String desc = ReflectUtils.getDesc(c); // 例如,java.lang.Byte 为 Ljava/lang/Byte; // 添加到集合中 int index = mDescList.size(); mDescList.add(desc); mDescMap.put(desc, index); }
1
2
3
4
5
6
7
8
9
10
11
---
# 6. Builder
[com.alibaba.dubbo.common.serialize.support.dubbo.Builder](https://github.com/YunaiV/dubbo/blob/master/dubbo-common/src/main/java/com/alibaba/dubbo/common/serialize/support/dubbo/Builder.java) ,实现 GenericDataFlags 接口,对象序列化代码构建器**抽象类**。功能如下:
```plain text
1. <font style="color:rgb(51, 51, 51);">类的序列化和反序列化的</font>**<font style="color:rgb(51, 51, 51);">抽象定义</font>**<font style="color:rgb(51, 51, 51);">。</font>
1. <font style="color:rgb(51, 51, 51);">提供</font>**<font style="color:rgb(51, 51, 51);">常用类</font>**<font style="color:rgb(51, 51, 51);">( 例如 Integer 、Long 、Map 等等 )的 Builder 实现类。</font>
1. <font style="color:rgb(51, 51, 51);">基于 </font>**<font style="color:rgb(51, 51, 51);">Javassist</font>**<font style="color:rgb(51, 51, 51);"> 自动实现</font>**<font style="color:rgb(51, 51, 51);">自定义类</font>**<font style="color:rgb(51, 51, 51);">( 例如 User 、Student 等等 )的 Builder 实现类。</font>
大体的类结构,如下图所示:
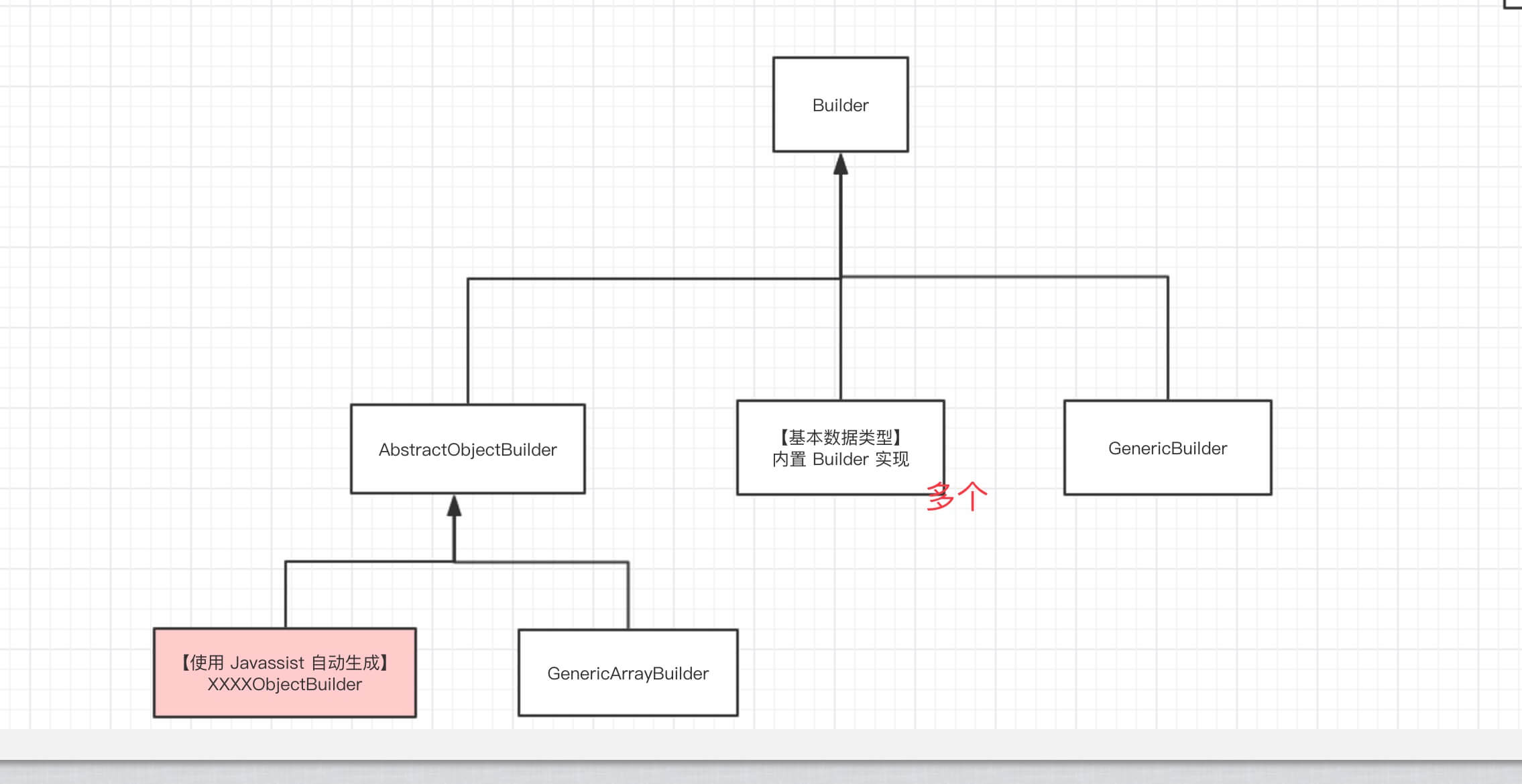
类图
6.1 抽象方法
```plain text plain /** * @return Builder 对应的类 */ abstract public Class
1
2
3
4
5
6
7
8
9
10
11
12
13
---
**三个**抽象方法:
- 对应类
- 序列化
- 反序列化
## 6.2 register
```plain text
plain /** * 实现 Serializable 接口的类的 Builder 对象缓存 */ private static final Map<Class<?>, Builder<?>> BuilderMap = new ConcurrentHashMap<Class<?>, Builder<?>>(); /** * 未实现 Serializable 接口的类的 Builder 对象缓存 */ private static final Map<Class<?>, Builder<?>> nonSerializableBuilderMap = new ConcurrentHashMap<Class<?>, Builder<?>>(); 1: public static <T> Builder<T> register(Class<T> c, boolean isAllowNonSerializable) { 2: // Object 类,或者接口,使用 GenericBuilder 3: if (c == Object.class || c.isInterface()) { 4: return (Builder<T>) GenericBuilder; 5: } 6: // Array 类型,使用 GenericArrayBuilder 7: if (c == Object[].class) { 8: return (Builder<T>) GenericArrayBuilder; 9: } 10: 11: // 获得 Builder 对象 12: Builder<T> b = (Builder<T>) BuilderMap.get(c); 13: if (null != b) { 14: return b; 15: } 16: 17: // 要求实现 Serializable 接口,但是并未实现,则抛出 IllegalStateException 异常 18: boolean isSerializable = Serializable.class.isAssignableFrom(c); 19: if (!isAllowNonSerializable && !isSerializable) { 20: throw new IllegalStateException("Serialized class " + c.getName() + 21: " must implement java.io.Serializable (dubbo codec setting: isAllowNonSerializable = false)"); 22: } 23: 24: // 获得 Builder 对象 25: b = (Builder<T>) nonSerializableBuilderMap.get(c); 26: if (null != b) { 27: return b; 28: } 29: 30: // 不存在,使用 Javassist 生成对应的 Builder 类,并进行创建 Builder 对象。 31: b = newBuilder(c); 32: 33: // 添加到 Builder 对象缓存中 34: if (isSerializable) { 35: BuilderMap.put(c, b); 36: } else { 37: nonSerializableBuilderMap.put(c, b); 38: } 39: 40: return b; 41: }
- 代码比较易懂,胖友看下注释哈。比较奇怪的是 「6.4 GenericBuilder」 c.isInterface() 的判断,为什么使用 GenericBuilder 对象。在 会看到答案。
6.3 常用数据类型的 Builder 实现
在 static 代码块,初始化了常用数据类型的 Builder 实现,代码如下图:
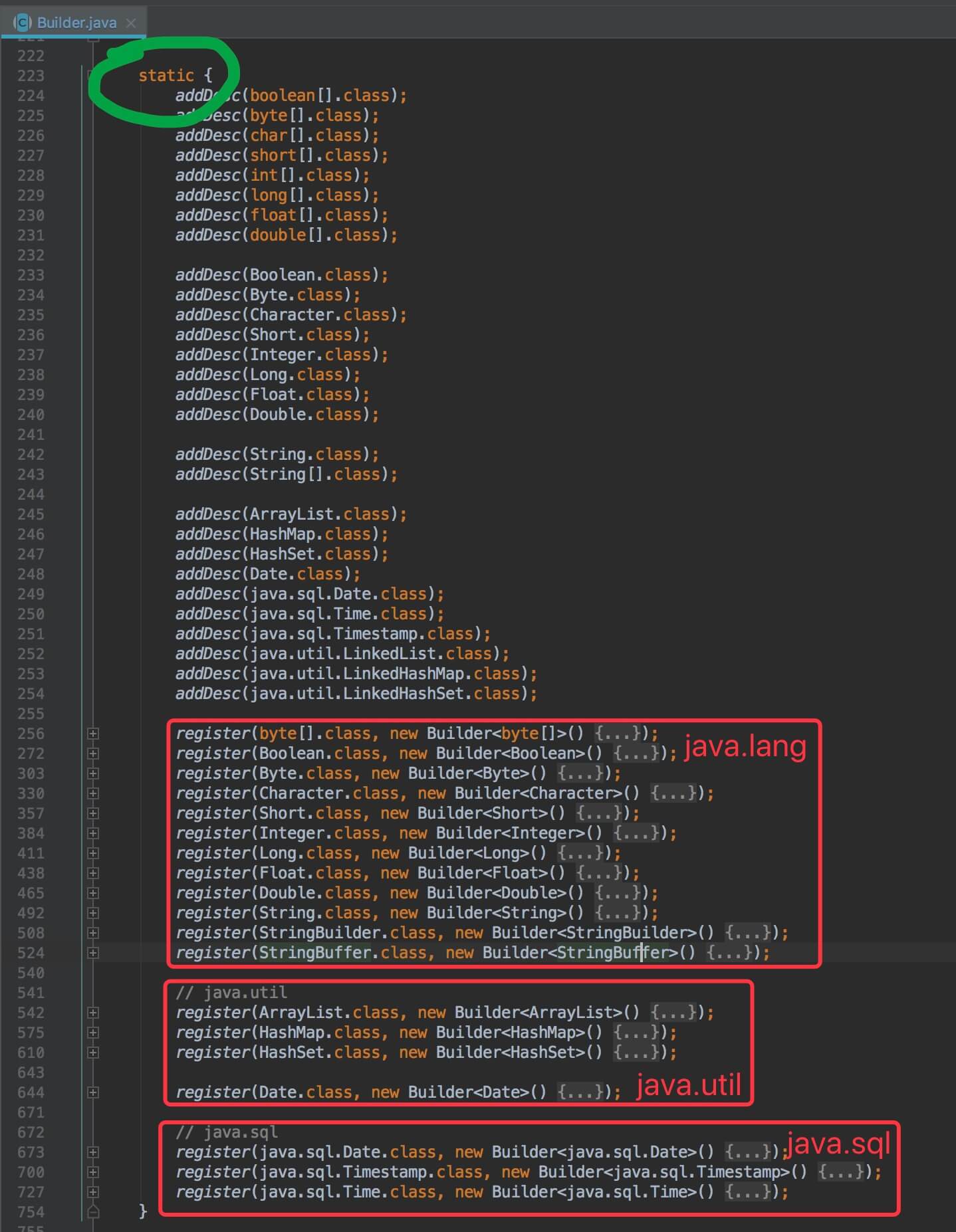
常用数据类型的 Builder 实现
代码比较简单,胖友点击 链接 ,自己查看。这里我们就以 HashMap 的 Builder 举例子,代码如下:
```plain text plain register(HashMap.class, new Builder
1
2
3
4
5
6
7
8
9
---
## 6.4 GenericBuilder
GenericBuilder ,实现 Builder 接口,**通用** Object 的 Builder 对象。代码如下:
```plain text
plain static final Builder<Object> GenericBuilder = new Builder<Object>() { @Override public Class<Object> getType() { return Object.class; } @Override public void writeTo(Object obj, GenericObjectOutput out) throws IOException { out.writeObject(obj); } @Override public Object parseFrom(GenericObjectInput in) throws IOException { return in.readObject(); } };
适用于所有对象。为什么这么说呢?我们以 #writeTo(Object obj, GenericObjectOutput out) 方法,举例子。在该方法中,会调用 GenericObjectOutput#writeObject(obj) 方法,那么在这个过程中,会获得 obj 对象,真正的 Builder 对象,从而序列化。如下图所示:

常用数据类型的 Builder 实现
6.5 SerializableBuilder
SerializableBuilder 属性,实现 Builder 接口,通用 Serializable 的 Builder 对象,使用 Java 原生序列化方式实现。目前使用在:
- Throwable 对象。
- 带有 transientSerializable 修饰符属性的 实现类。
因为是广泛匹配,所以不适合调用 #register(Class c, boolean isAllowNonSerializable) 方法,进行注册。而是在 #newObjectBuilder(Class<?> c) 方法,通过硬编码判断匹配返回。
实现代码如下:
```plain text plain static final Builder
1
2
3
4
5
6
7
8
9
---
## 6.6 AbstractObjectBuilder
AbstractObjectBuilder ,实现 Builder 接口,Builder **抽象类**。主要实现了**循环引用**对象的支持。代码如下:
```plain text
plain @Override public void writeTo(T obj, GenericObjectOutput out) throws IOException { // NULL ,写入 OBJECT_NULL 到 mBuffer 中 if (obj == null) { out.write0(OBJECT_NULL); } else { // 读取循环引用对象编号 int ref = out.getRef(obj); if (ref < 0) { // 不存在 // 添加到循环引用中,从而获得编号。下次在写入相等对象时,可使用循环引用编号的方式。 out.addRef(obj); // 写入 OBJECT 到 mBuffer 中 out.write0(OBJECT); // 写入 对象 到 mBuffer 中。 writeObject(obj, out); } else { // 存在 // 写入 OBJECT_REF 到 mBuffer 中 out.write0(OBJECT_REF); // 写入 循环引用对象编号 到 mBuffer 中 out.writeUInt(ref); } } } @Override public T parseFrom(GenericObjectInput in) throws IOException { // 读取首位字节 byte b = in.read0(); switch (b) { // 对象 case OBJECT: { // 创建对象 T ret = newInstance(in); // 添加到循环引用中,从而获得编号。下次在读取到循环引用对象编号时,可直接获取到该对象。 in.addRef(ret); // 反序列化 GenericObjectInput 到对象 readObject(ret, in); // 返回 return ret; } // 循环引用对象编号 case OBJECT_REF: // 读取循环引用对象编号 // 获得对应的对象 return (T) in.getRef(in.readUInt()); // NULL ,返回 null case OBJECT_NULL: return null; default: throw new IOException("Input format error, expect OBJECT|OBJECT_REF|OBJECT_NULL, get " + b); } }
- 和 Builder 提供的三个抽象一一对应三个抽象方法 方法 ,AbstractObjectBuilder 也定义了 :
```plain text plain /** * 创建 Builder 对应类的对象 * * @param in GenericObjectInput 对象 * @return 对应类的对象 * @throws IOException 当 IO 发生异常时 */ abstract protected T newInstance(GenericObjectInput in) throws IOException; /** * 序列化对象到 GenericObjectOutput 中的输出流。 * * @param obj 对象 * @param out GenericObjectOutput 对象 * @throws IOException 当 IO 发生异常时 */ abstract protected void writeObject(T obj, GenericObjectOutput out) throws IOException; /** * 反序列化 GenericObjectInput 到对象 * * @param ret 对象。 * 该对象在 {@link #parseFrom(GenericObjectInput)} 中,调用 {@link #newInstance(GenericObjectInput)} 创建 * @param in GenericObjectInput 对象 * @throws IOException 当 IO 发生异常时 */ abstract protected void readObject(T ret, GenericObjectInput in) throws IOException;
1
2
3
4
5
6
7
8
9
---
### 6.6.1 GenericArrayBuilder
GenericArrayBuilder ,实现 AbstractObjectBuilder 抽象类,通用**数组( Array )** 的 Builder 对象。代码如下:
```plain text
plain static final Builder<Object[]> GenericArrayBuilder = new AbstractObjectBuilder<Object[]>() { @Override public Class<Object[]> getType() { return Object[].class; } @Override protected Object[] newInstance(GenericObjectInput in) throws IOException { // 读取数组长度,并创建数组对象 return new Object[in.readUInt()]; } @Override protected void readObject(Object[] ret, GenericObjectInput in) throws IOException { // 循环读取每个对象到 ret 中 for (int i = 0; i < ret.length; i++) { ret[i] = in.readObject(); } } @Override protected void writeObject(Object[] obj, GenericObjectOutput out) throws IOException { // 写入 Length( 数组大小 ) 到 mBuffer out.writeUInt(obj.length); // 循环写入每个对象到 mBuffer 中 for (Object item : obj) { out.writeObject(item); } } };
- 因为 相等循环引用 GenericArrayBuilder 实现 AbstractObjectBuilder 抽象类,所以,若数组中有 的元素,可以使用 的功能,从而提升解析速度,降低体积。
6.6.2 其他子类
在 #newObjectBuilder(Class<?> c) 中,基于 Javassist 自动实现每个类的 Builder 类,实现的就是 AbstractObjectBuilder 抽象类。
6.5 newBuilder
```plain text plain private static
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
---
### 6.5.1 newObjectBuilder
#newObjectBuilder(Class<?> c) ,基于 Javassist **自动实现**每个类的 Builder 类( 继承 **AbstractObjectBuilder** 抽象类 ),并创建对应的 Builder 对象。代码超级冗长,老艿艿已经添加好了详细的代码注释,胖友点击 [链接](https://github.com/YunaiV/dubbo/blob/834ff308bda98adc1832e41e2544c88389eb1f1f/dubbo-common/src/main/java/com/alibaba/dubbo/common/serialize/support/dubbo/Builder.java#L1010-L1422) 自己查看。
实现原理,简单的说,其实就是,循环类的**每个**属性,**拼接**对应的序列化和反序列化的**过程**的代码字符串,最终提交给 Javassist 生成类。
良心如我,如下是一个示例:
- Student 和 Info 类 :
```plain text
plain package com.alibaba.dubbo.common.serialize.dubbo; // ... 省略 import public class YunaiBuilderTest { public static class Student implements Serializable { public String username; public String password; public Info info1; public Info info2; public Student student; public final int a = 3; } public static class Info implements Serializable { public String key; } }
- Student 对应的 Builder 类:
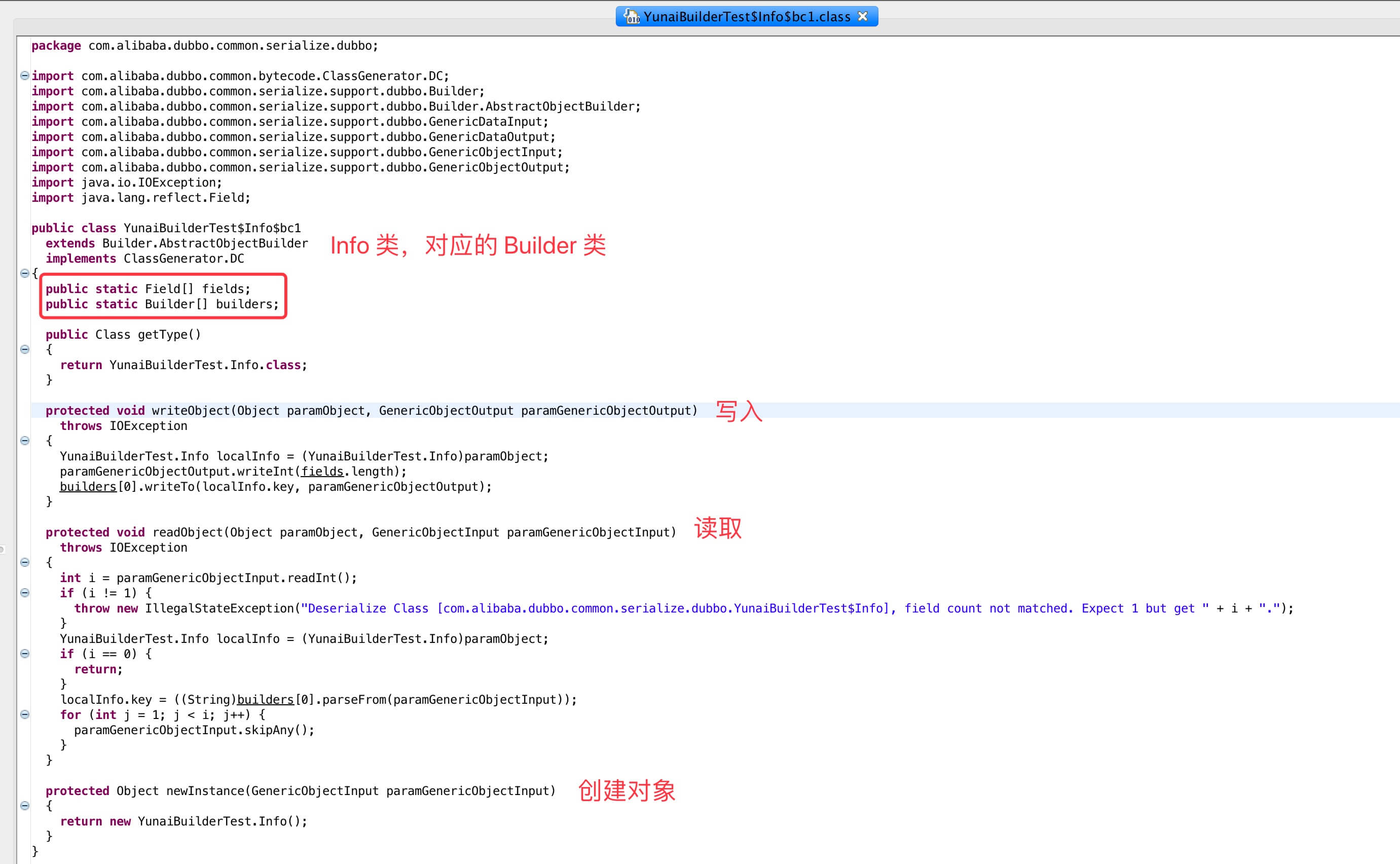 Student 对应的 Builder 类
Student 对应的 Builder 类 - Info 对象的 Builder 类:
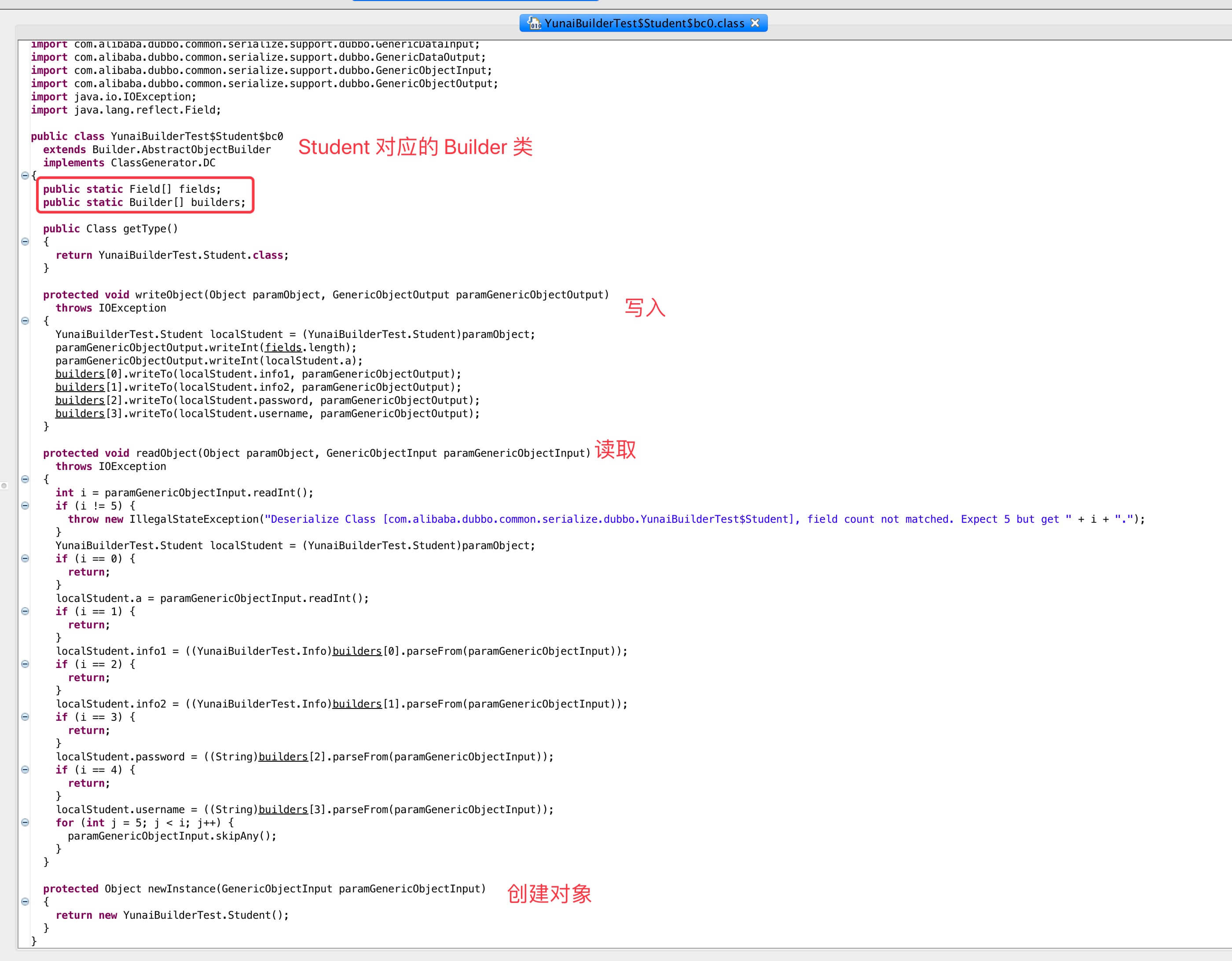 Info 对应的 Builder 类
Info 对应的 Builder 类
6.5.2 newEnumBuilder
#newEnumBuilder(Class<?> c) ,基于 Javassist 自动实现每个类的 Builder 类( 继承 Builder 接口 ),并创建对应的 Builder 对象。代码比较易懂,老艿艿已经添加好了详细的代码注释,胖友点击 链接 自己查看。
实现原理,粗暴的说,序列化使用 enum#name() 方法,反序列化使用 Enum#valueOf(Class enumType, String name) 方法。
6.5.3 newArrayBuilder
#newArrayBuilder(Class<?> c) ,基于 Javassist 自动实现每个类的 Builder 类( 继承 Builder 接口 ),并创建对应的 Builder 对象。代码比较易懂,老艿艿已经添加好了详细的代码注释,胖友点击 链接 自己查看。
实现原理,直接的说,循环数组的每个元素,拼接对应的序列化和反序列化的过程的代码字符串,最终提交给 Javassist 生成类。
比较有意思的是,多维数组的处理,例如 int[][][] 。胖友可以想想。实际,也是比较简单的。
666. 彩蛋
大四( 2012 )的时候,写了自己的序列化实现 Ludaima_Protobuf ,基于 Protobuf 的配置文件 proto ,读取,生成序列化和反序列化的静态类,基本零优化。
现在回头看了 Dubbo 序列化的实现,还是收益良多。美滋滋。