volatile 内存语义分析
https://www.iocoder.cn/JUC/sike/jmm-2-volatile/
前篇博客 《【死磕 Java 并发】—– 深入分析 volatile 的实现原理》 中已经阐述了 volatile 的特性了:
- volatile 可见性:对一个 volatile 的读,总可以看到对这个变量最终的写。
- volatile 原子性:volatile 对单个读 / 写具有原子性(32 位 Long、Double),但是复合操作除外,例如 i++ 。
- JVM 底层采用”内存屏障”来实现 volatile 语义。
下面 LZ 就通过 happens-before 原则和 volatile 的内存语义,两个方向分析 volatile 。
1. volatile 与 happens-before
在这篇博客 《【死磕 Java 并发】—– Java 内存模型之 happens-before》 中,LZ 阐述了 happens-before 是用来判断是否存在数据竞争、线程是否安全的主要依据,它保证了多线程环境下的可见性。下面我们就那个经典的例子,来分析 volatile 变量的读写,如何建立的 happens-before 关系。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class VolatileTest {
int i = 0;
volatile boolean flag = false;
// Thread A
public void write() {
i = 2; // 1
flag = true; // 2
}
// Thread B
public void read() {
if (flag) { // 3
System.out.println("—i =" + i); // 4
}
}
}
依据 happens-before 原则,就上面程序得到如下关系:
- 程序顺序原则:操作 1 happens-before 操作 2 ,操作 3 happens-before 操作 4 。
- volatile 原则:操作 2 happens-before 操作 3 。
- 传递性原则:操作 1 happens-before 操作 4 。
操作 1、操作 4 存在 happens-before 关系,那么操作 1 一定是对 操作 4 是可见的。可能有同学就会问,操作 1、操作 2 可能会发生重排序啊,会吗?如果看过 LZ 的博客就会明白,volatile 除了保证可见性外,还有就是禁止重排序。所以 A 线程在写 volatile 变量之前所有可见的共享变量,在线程 B 读同一个 volatile 变量后,将立即变得对线程 B 可见。
2. volataile 的内存语义及其实现
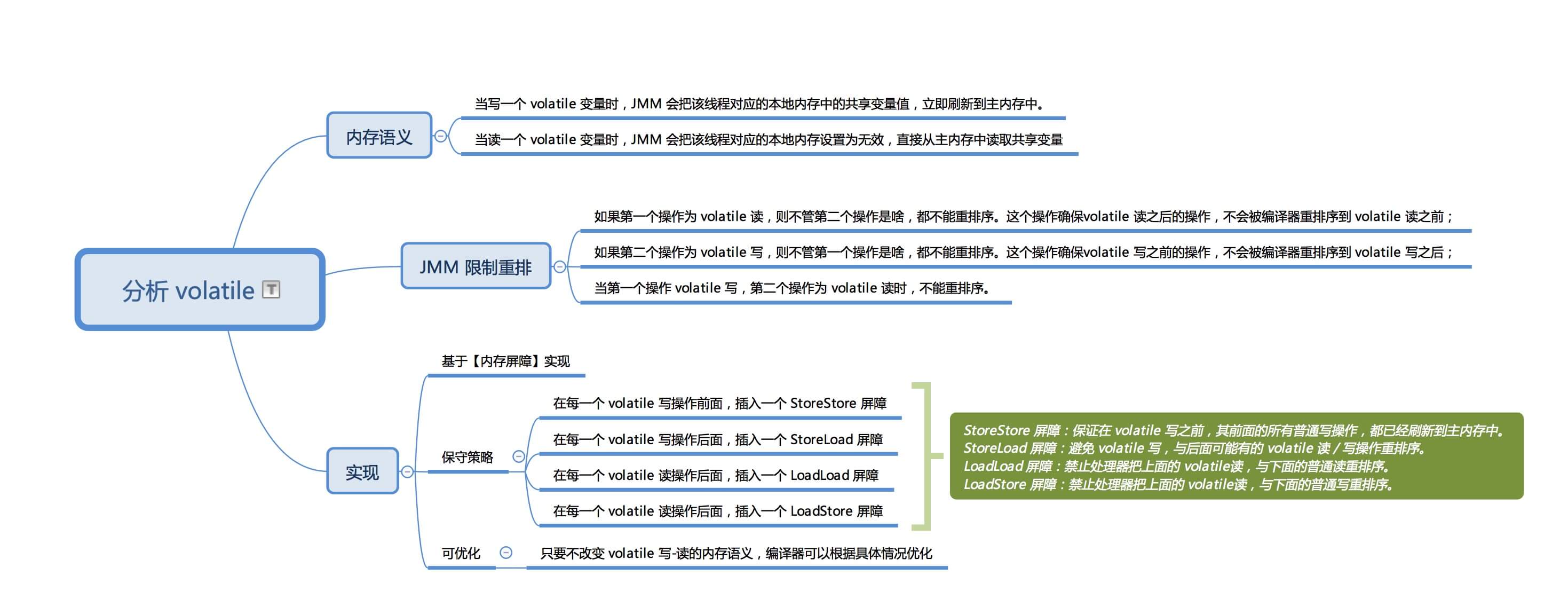
在 JMM 中,线程之间的通信采用共享内存来实现的。volatile 的内存语义是:
当写一个 volatile 变量时,JMM 会把该线程对应的本地内存中的共享变量值,立即刷新到主内存中。当读一个 volatile 变量时,JMM 会把该线程对应的本地内存设置为无效,直接从主内存中读取共享变量
所以 volatile 的写内存语义是直接刷新到主内存中,读的内存语义是直接从主内存中读取。
那么 volatile 的内存语义是如何实现的呢?对于一般的变量则会被重排序,而对于 volatile 的变量则不能。这样会影响其内存语义,所以为了实现 volatile 的内存语义,JMM 会限制重排序。其重排序规则如下:
翻译如下:
- 如果第一个操作为 volatile 读,则不管第二个操作是啥,都不能重排序。这个操作确保volatile 读之后的操作,不会被编译器重排序到 volatile 读之前;
- 如果第二个操作为 volatile 写,则不管第一个操作是啥,都不能重排序。这个操作确保volatile 写之前的操作,不会被编译器重排序到 volatile 写之后;
- 当第一个操作 volatile 写,第二个操作为 volatile 读时,不能重排序。
volatile 的底层实现,是通过插入内存屏障。但是对于编译器来说,发现一个最优布置来最小化插入内存屏障的总数几乎是不可能的,所以,JMM 采用了保守策略。
策略如下:
- 在每一个 volatile 写操作前面,插入一个 StoreStore 屏障
- 在每一个 volatile 写操作后面,插入一个 StoreLoad 屏障
- 在每一个 volatile 读操作后面,插入一个 LoadLoad 屏障
- 在每一个 volatile 读操作后面,插入一个 LoadStore 屏障
原因如下:
- StoreStore 屏障:保证在 volatile 写之前,其前面的所有普通写操作,都已经刷新到主内存中。
- StoreLoad 屏障:避免 volatile 写,与后面可能有的 volatile 读 / 写操作重排序。
- LoadLoad 屏障:禁止处理器把上面的 volatile读,与下面的普通读重排序。
- LoadStore 屏障:禁止处理器把上面的 volatile读,与下面的普通写重排序。
2.1 案例 1:VolatileTest
下面我们就上面 VolatileTest 例子重新分析下:
1
2
3
4
5
6
7
8
9
10
11
12
13
public class VolatileTest {
int i = 0;
volatile boolean flag = false;
public void write() {
i = 2;
flag = true;
}
public void read() {
if (flag){
System.out.println("—i =" + i);
}
}
}

2.2 案例 2:VolatileBarrierExample
volatile 的内存屏障插入策略非常保守,其实在实际中,只要不改变 volatile 写-读的内存语义,编译器可以根据具体情况优化,省略不必要的屏障。如下例子,摘自方腾飞 《Java并发编程的艺术》:
1
2
3
4
5
6
7
8
9
10
11
12
13
public class VolatileBarrierExample {
int a = 0;
volatile int v1 = 1;
volatile int v2 = 2;
void readAndWrite() {
int i = v1; // volatile读
int j = v2; // volatile读
a = i + j; // 普通读
v1 = i + 1; // volatile写
v2 = j * 2; // volatile写
}
}
没有优化的示例图如下:

我们来分析,上图有哪些内存屏障指令是多余的:
- 1:这个肯定要保留了
- 2:禁止下面所有的普通写与上面的 volatile 读重排序,但是由于存在第二个 volatile读,那个普通的读根本无法越过第二个 volatile 读。所以可以省略。
- 3:下面已经不存在普通读了,可以省略。
- 4:保留
- 5:保留
- 6:下面跟着一个 volatile 写,所以可以省略
- 7:保留
- 8:保留
所以 2、3、6 可以省略,其示意图如下: