线程池
线程池
线程池的目的:
- 重用线程,而不用重新创建,减少了线程创建与销毁的消耗
- 解决线程生命周期的开销和资源不足问题
什么时候使用线程池:
- 单个任务处理时间比较短(特别是消耗时间远小于线程的创建和销毁时间时)
- 需要处理的任务数量很大
线程池的优势:
- 重用存在的线程,减少线程创建,消亡的开销,提高性能
- 提高相应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行
- 提高线程的可管理性,线程是稀缺资源,如果无限制创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控
线程的实现方式
- Runnable - run方法就是实际执行的任务,无返回值,不可抛出异常
- Thread - 执行实现Runnable接口的实现类
- Callable - call方法,可接受泛型,有返回值,返回值就是任务执行结束的结果,可抛出异常
三、 ThreadPool&Executor
1 Executor
线程池顶级接口。定义方法,void execute(Runnable)。
方法是用于处理任务的一个服务方法。调用者提供 Runnable 接口的实现,线程池通过线程执行这个 Runnable。
服务方法无返回值的。是 Runnable 接口中的 run 方法无返回值。
常用方法 - void execute(Runnable)
作用是: 启动线程任务的。
- execute(Runnable command):履行Ruannable类型的任务,
- submit(task):可用来提交Callable或Runnable任务,并返回代表此任务的Future对象
- shutdown():在完成已提交的任务后封闭办事,不再接管新任务,
- shutdownNow():停止所有正在履行的任务并封闭办事。
- isTerminated():测试是否所有任务都履行完毕了。
- isShutdown():测试是否该ExecutorService已被关闭。
2 ExecutorService
Executor 接口的子接口。提供了一个新的服务方法,submit。有返回值(Future 类型)。
submit 方法提供了 overload 方法。
常见方法 -
- void execute(Runnable), 其中有参数类型为 Runnable 的,不需要提供返回值的;
- Future submit(Callable),有参数类型为 Callable,可以提供线程执行后的返回值。
- Future submit(Runnable) Future,是 submit 方法的返回值。代表未来,也就是线程执行结束后的一种结果。如返回值。
线程池状态: Running, ShuttingDown, Termitnaed
- Running - 线程池正在执行中。活动状态。
- ShuttingDown - 线程池正在关闭过程中。。一旦进入这个状态,线程池不再接收新的任务,处理所有已接收的任务,处理完毕后,关闭线程池。 优雅关闭
- Terminated - 线程池已经关闭。
3 Future
未来结果,代表线程任务执行结束后的结果。
获取线程执行结果的方式是通过 get 方法获取的。get()的返回就是call方法中的返回值
```plain text
- get 无参,阻塞等待线程执行结束,并得到结果。
- get 有参,阻塞固定时长,等待线程执行结束后的结果,如果在阻塞时长范围内,线程未执行结束,抛出异常。 ```
常用方法: T get() T get(long, TimeUnit)
4 Callable
可执行接口。 类似 Runnable 接口。也是可以启动一个线程的接口。其中定义的方法是call。
call 方法的作用和 Runnable 中的 run 方法完全一致。call 方法有返回值。
返回值是一个泛型,在你定义创建Callback时可以指定返回值类型
接口方法 : Object call();
- 相当于 Runnable 接口中的 run 方法。
- 区别为此方法有返回值。可以抛出异常(Runable不能抛出异常),不能抛出已检查异常。
和 Runnable 接口的选择 -需要返回值或需要抛出异常时,使用 Callable,其他情况可任意选择。
5 Executors
工具类型。为 Executor 线程池提供工具方法。可以快速的提供若干种线程池。
如:固定容量的,无限容量的,容量为 1 等各种线程池。
线程池是一个进程级的重量级资源。默认的生命周期和 JVM 一致。– 当开启线程池后,直到 JVM 关闭为止,是线程池的默认生命周期。
如果手工调用 shutdown 方法,那么线程池执行所有的任务后,自动关闭。
开始 - 创建线程池。
结束 - JVM 关闭或调用 shutdown 并处理完所有的任务。
类似 Arrays,Collections 等工具类型的功用。
6 FixedThreadPool
newFIxedThreadPool()方法,返回一个固定数量的线程池,该方法的线程数始终不变
- 容量固定的线程池。
- 活动状态和线程池容量是有上限的线程池。
- 所有的线程池中,都有一个任务队列。使用的是 BlockingQueue 作为任务的载体。
- 当任务数量大于线程池容量的时候,没有运行的任务保存在任务队列中,
- 当线程有空闲的,自动从队列中取出任务执行。
使用场景: 大多数情况下,使用的线程池,首选推荐 FixedThreadPool。OS 系统和硬件
是有线程支持上限。不能 的无限制提供线程池。
线程池默认的容量上限是 Integer.MAX_VALUE。
常见的线程池容量: PC - 200。 服务器 - 1000~10000
queued tasks - 任务。
completed tasks - 结束任务队列
7 CachedThreadPool
缓存的线程池。容量不限(Integer.MAX_VALUE)。自动扩容。
容量管理策略:
- 如果线程池中的线程数量不满足任务执行,创建新的线程。
- 每次有新任务无法即时处理的时候,都会创建新的线程。
- 当线程池中的线程空闲时长达到一定的临界值(默认 60 秒),自动释放线程。
- 默认线程空闲 60 秒,自动销毁。
应用场景: 内部应用或测试应用。 内部应用,有条件的内部数据瞬间处理时应用,
如:
```plain text 电信平台夜间执行数据整理(有把握在短时间内处理完所有工作,且对硬件和软件有足够的信心)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
测试应用,在测试的时候,尝试得到硬件或软件的最高负载量,用于提供FixedThreadPool 容量的指导。
---
8 ScheduledThreadPool
计划任务线程池。可以根据计划自动执行任务的线程池。可以指定线程的数量
scheduleAtFixedRate(Runnable, start_limit, period, timeunit) – 定时完成任务
- runnable - 要执行的任务。
- start_limit - 第一次任务执行的间隔。
- period- 多次任务执行的间隔。
- timeunit - 多次任务执行间隔的时间单位。
与逆行的时间越长,时间误差越大
使用场景: 计划任务时选用(DelaydQueue),如:电信行业中的数据整理,每分钟整理,每小时整理,每天整理等。
newScheduleThrePool()方法:返回一个ScheduleExecutorService对象,但该线程池。
**该方法中,每一个线程都可以调用timer**
---
9 SingleThreadExceutor
单一容量的线程池。
使用场景: **保证任务顺序**时使用。如: 游戏大厅中的公共频道聊天。秒杀。
---
10 ForkJoinPool
分支合并线程池(mapduce 类似的设计思想)。适合用于处理复杂任务。
初始化线程容量与 CPU 核心数相关。
**线程池中运行的内容必须是 ForkJoinTask 的子类型(RecursiveTask,RecursiveAction)**。
ForkJoinPool - 分支合并线程池。 可以递归完成复杂任务。
要求可分支合并的任务必须是 ForkJoinTask 类型的子类型。其中提供了分支和合并的能力。
ForkJoinTask 类型提供了两个抽象子类型,
- RecursiveTask 有返回结果的分支合并任务,
- RecursiveAction 无返回结果的分支合并任务。
(Callable/Runnable)compute 方法:就是任务的执行逻辑。
ForkJoinPool 没有所谓的容量。默认都是 1 个线程。根据任务自动的分支新的子线程。
当子线程任务结束后,自动合并。所谓自动是根据 fork 和 join 两个方法实现的。
应用: 主要是做科学计算或天文计算的。数据分析的。
---
11 WorkStealingPool
JDK1.8 新增的线程池。工作窃取线程池。当线程池中有空闲连接时,自动到等待队列中
窃取未完成任务,自动执行。
初始化线程容量与 CPU 核心数相关。此线程池中维护的是精灵线程。
ExecutorService.newWorkStealingPool();
---
12 ThreadPoolExecutor
线程池底层实现。除 ForkJoinPool 外,其他常用线程池底层都是使用 ThreadPoolExecutor实现的。
自定义线程池:
若Executor工厂类无法满足我们的需求,可以自己去创建自定义的线程池,其构造方法为:
**public ThreadPoolExecutor**
**(int corePoolSize, ————– **** ****核心容量,创建线程池的时候,默认有多少线程。也是线程池保持****的最少线程数**
**int maximumPoolSize, ————– 最大线程数(最大容量)**
**long keepAlive line, ————– **** ****生命周期,0 为永久。当线程空闲多久后,自动回收。**
**TimeUnit unit, ————– **** ****生命周期单位,为生命周期提供单位,如:秒,毫秒**
**BlockingQueue workQueue, ————– **** ****任务队列,阻塞队列。注意,泛型必须是**
**ThreadFactory threadFactory , ————–**
**RejectedExecurtionHandler hadler ————– 可以自定义任务拒绝逻辑){**
**}**
自定义线程池使用详细:
这个构造方法对于队列是何时能么类型比较关键
在使有界街队列时,若有新的任务需要执行,如果线程池实际线程数小于corePoolSize,则优先创建线程,
若大于corePoolSize,则会将任务加入到队列,
若队列已满,则在总线程数不大于maximumPoolSize的前提下,创建新的线程,
若线程数大于maximumPoolSize,则执行拒绝策略。或其他自定义方式。
无界的任务队列时,LinkedBlockQueue。与有界队列相比,除非系统资源耗尽,否则**无界的队列任务不存在任务入队失败**的情况。当有新任务到来,系统的线程数小于corePoolSize时,则新建线程 执性任务,达到corePoolSize后,就不会继续增加,若后续仍有新的任务加入,而又没有空闲的线程资源,则任务直接入队等待。
JDK拒绝策略:
AbortPolicy:直接抛出异常组织系统正常工作(当前系统正常运行)
CallerRunsPolicy:
DiscardOldestPolicy:丢弃最老的请求,再尝试执行当前的任务
DiscardPolicy:丢弃无法处理的任务,不给予任务处理。
如果需要自定义拒绝策略可以实现RejectedExecutionHandler接口。可以自定义处理方式
一般为,记录log,将任务重要信息记录下来,空闲时间再进行批处理
使用场景: 默认提供的线程池不满足条件时使用。如:初始线程数据 4,最大线程数
200,线程空闲周期 30 秒。
FixedThreadPool - 固定容量线程池,在创建线程池时,容量固定
构造的时候提供线程的最大容量
ExecutorService - 线程池服务类型,所有的线程池类型都实现了这个接口
实现这个接口,代表可以提供线程池能力
Executors - Executor的工具类。类似于collection 和 Collections的关系
Executor - 线程池底层处理机制。
在使用线程池的时候,底层如何调用线程中的逻辑。
Executor中只有一个execute() 方法
参数是一个Runable接口的实现类
Executor框架
jdk提供了一套线程框架Executor,其中一个Executors,他扮演者线程工厂的角色,可以通过Executors可以创建特定的功能的线程池
线程组:ThreadGroup
系统级别线程组:
线程组做到安全屏蔽,
比如:线程1和线程2隶属于线程组1,线程3线程4隶属于线程组2;那么线程1和线程2之间,线程3和线程4之间可以互相通信,而线程1和线程3/4都不能通信(不同线程组,相互隔离)
---
线程池的配置
CPU密集型
CPU密集型也叫计算密集型,CPU的使用占有率极高,大部分时间用来做计算、逻辑判断等CPU动作的程序
线程数一般设置为:
**线程数 = CPU核数 + 1 (核数应为算上超线程,有部分CPU可超频运行逻辑核心数为物理核心数的2倍)**
IO密集型
大部分操作是做I/O,大量的读写操作,占用大量内存,而CPU相对较空闲
线程一般设置为:
**线程数 = ((线程等待时间+ 线程CPU时间)/ 线程CPU时间 ) * CPU数目**
CPU密集型 vs IO密集型
计算密集型任务的特点是要进行大量的计算,全靠CPU的运算能力
如: 视频的高清解码
最高效的利用CPU,那么同时运行的线程数量就应该等于CPU核心数
IO密集型,涉及到网络、磁盘、内存的IO,这类任务通常大量时间都花费在IO操作上,而CPU相对空闲
本文基于 Dubbo 2.6.1 版本,望知悉。
# 1. 概述
在 [《Dubbo 用户指南 —— 线程模型》](http://dubbo.apache.org/zh-cn/docs/user/demos/thread-model.html) 一文中,我们可以看到 Dubbo 提供了**三种线程池的实现**:
ThreadPool
- fixed**缺省**
固定大小线程池,启动时建立线程,不关闭,一直持有。(
)
- cached
缓存线程池,空闲一分钟自动删除,需要时重建。
- limited
可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。
在 [dubbo-common](https://github.com/apache/incubator-dubbo/tree/master/dubbo-common) 模块的 threadpool 包下实现,如下图所示:
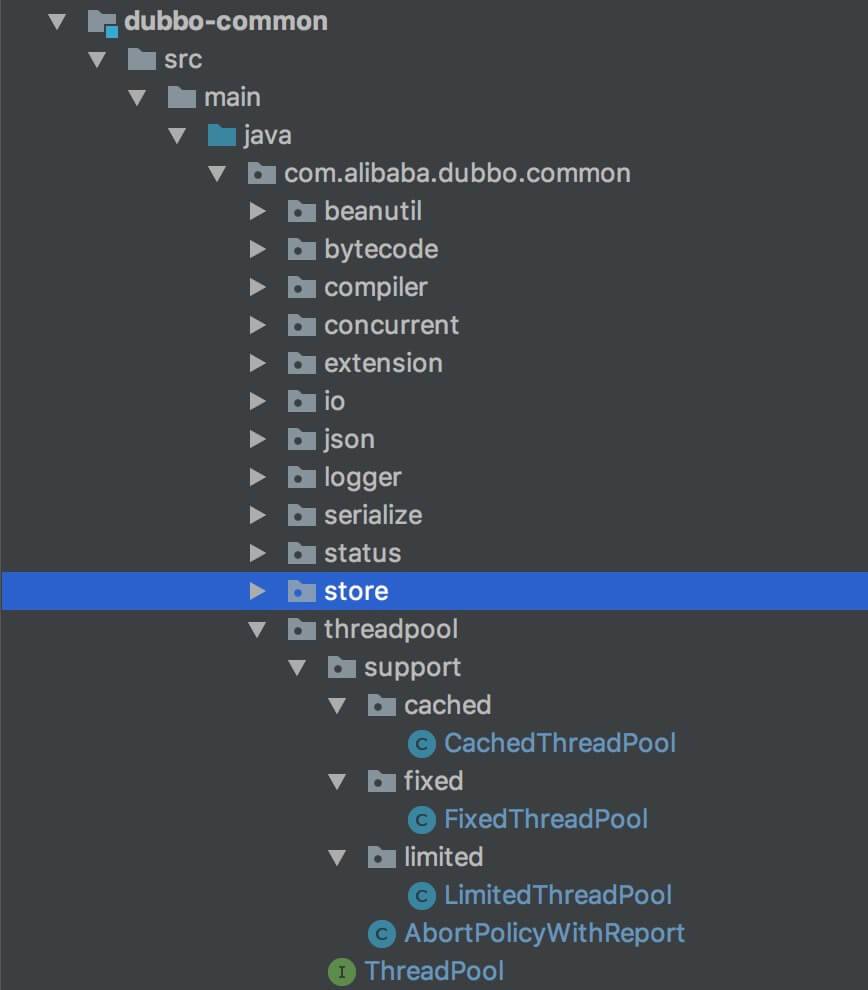
threadpool
# 2. ThreadPool
[com.alibaba.dubbo.common.threadpool.ThreadPool](https://github.com/apache/incubator-dubbo/blob/bb8884e04433677d6abc6f05c6ad9d39e3dcf236/dubbo-common/src/main/java/com/alibaba/dubbo/common/threadpool/ThreadPool.java) ,线程池接口。代码如下:
```plain text
plain @SPI("fixed") public interface ThreadPool { /** * Thread pool * * @param url URL contains thread parameter * @return thread pool */ @Adaptive({Constants.THREADPOOL_KEY}) Executor getExecutor(URL url); }
- @SPI(“fixed”)拓展点 注解,Dubbo SPI ,默认为 “fixed” 。
- @Adaptive({Constants.THREADPOOL_KEY}) 注解,基于 Dubbo SPI Adaptive 机制,加载对应的线程池实现,使用 URL.threadpool 属性。
- #getExecutor(url)对应 方法,获得 的线程池的执行器。
子类类图如下:
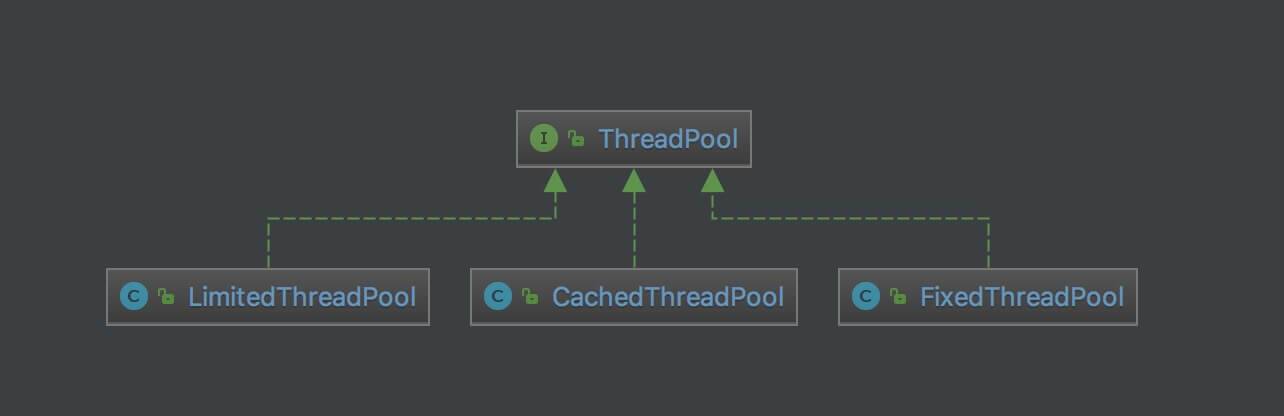
类图
2.1 FixedThreadPool
com.alibaba.dubbo.common.threadpool.support.fixed.FixedThreadPool ,实现 ThreadPool 接口,固定大小线程池,启动时建立线程,不关闭,一直持有。代码如下:
```plain text plain 1: public class FixedThreadPool implements ThreadPool { 2: 3: @Override 4: public Executor getExecutor(URL url) { 5: // 线程名 6: String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME); 7: // 线程数 8: int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS); 9: // 队列数 10: int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES); 11: // 创建执行器 12: return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS, 13: queues == 0 ? new SynchronousQueue
1
2
3
4
5
6
7
---
- 第 5 至 10 行:获得线程名、线程数、队列数。目前只有服务提供者使用,配置方式如下:
```plain text
plain <dubbo:service interface="com.alibaba.dubbo.demo.DemoService" ref="demoService"> <dubbo:parameter key="threadname" value="shuaiqi" /> <dubbo:parameter key="threads" value="123" /> <dubbo:parameter key="queues" value="10" /> </dubbo:service>
- 第 11 至 16 行:创建执行器 ThreadPoolExecutor 对象。
- 根据不同的队列数,使用不同的队列实现:
- 第 13 行: queues == 0 , SynchronousQueue 对象。
- 第 14 行: queues < 0 , LinkedBlockingQueue 对象。
- 第 15 行: queues > 0 ,带队列数的 LinkedBlockingQueue 对象。
- 推荐阅读:
- 第 16 行:创建 NamedThreadFactory线程名 对象,用于生成 。
- 第 16 行:创建 AbortPolicyWithReport 对象,用于当任务添加到线程池中被拒绝时 。
- 根据不同的队列数,使用不同的队列实现:
2.2 CachedThreadPool
com.alibaba.dubbo.common.threadpool.support.cached.CachedThreadPool ,实现 ThreadPool 接口,缓存线程池,空闲一定时长,自动删除,需要时重建。代码如下:
```plain text plain 1: public class CachedThreadPool implements ThreadPool { 2: 3: @Override 4: public Executor getExecutor(URL url) { 5: // 线程池名 6: String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME); 7: // 核心线程数 8: int cores = url.getParameter(Constants.CORE_THREADS_KEY, Constants.DEFAULT_CORE_THREADS); 9: // 最大线程数 10: int threads = url.getParameter(Constants.THREADS_KEY, Integer.MAX_VALUE); 11: // 队列数 12: int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES); 13: // 线程存活时长 14: int alive = url.getParameter(Constants.ALIVE_KEY, Constants.DEFAULT_ALIVE); 15: // 创建执行器 16: return new ThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS, 17: queues == 0 ? new SynchronousQueue
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
---
- 第 5 至 14 行:获得线程名、核心线程数、最大线程数、队列数、线程存活时长。
- 配置方式和 FixedThreadPool 类似,使用
配置。
- 第 16 至 20 行:创建执行器 ThreadPoolExecutor 对象。
- 和 FixedThreadPool 相对类似。
## 2.3 LimitedThreadPool
com.alibaba.dubbo.common.threadpool.support.limited.LimitedThreadPool ,实现 ThreadPool 接口,可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。代码如下:
```plain text
plain 1: public class LimitedThreadPool implements ThreadPool { 2: 3: @Override 4: public Executor getExecutor(URL url) { 5: // 线程名 6: String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME); 7: // 核心线程数 8: int cores = url.getParameter(Constants.CORE_THREADS_KEY, Constants.DEFAULT_CORE_THREADS); 9: // 最大线程数 10: int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS); 11: // 队列数 12: int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES); 13: // 创建执行器 14: return new ThreadPoolExecutor(cores, threads, Long.MAX_VALUE, TimeUnit.MILLISECONDS, 15: queues == 0 ? new SynchronousQueue<Runnable>() : 16: (queues < 0 ? new LinkedBlockingQueue<Runnable>() 17: : new LinkedBlockingQueue<Runnable>(queues)), 18: new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url)); 19: } 20: 21: }
- 和 CachedThreadPool 实现是基本一致的,差异点在 空闲时间无限大 alive == Integer.MAX_VALUE , ,即不会自动删除。
3. AbortPolicyWithReport
com.alibaba.dubbo.common.threadpool.support.AbortPolicyWithReport ,实现 java.util.concurrent.ThreadPoolExecutor.AbortPolicy ,拒绝策略实现类。打印 JStack ,分析线程状态。
3.1 属性
```plain text plain /** * 线程名 */ private final String threadName; /** * URL 对象 */ private final URL url; /** * 最后打印时间 */ private static volatile long lastPrintTime = 0; /** * 信号量,大小为 1 。 */ private static Semaphore guard = new Semaphore(1); public AbortPolicyWithReport(String threadName, URL url) { this.threadName = threadName; this.url = url; }
1
2
3
4
5
6
7
8
9
---
## 3.2 rejectedExecution
#rejectedExecution(Runnable, ThreadPoolExecutor)**实现**方法,代码如下:
```plain text
plain 1: @Override 2: public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { 3: // 打印告警日志 4: String msg = String.format("Thread pool is EXHAUSTED!" + 5: " Thread Name: %s, Pool Size: %d (active: %d, core: %d, max: %d, largest: %d), Task: %d (completed: %d)," + 6: " Executor status:(isShutdown:%s, isTerminated:%s, isTerminating:%s), in %s://%s:%d!", 7: threadName, e.getPoolSize(), e.getActiveCount(), e.getCorePoolSize(), e.getMaximumPoolSize(), e.getLargestPoolSize(), 8: e.getTaskCount(), e.getCompletedTaskCount(), e.isShutdown(), e.isTerminated(), e.isTerminating(), 9: url.getProtocol(), url.getIp(), url.getPort()); 10: logger.warn(msg); 11: // 打印 JStack ,分析线程状态。 12: dumpJStack(); 13: // 抛出 RejectedExecutionException 异常 14: throw new RejectedExecutionException(msg); 15: }
- 第 3 至 10 行:打印告警日志 。
- 第 12 行:调用 JStack #dumpJStack() 方法,打印 ,分析线程状态。
- 第 14 行:抛出 RejectedExecutionException 异常。
3.3 dumpJStack
#dumpJStack() 方法,打印 JStack。代码如下:
```plain text plain 1: private void dumpJStack() { 2: long now = System.currentTimeMillis(); 3: 4: // 每 10 分钟,打印一次。 5: // dump every 10 minutes 6: if (now - lastPrintTime < 10 * 60 * 1000) { 7: return; 8: } 9: 10: // 获得信号量 11: if (!guard.tryAcquire()) { 12: return; 13: } 14: 15: // 创建线程池,后台执行打印 JStack 16: Executors.newSingleThreadExecutor().execute(new Runnable() { 17: @Override 18: public void run() { 19: 20: // 获得系统 21: String OS = System.getProperty(“os.name”).toLowerCase(); 22: // 获得路径 23: String dumpPath = url.getParameter(Constants.DUMP_DIRECTORY, System.getProperty(“user.home”)); 24: SimpleDateFormat sdf; 25: // window system don’t support “:” in file name 26: if(OS.contains(“win”)){ 27: sdf = new SimpleDateFormat(“yyyy-MM-dd_HH-mm-ss”); 28: }else { 29: sdf = new SimpleDateFormat(“yyyy-MM-dd_HH:mm:ss”); 30: } 31: String dateStr = sdf.format(new Date()); 32: // 获得输出流 33: FileOutputStream jstackStream = null; 34: try { 35: jstackStream = new FileOutputStream(new File(dumpPath, “Dubbo_JStack.log” + “.” + dateStr)); 36: // 打印 JStack 37: JVMUtil.jstack(jstackStream); 38: } catch (Throwable t) { 39: logger.error(“dump jstack error”, t); 40: } finally { 41: // 释放信号量 42: guard.release(); 43: // 释放输出流 44: if (jstackStream != null) { 45: try { 46: jstackStream.flush(); 47: jstackStream.close(); 48: } catch (IOException e) { 49: } 50: } 51: } 52: // 记录最后打印时间 53: lastPrintTime = System.currentTimeMillis(); 54: } 55: }); 56: 57: }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
---
- 第 2 至 8 行:每 10 分钟,**只**
打印一次。
- 第 10 至 13 行:获得信号量。保证,同一时间,**有且仅有**
一个线程执行打印。
- 第 15 至 54 行:创建线程池,**后台**
执行打印 JStack 。
- 第 20 至 31 行:获得路径。
- 第 32 至 35 行:获得文件输出流。
- 第 37 行:调用
JVMUtil#jstack(OutputStream)
方法,打印 JStack 。
- 第 42 行:释放信号量。
- 第 44 至 50 行:释放输出流。
- 第 53 行:记录最后打印时间。
# 4. JVMUtil
[com.alibaba.dubbo.common.utils.JVMUtil](https://github.com/apache/incubator-dubbo/blob/bb8884e04433677d6abc6f05c6ad9d39e3dcf236/dubbo-common/src/main/java/com/alibaba/dubbo/common/utils/JVMUtil.java) ,JVM 工具类。目前,仅有 JStack 功能,胖友可以点击链接,自己查看下代码。
如下是一个 JStack 日志的示例:
```plain text
plain 123312:tmp yunai$ cat Dubbo_JStack.log.2018-03-27_18\:57\:32 "pool-2-thread-1" Id=11 RUNNABLE at sun.management.ThreadImpl.dumpThreads0(Native Method) at sun.management.ThreadImpl.dumpAllThreads(ThreadImpl.java:454) at com.alibaba.dubbo.common.utils.JVMUtil.jstack(JVMUtil.java:34) at com.alibaba.dubbo.common.threadpool.support.AbortPolicyWithReport$1.run(AbortPolicyWithReport.java:122) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Number of locked synchronizers = 1 - java.util.concurrent.ThreadPoolExecutor$Worker@5cbc508c "Monitor Ctrl-Break" Id=5 RUNNABLE (in native) at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:171) at java.net.SocketInputStream.read(SocketInputStream.java:141) at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:284) at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:326) at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178) - locked java.io.InputStreamReader@5c7efb52 at java.io.InputStreamReader.read(InputStreamReader.java:184) at java.io.BufferedReader.fill(BufferedReader.java:161) at java.io.BufferedReader.readLine(BufferedReader.java:324) - locked java.io.InputStreamReader@5c7efb52 at java.io.BufferedReader.readLine(BufferedReader.java:389) at com.intellij.rt.execution.application.AppMainV2$1.run(AppMainV2.java:64) "Signal Dispatcher" Id=4 RUNNABLE "Finalizer" Id=3 WAITING on java.lang.ref.ReferenceQueue$Lock@197c6eb9 at java.lang.Object.wait(Native Method) - waiting on java.lang.ref.ReferenceQueue$Lock@197c6eb9 at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:164) at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209) "Reference Handler" Id=2 WAITING on java.lang.ref.Reference$Lock@7b19fa34 at java.lang.Object.wait(Native Method) - waiting on java.lang.ref.Reference$Lock@7b19fa34 at java.lang.Object.wait(Object.java:502) at java.lang.ref.Reference.tryHandlePending(Reference.java:191) at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153) "main" Id=1 TIMED_WAITING at java.lang.Thread.sleep(Native Method) at com.alibaba.dubbo.common.threadpool.AbortPolicyWithReportTest.jStackDumpTest(AbortPolicyWithReportTest.java:44) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50) at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12) at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47) at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17) at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57) at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290) at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71) at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288) at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58) at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268) at org.junit.runners.ParentRunner.run(ParentRunner.java:363) at org.junit.runner.JUnitCore.run(JUnitCore.java:137) at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:68) at com.intellij.rt.execution.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:47) at com.intellij.rt.execution.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:242) at com.intellij.rt.execution.junit.JUnitStarter.main(JUnitStarter.java:70)
另外,胖友可以看看 《如何使用jstack分析线程状态》 文章。
1. 概述
在 《Dubbo 用户指南 —— 线程模型》 一文中,我们可以看到 Dubbo 提供了三种线程池的实现:
ThreadPool
- fixed缺省 固定大小线程池,启动时建立线程,不关闭,一直持有。( )
- cached 缓存线程池,空闲一分钟自动删除,需要时重建。
- limited 可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。
在 dubbo-common 模块的 threadpool 包下实现,如下图所示:

threadpool
2. ThreadPool
com.alibaba.dubbo.common.threadpool.ThreadPool ,线程池接口。代码如下:
```plain text plain @SPI(“fixed”) public interface ThreadPool { /** * Thread pool * * @param url URL contains thread parameter * @return thread pool */ @Adaptive({Constants.THREADPOOL_KEY}) Executor getExecutor(URL url); }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
---
- @SPI(“fixed”)**拓展点**
注解,Dubbo SPI
,默认为
“fixed”
。
- @Adaptive({Constants.THREADPOOL_KEY})
注解,基于 Dubbo SPI Adaptive 机制,加载对应的线程池实现,使用
URL.threadpool
属性。
- #getExecutor(url)**对应**
方法,获得
的线程池的执行器。
子类类图如下:

类图
## 2.1 FixedThreadPool
com.alibaba.dubbo.common.threadpool.support.fixed.FixedThreadPool ,实现 ThreadPool 接口,固定大小线程池,启动时建立线程,不关闭,一直持有。代码如下:
```plain text
plain 1: public class FixedThreadPool implements ThreadPool { 2: 3: @Override 4: public Executor getExecutor(URL url) { 5: // 线程名 6: String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME); 7: // 线程数 8: int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS); 9: // 队列数 10: int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES); 11: // 创建执行器 12: return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS, 13: queues == 0 ? new SynchronousQueue<Runnable>() : 14: (queues < 0 ? new LinkedBlockingQueue<Runnable>() 15: : new LinkedBlockingQueue<Runnable>(queues)), 16: new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url)); 17: } 18: 19: }
- 第 5 至 10 行:获得线程名、线程数、队列数。目前只有服务提供者使用,配置方式如下:
```plain text plain
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
---
- 第 11 至 16 行:创建执行器 ThreadPoolExecutor 对象。
- 根据不同的队列数,使用不同的队列实现:
- 第 13 行:
queues == 0
, SynchronousQueue 对象。
- 第 14 行:
queues < 0
, LinkedBlockingQueue 对象。
- 第 15 行:
queues > 0
,带队列数的 LinkedBlockingQueue 对象。
- 推荐阅读:
- [《Java并发包中的同步队列SynchronousQueue实现原理》](http://ifeve.com/java-synchronousqueue/)
- [《Java阻塞队列ArrayBlockingQueue和LinkedBlockingQueue实现原理分析》](https://fangjian0423.github.io/2016/05/10/java-arrayblockingqueue-linkedblockingqueue-analysis/)
- [《聊聊并发(三)——JAVA线程池的分析和使用》](http://www.infoq.com/cn/articles/java-threadPool)
- [《聊聊并发(七)——Java中的阻塞队列》](http://www.infoq.com/cn/articles/java-blocking-queue)
- 第 16 行:创建 [NamedThreadFactory](https://github.com/apache/incubator-dubbo/blob/bb8884e04433677d6abc6f05c6ad9d39e3dcf236/dubbo-common/src/main/java/com/alibaba/dubbo/common/utils/NamedThreadFactory.java)**线程名**
对象,用于生成
。
- 第 16 行:创建 AbortPolicyWithReport 对象,用于**当任务添加到线程池中被拒绝时**
。
## 2.2 CachedThreadPool
com.alibaba.dubbo.common.threadpool.support.cached.CachedThreadPool ,实现 ThreadPool 接口,缓存线程池,空闲一定时长,自动删除,需要时重建。代码如下:
```plain text
plain 1: public class CachedThreadPool implements ThreadPool { 2: 3: @Override 4: public Executor getExecutor(URL url) { 5: // 线程池名 6: String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME); 7: // 核心线程数 8: int cores = url.getParameter(Constants.CORE_THREADS_KEY, Constants.DEFAULT_CORE_THREADS); 9: // 最大线程数 10: int threads = url.getParameter(Constants.THREADS_KEY, Integer.MAX_VALUE); 11: // 队列数 12: int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES); 13: // 线程存活时长 14: int alive = url.getParameter(Constants.ALIVE_KEY, Constants.DEFAULT_ALIVE); 15: // 创建执行器 16: return new ThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS, 17: queues == 0 ? new SynchronousQueue<Runnable>() : 18: (queues < 0 ? new LinkedBlockingQueue<Runnable>() 19: : new LinkedBlockingQueue<Runnable>(queues)), 20: new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url)); 21: } 22: 23: }
- 第 5 至 14 行:获得线程名、核心线程数、最大线程数、队列数、线程存活时长。
- 配置方式和 FixedThreadPool 类似,使用 配置。
- 第 16 至 20 行:创建执行器 ThreadPoolExecutor 对象。
- 和 FixedThreadPool 相对类似。
2.3 LimitedThreadPool
com.alibaba.dubbo.common.threadpool.support.limited.LimitedThreadPool ,实现 ThreadPool 接口,可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。代码如下:
```plain text plain 1: public class LimitedThreadPool implements ThreadPool { 2: 3: @Override 4: public Executor getExecutor(URL url) { 5: // 线程名 6: String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME); 7: // 核心线程数 8: int cores = url.getParameter(Constants.CORE_THREADS_KEY, Constants.DEFAULT_CORE_THREADS); 9: // 最大线程数 10: int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS); 11: // 队列数 12: int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES); 13: // 创建执行器 14: return new ThreadPoolExecutor(cores, threads, Long.MAX_VALUE, TimeUnit.MILLISECONDS, 15: queues == 0 ? new SynchronousQueue
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
---
- 和 CachedThreadPool 实现是基本一致的,差异点在 **空闲时间无限大**
alive == Integer.MAX_VALUE
,
,即不会自动删除。
# 3. AbortPolicyWithReport
com.alibaba.dubbo.common.threadpool.support.AbortPolicyWithReport ,实现 java.util.concurrent.ThreadPoolExecutor.AbortPolicy ,拒绝策略实现类。**打印 JStack ,分析线程状态**。
## 3.1 属性
```plain text
plain /** * 线程名 */ private final String threadName; /** * URL 对象 */ private final URL url; /** * 最后打印时间 */ private static volatile long lastPrintTime = 0; /** * 信号量,大小为 1 。 */ private static Semaphore guard = new Semaphore(1); public AbortPolicyWithReport(String threadName, URL url) { this.threadName = threadName; this.url = url; }
3.2 rejectedExecution
#rejectedExecution(Runnable, ThreadPoolExecutor)实现方法,代码如下:
```plain text plain 1: @Override 2: public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { 3: // 打印告警日志 4: String msg = String.format(“Thread pool is EXHAUSTED!” + 5: “ Thread Name: %s, Pool Size: %d (active: %d, core: %d, max: %d, largest: %d), Task: %d (completed: %d),” + 6: “ Executor status:(isShutdown:%s, isTerminated:%s, isTerminating:%s), in %s://%s:%d!”, 7: threadName, e.getPoolSize(), e.getActiveCount(), e.getCorePoolSize(), e.getMaximumPoolSize(), e.getLargestPoolSize(), 8: e.getTaskCount(), e.getCompletedTaskCount(), e.isShutdown(), e.isTerminated(), e.isTerminating(), 9: url.getProtocol(), url.getIp(), url.getPort()); 10: logger.warn(msg); 11: // 打印 JStack ,分析线程状态。 12: dumpJStack(); 13: // 抛出 RejectedExecutionException 异常 14: throw new RejectedExecutionException(msg); 15: }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
---
- 第 3 至 10 行:打印**告警日志**
。
- 第 12 行:调用 **JStack**
#dumpJStack()
方法,打印
,分析线程状态。
- 第 14 行:抛出 RejectedExecutionException 异常。
## 3.3 dumpJStack
#dumpJStack() 方法,打印 JStack。代码如下:
```plain text
plain 1: private void dumpJStack() { 2: long now = System.currentTimeMillis(); 3: 4: // 每 10 分钟,打印一次。 5: // dump every 10 minutes 6: if (now - lastPrintTime < 10 * 60 * 1000) { 7: return; 8: } 9: 10: // 获得信号量 11: if (!guard.tryAcquire()) { 12: return; 13: } 14: 15: // 创建线程池,后台执行打印 JStack 16: Executors.newSingleThreadExecutor().execute(new Runnable() { 17: @Override 18: public void run() { 19: 20: // 获得系统 21: String OS = System.getProperty("os.name").toLowerCase(); 22: // 获得路径 23: String dumpPath = url.getParameter(Constants.DUMP_DIRECTORY, System.getProperty("user.home")); 24: SimpleDateFormat sdf; 25: // window system don't support ":" in file name 26: if(OS.contains("win")){ 27: sdf = new SimpleDateFormat("yyyy-MM-dd_HH-mm-ss"); 28: }else { 29: sdf = new SimpleDateFormat("yyyy-MM-dd_HH:mm:ss"); 30: } 31: String dateStr = sdf.format(new Date()); 32: // 获得输出流 33: FileOutputStream jstackStream = null; 34: try { 35: jstackStream = new FileOutputStream(new File(dumpPath, "Dubbo_JStack.log" + "." + dateStr)); 36: // 打印 JStack 37: JVMUtil.jstack(jstackStream); 38: } catch (Throwable t) { 39: logger.error("dump jstack error", t); 40: } finally { 41: // 释放信号量 42: guard.release(); 43: // 释放输出流 44: if (jstackStream != null) { 45: try { 46: jstackStream.flush(); 47: jstackStream.close(); 48: } catch (IOException e) { 49: } 50: } 51: } 52: // 记录最后打印时间 53: lastPrintTime = System.currentTimeMillis(); 54: } 55: }); 56: 57: }
- 第 2 至 8 行:每 10 分钟,只 打印一次。
- 第 10 至 13 行:获得信号量。保证,同一时间,有且仅有 一个线程执行打印。
- 第 15 至 54 行:创建线程池,后台 执行打印 JStack 。
- 第 20 至 31 行:获得路径。
- 第 32 至 35 行:获得文件输出流。
- 第 37 行:调用 JVMUtil#jstack(OutputStream) 方法,打印 JStack 。
- 第 42 行:释放信号量。
- 第 44 至 50 行:释放输出流。
- 第 53 行:记录最后打印时间。
4. JVMUtil
com.alibaba.dubbo.common.utils.JVMUtil ,JVM 工具类。目前,仅有 JStack 功能,胖友可以点击链接,自己查看下代码。
如下是一个 JStack 日志的示例:
plain text plain 123312:tmp yunai$ cat Dubbo_JStack.log.2018-03-27_18\:57\:32 "pool-2-thread-1" Id=11 RUNNABLE at sun.management.ThreadImpl.dumpThreads0(Native Method) at sun.management.ThreadImpl.dumpAllThreads(ThreadImpl.java:454) at com.alibaba.dubbo.common.utils.JVMUtil.jstack(JVMUtil.java:34) at com.alibaba.dubbo.common.threadpool.support.AbortPolicyWithReport$1.run(AbortPolicyWithReport.java:122) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617) at java.lang.Thread.run(Thread.java:745) Number of locked synchronizers = 1 - java.util.concurrent.ThreadPoolExecutor$Worker@5cbc508c "Monitor Ctrl-Break" Id=5 RUNNABLE (in native) at java.net.SocketInputStream.socketRead0(Native Method) at java.net.SocketInputStream.socketRead(SocketInputStream.java:116) at java.net.SocketInputStream.read(SocketInputStream.java:171) at java.net.SocketInputStream.read(SocketInputStream.java:141) at sun.nio.cs.StreamDecoder.readBytes(StreamDecoder.java:284) at sun.nio.cs.StreamDecoder.implRead(StreamDecoder.java:326) at sun.nio.cs.StreamDecoder.read(StreamDecoder.java:178) - locked java.io.InputStreamReader@5c7efb52 at java.io.InputStreamReader.read(InputStreamReader.java:184) at java.io.BufferedReader.fill(BufferedReader.java:161) at java.io.BufferedReader.readLine(BufferedReader.java:324) - locked java.io.InputStreamReader@5c7efb52 at java.io.BufferedReader.readLine(BufferedReader.java:389) at com.intellij.rt.execution.application.AppMainV2$1.run(AppMainV2.java:64) "Signal Dispatcher" Id=4 RUNNABLE "Finalizer" Id=3 WAITING on java.lang.ref.ReferenceQueue$Lock@197c6eb9 at java.lang.Object.wait(Native Method) - waiting on java.lang.ref.ReferenceQueue$Lock@197c6eb9 at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143) at java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:164) at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:209) "Reference Handler" Id=2 WAITING on java.lang.ref.Reference$Lock@7b19fa34 at java.lang.Object.wait(Native Method) - waiting on java.lang.ref.Reference$Lock@7b19fa34 at java.lang.Object.wait(Object.java:502) at java.lang.ref.Reference.tryHandlePending(Reference.java:191) at java.lang.ref.Reference$ReferenceHandler.run(Reference.java:153) "main" Id=1 TIMED_WAITING at java.lang.Thread.sleep(Native Method) at com.alibaba.dubbo.common.threadpool.AbortPolicyWithReportTest.jStackDumpTest(AbortPolicyWithReportTest.java:44) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:50) at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12) at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:47) at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17) at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:325) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:78) at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:57) at org.junit.runners.ParentRunner$3.run(ParentRunner.java:290) at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:71) at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:288) at org.junit.runners.ParentRunner.access$000(ParentRunner.java:58) at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:268) at org.junit.runners.ParentRunner.run(ParentRunner.java:363) at org.junit.runner.JUnitCore.run(JUnitCore.java:137) at com.intellij.junit4.JUnit4IdeaTestRunner.startRunnerWithArgs(JUnit4IdeaTestRunner.java:68) at com.intellij.rt.execution.junit.IdeaTestRunner$Repeater.startRunnerWithArgs(IdeaTestRunner.java:47) at com.intellij.rt.execution.junit.JUnitStarter.prepareStreamsAndStart(JUnitStarter.java:242) at com.intellij.rt.execution.junit.JUnitStarter.main(JUnitStarter.java:70)
另外,胖友可以看看 《如何使用jstack分析线程状态》 文章。