从文件read_write一个字节的过程和所发生的磁盘IO
从文件read/write一个字节的过程和所发生的磁盘IO
IO时(不管是磁盘IO还是网络IO)的过程整体上看有两个操作(write过程与read过程相反):
- 将数据从外设读入内核态内存,如从网卡读入到内存Ring Buffer。此过程为DMA read,不需要CPU参与,完成后通过中断通知CPU。我们通常说IO操作耗时,就是这步耗时。
- 从内核态内存复制到用户态内存(通常就是应用程序进程的内存)。此过程为CPU read,需要CPU参与。之所以要有这一步而不是将外设数据直接复制到用户态内存,是因为OS出于安全考虑不允许用户态应用程序直接访问IO设备。
但深入追究的话该过程实际上相当复杂,概要图如下:
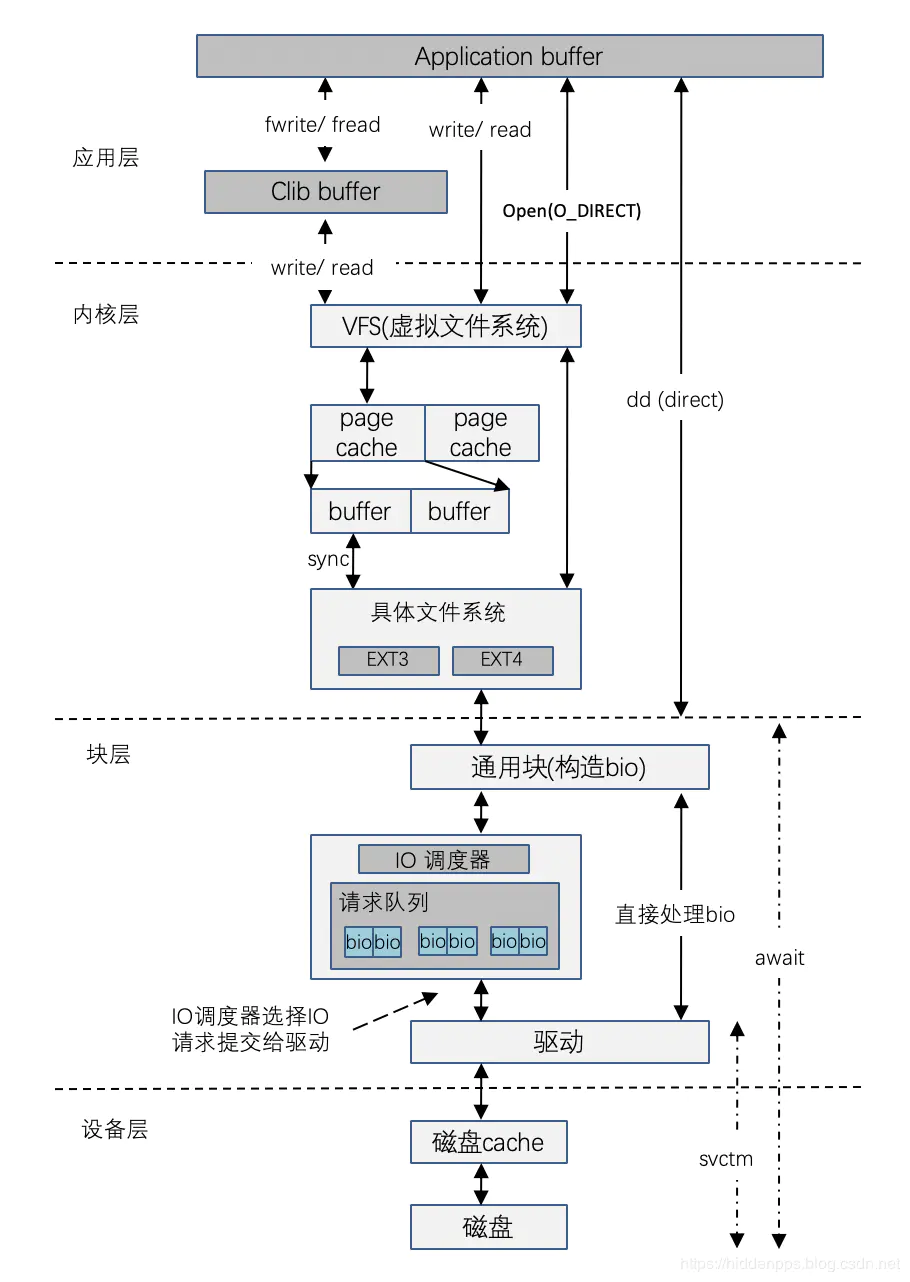
详见下文。
读过程概要:
note:
OS支持多种文件系统,一个磁盘上可以有多个分区,每个分区可以格式化成一种文件系统,不同分区格式化成的文件系统可以不一致;OD提供了虚拟文件系统(VFS)以屏蔽对不同文件系统的访问,页缓存(PageCache)位于VFS和实际的FS之间。
磁盘自身数据读取以扇区(通常为512B)为单位、文件系统以块block(通常为4KB)为单位管理数据、PageCache以页Page为单位(通常为4KB)管理数据。可见:
一次磁盘IO的数据有多少?虽然用户只需要一个字节,但实际上至少一页(即8扇区)的数据会被从磁盘读取到内存PageCache(即使只需要一个字节);
是否一定会有磁盘IO?PageCache在内存中暂存这些Page,若下一次访问时PageCache中存在需要的数据则直接从内存取而不需要读磁盘,因此,由于PageCache的存在,读取文件一个字节并不一定会导致磁盘IO。
从上述过程看,若写数据时写入到了PageCache,则此时用户的写磁盘操作从效果上看是异步的。
详情参阅文章 read 文件一个字节实际会发生多大的磁盘IO
read文件一个字节实际会发生多大的磁盘IO?
不管你用的是啥语言,C/PHP/GO、还是Java,相信大家都有过读取文件的经历。我们来思考两个问题,如果我们读取文件中的一个字节:
- 是否会发生磁盘IO?
- 发生的话,Linux实际向磁盘读取多少字节了呢?
为了便于理解问题,我们把c的代码也列出来:
```plain text int main() { char c; int in;
1
2
3
in = open("in.txt", O_RDONLY);
read(in,&c,1);
return 0; } ```
如果不是从事c/c++开发工作的同学,这个问题想深度理解起来确实不那么容易。因为目前常用的主流语言,PHP/Java/Go啥的封装层次都比较高,把内核的很多细节都给屏蔽的比较彻底。要想把上面的两个问题搞的比较清楚,需要剖开Linux的内部来理解Linux的IO栈。
Linux IO栈简介
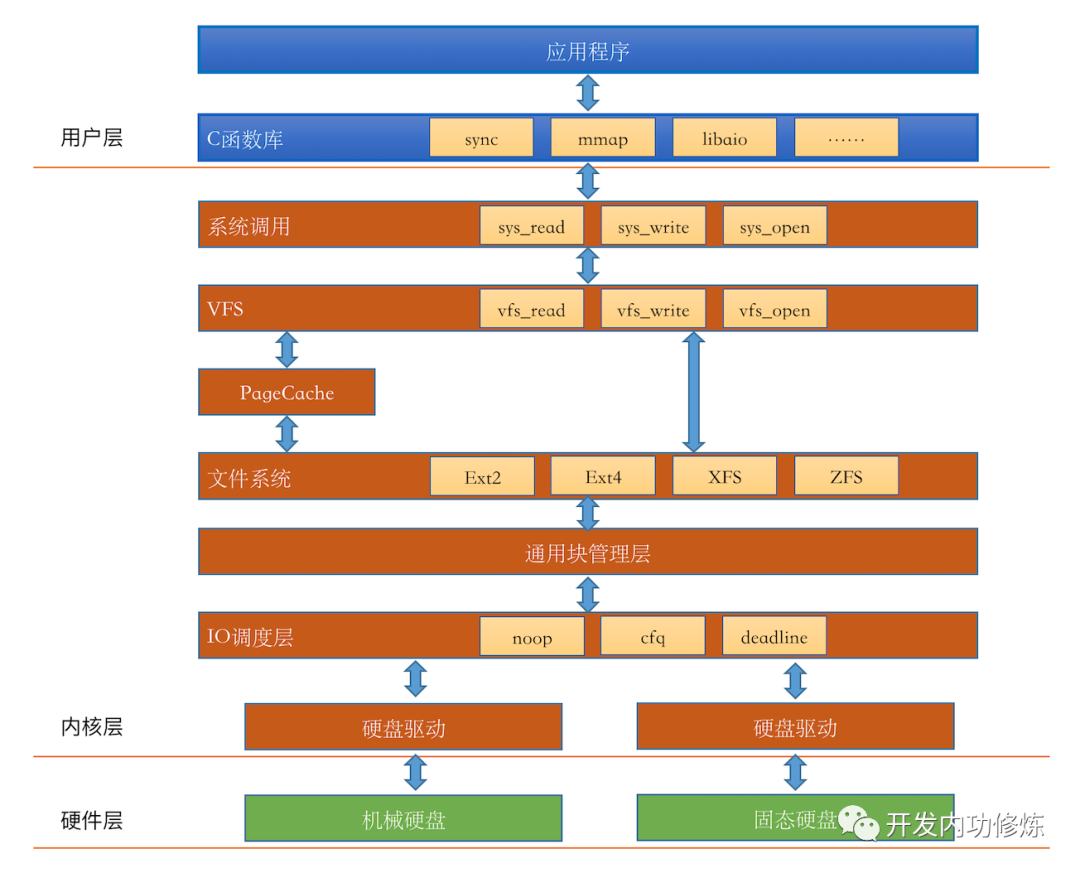
废话不多说,我们直接把Linux IO栈的一个简化版本画出来:(官方的IO栈参考这个
图1 Linux硬盘IO栈
我们在前面也分享了几篇文章讨论了上图图中的硬件层,还有文件系统模块。但通过这个IO栈我们发现,我们对Linux文件的IO的理解还是远远不够,还有好几个内核组件:IO引擎、VFS、PageCache、通用块管理层、IO调度层等模块我们并没有了解太多。别着急,让我们一一道来:
1. IO引擎
我们开发同学想要读写文件的话,在lib库层有很多种函数可以选择,比如read,write,mmap等。这事实上就是在选择Linux提供的IO引擎。我们最常用的read、write函数是属于sync引擎,除了sync,还有map、psync、vsync、libaio、posixaio等。 sync,psync都属于同步方式,libaio和posixaio属于异步IO。
当然了IO引擎也需要VFS、通用块层等更底层的支持才能实现。在sync引擎的read函数里会进入VFS提供的read系统调用。
2. VFS虚拟文件系统
在内核层,第一个看到的是VFS。VFS诞生的思想是抽象一个通用的文件系统模型,对我们开发人员或者是用户提供一组通用的接口,让我们不用care具体文件系统的实现。VFS提供的核心数据结构有四个,它们定义在内核源代码的include/linux/fs.h和include/linux/dcache.h中。
- superblock:Linux用来标注具体已安装的文件系统的有关信息
- inode:Linux中的每一个文件都有一个inode,你可以把inode理解为文件的身份证
- file:内存中的文件对象,用来保存进程和磁盘文件的对应关系
- desty:目录项,是路径中的一部分,所有的目录项对象串起来就是一棵Linux下的目录树。
围绕这这四个核心数据结构,VFS也都定义了一系列的操作方法。比如,inode的操作方法定义inode_operations(include/linux/fs.h),在它的里面定义了我们非常熟悉的mkdir和rename等。
1
2
3
4
5
6
7
8
9
struct inode_operations {
......
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*mkdir) (struct inode *,struct dentry *,umode_t);
int (*rmdir) (struct inode *,struct dentry *);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *, unsigned int);
......
在file对应的操作方法file_operations里面定义了我们经常使用的read和write:
1
2
3
4
5
6
7
8
struct file_operations {
......
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
......
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
3. Page Cache
在VFS层往下看,我们注意到了Page Cache。它的中文译名叫页高速缓存,是Linux内核使用的主要磁盘高速缓存,是一个纯内存的工作组件,其作用就是来给访问相对比较慢的磁盘来进行访问加速。如果要访问的文件block正好存在于Page Cache内,那么并不会有实际的磁盘IO发生。如果不存在,那么会申请一个新页,发出缺页中断,然后用磁盘读取到的block内容来填充它 ,下次直接使用。Linux内核使用搜索树来高效管理大量的页面。
如果你有特殊的需求想要绕开Page Cache,只要设置DIRECT_IO就可以了。有两种情况需要绕开:
- 测试磁盘IO的真实性能
- 节约使用Page Cache时系统调用陷入到内核态,以及内核内存向用户进程内存拷贝到开销。
4. 文件系统
在我在之前的文章《新建一个空文件占用多少磁盘空间?》、《理解格式化原理》里讨论的都是具体的文件系统。文件系统里最重要的两个概念就是inode和block,这两个我们在之前的文章里也都见过了。一个block是多大呢,这是运维在格式化的时候决定的,一般默认是4KB。
除了inode和block,每个文件系统还会定义自己的实际操作函数。例如在ext4中定义的ext4_file_operations和ext4_file_inode_operations如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
const struct file_operations ext4_file_operations = {
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
.mmap = ext4_file_mmap,
.open = ext4_file_open,
......
};
const struct inode_operations ext4_file_inode_operations = {
.setattr = ext4_setattr,
.getattr = ext4_file_getattr,
......
};
5. 通用块层
通用块层是一个处理系统中所有块设备IO请求的内核模块。它定义了一个叫bio的数据结构来表示一次IO操作请求(include/linux/bio.h)。
那么一次bio里对应的IO大小单位是页面,还是扇区呢?都不是,是段!每个bio可能会包含多个段。一个段是一个完整的页面,或者是页面的一部分,具体请参考https://www.ilinuxkernel.com/files/Linux.Generic.Block.Layer.pdf。
为什么要搞出个段这么让人费解的东西呢?这是因为在磁盘中连续存储的数据,到了内存Page Cache里的时候可能内存并不连续了。这种状况出现是正常的,不能说磁盘中连续的数据我在内存中就非得用连续的空间来缓存。段就是为了能让一次磁盘IO能DMA到多“段”地址并不连续的内存中的。
一个常见的扇区/段/页的大小对比如下图:
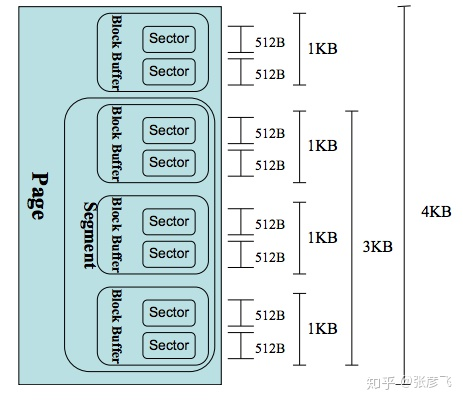
图2 Linux的页/段/扇区的关系示例
6. IO调度层
当通用块层把IO请求实际发出以后,并不一定会立即被执行。因为调度层会从全局出发,尽量让整体磁盘IO性能最大化。大致的工作方式是让磁头类似电梯那样工作,先往一个方向走,到头再回来,这样磁盘效率会比较高一些。具体的算法有noop,deadline和cfg等。
| 在你的机器上,通过dmesg | grep -i scheduler来查看你的Linux支持的算法,并在测试的时候可以选择其中的一种。 |
读文件过程
我们已经把Linux IO栈里的各个内核组件都介绍一边了。现在我们再从头整体过一下读取文件的过程
- lib里的read函数首先进入系统调用sys_read
- 在sys_read再进入VFS里的vfs_read、generic_file_read等函数
- 在vfs里的generic_file_read会判断是否缓存命中,命中则返回
- 若不命中内核在Page Cache里分配一个新页框,发出缺页中断,
- 内核向通用块层发起块I/O请求,块设备屏蔽了磁盘、U盘的差异
- 通用块层把用bio代表的I/O请求放到IO请求队列中
- IO调度层通过电梯算法来调度队列中的请求
- 驱动程序向磁盘控制器发出读取命令控制,DMA方式直接填充到Page Cache中的新页框
- 控制器发出中断通知
- 内核将用户需要的1个字节填充到用户内存中
- 然后你的进程被唤醒
可以看到,如果Page Cache命中的话,根本就没有磁盘IO产生。所以,大家不要觉得代码里出现几个读写文件的逻辑就觉得性能会慢的不行。操作系统已经替你优化了很多很多,内存级别的访问延迟大约是ns级别的,比机械磁盘IO快了几个数量级。如果你的内存足够大,或者你的文件被访问的足够频繁,其实这时候的read操作极少有真正的磁盘IO发生。
我们再看第二种情况,如果Page Cache不命中的话,Linux实际进行了多少个字节的磁盘IO。整个IO过程中涉及到了好几个内核组件。 而每个组件之间都是采用不同长度的块来管理磁盘数据的。
- Page Cache是以页为单位的,Linux页大小一般是4KB(避免有大神挑刺,这里说下Linux能设置大内存页)
- 文件系统是以块为单位来管理的。使用 dumpe2fs 可以查看,一般一个块默认是4KB
- 通用块层是以段为单位来处理磁盘IO请求的,一个段为一个页或者是页的一部分
- IO调度程序通过DMA方式传输N个扇区到内存,扇区一般为512字节
- 硬盘也是采用“扇区”的管理和传输数据的
可以看到,虽然我们从用户角度确实是只读了1个字节(开篇的代码中我们只给这次磁盘IO留了一个字节的缓存区)。但是在整个内核工作流中,最小的工作单位是磁盘的扇区,为512字节,比1个字节要大的多。另外block、page cache等高层组件工作单位更大,所以实际一次磁盘读取是很多字节一起进行的。假设段就是一个内存页的话,一次磁盘IO就是4KB(8个512字节的扇区)一起进行读取。
Linux内核中我们没有讲到的是还有一套复杂的预读取的策略。所以,在实践中,可能比8更多的扇区来一起被传输到内存中。
最后
操作系统的本意是做到让你简单可依赖, 让你尽量把它当成一个黑盒。你想要一个字节,它就给你一个字节,但是自己默默干了许许多多的活儿。我们虽然国内绝大多数开发都不是搞底层的,但如果你十分关注你的应用程序的性能,你应该明白操作系统的什么时候悄悄提高了你的性能,是怎么来提高的。以便在将来某一个时候你的线上服务器扛不住快要挂掉的时候,你能迅速找出问题所在。
我们再扩展一下,假如Page Cache没有命中,那么一定会有传动到机械轴上的磁盘IO吗?
其实也不一定,为什么,因为现在的磁盘本身就会带一块缓存。另外现在的服务器都会组建磁盘阵列,在磁盘阵列里的核心硬件Raid卡里也会集成RAM作为缓存。只有所有的缓存都不命中的时候,机械轴带着磁头才会真正工作。
read文件一个字节实际会发生多大的磁盘IO?
写过程概要:
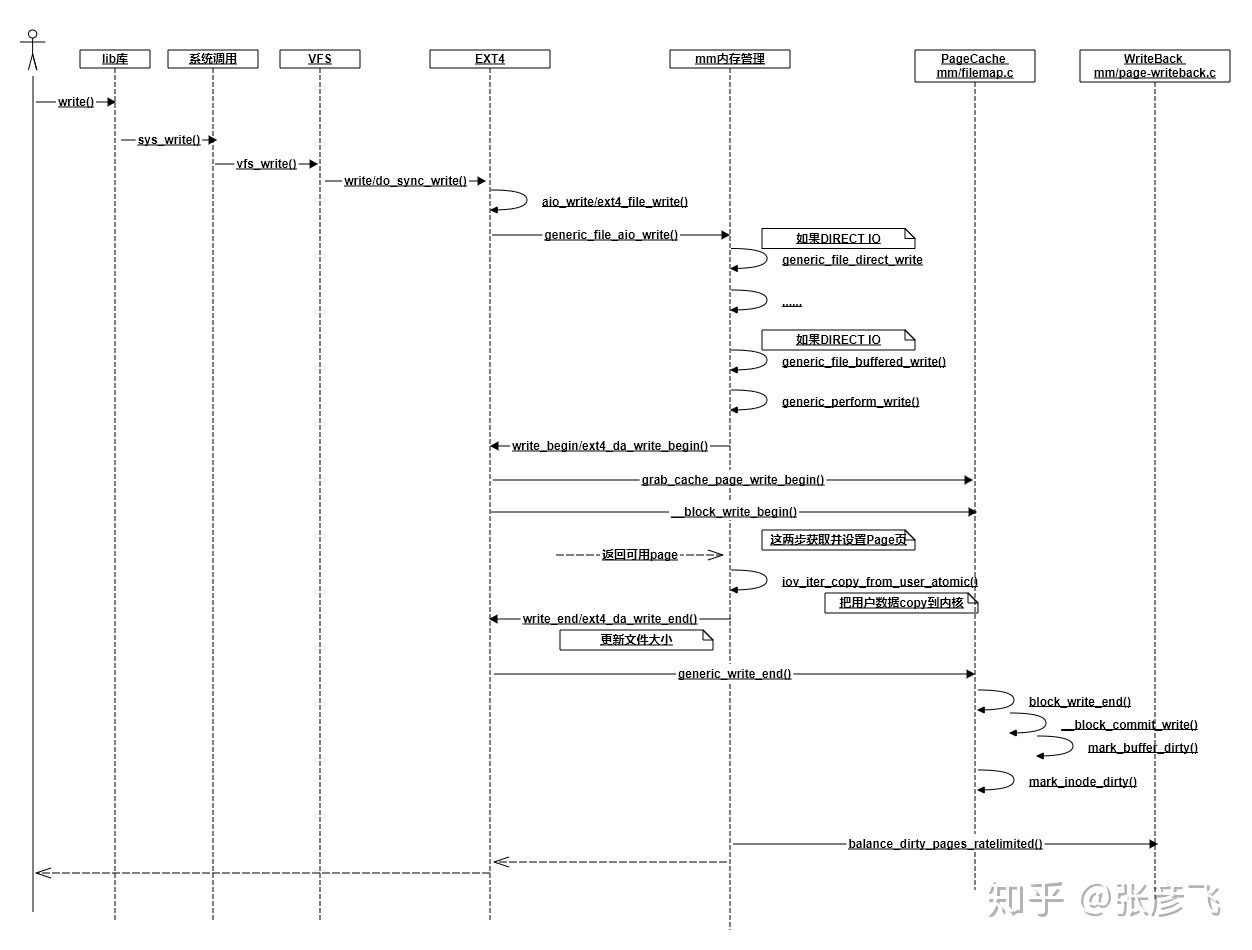
note:
写的过程与读类似,先后经历 用户态写、系统调用写、VFS系统写、写PageCache、实际FS写、磁盘驱动写 等过程。
有多种写的方法,如同步写、异步写等,区别在于写方法是否等数据真正写入磁盘才返回。对于异步写,数据写入PageCache(此时该PageCache称为脏页)写方法就立即返回。
脏页数据由内核Worker线程周期性地扫描,将符合条件(脏页数据的 比例达到阈值、总量达到阈值、存在时间达到阈值 至少一个,阈值可配置)的脏页数据持久化到磁盘,这才是真正的“写”。持久化的时机:
```plain text 数据会在如下三个时机下被真正发起写磁盘IO请求: 第一种情况,如果write系统调用时,如果发现PageCache中脏页占比太多,超过了dirty_ratio或dirty_bytes,write就必须等待了。 第二种情况,write写到PageCache就已经返回了。worker内核线程异步运行的时候,再次判断脏页占比,如果超过了dirty_background_ratio或dirty_background_bytes,也发起写回请求。 第三种情况,这时同样write调用已经返回了。worker内核线程异步运行的时候,虽然系统内脏页一直没有超过dirty_background_ratio或dirty_background_bytes,但是脏页在内存中呆的时间超过dirty_expire_centisecs了,也会发起会写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
由于PageCache位于内存,而异步写时会优先考虑往PageCache写,故异步写的效率很高;但也由于PageCache在内存,发生断电等异常情况时数据可能还没来得及持久化,故数据可能丢失。
现在我想搞明白的问题是,在最常用的方式下,不开O_DIRECT、不开O_SYNC(写文件的方法有很多,有sync模式、direct模式、mmap内存映射模式),write是怎么写的。c的代码示例如下:
```c
#include <fcntl.h>
int main()
{
char c = 'a';
int out;
out = open("out.txt", O_WRONLY | O_CREAT | O_TRUNC);
write(out,&c,1);
...
}
进一步细化我的问题,我们对打开的文件写入一个字节后
- write函数在内核里是怎么执行的?
- 数据在什么时机真正能写入到磁盘上?
我们在讨论的过程中不可避免地要涉及到内核代码,我使用的内核版本是3.10.1。如果有需要,你可以到这里来下载。https://mirrors.edge.kernel.org/pub/linux/kernel/v3.x/。
write函数实现剖析
我花了不短的时候跟踪write写到ext4文件系统时的各种调用和返回,大致理出来了一个交互图。当然为了突出重点,我抛弃了不少细节,比如DIRECT IO、ext4日志记录啥的都没有体现出来,只抽取出来了一些我认为关键的调用。
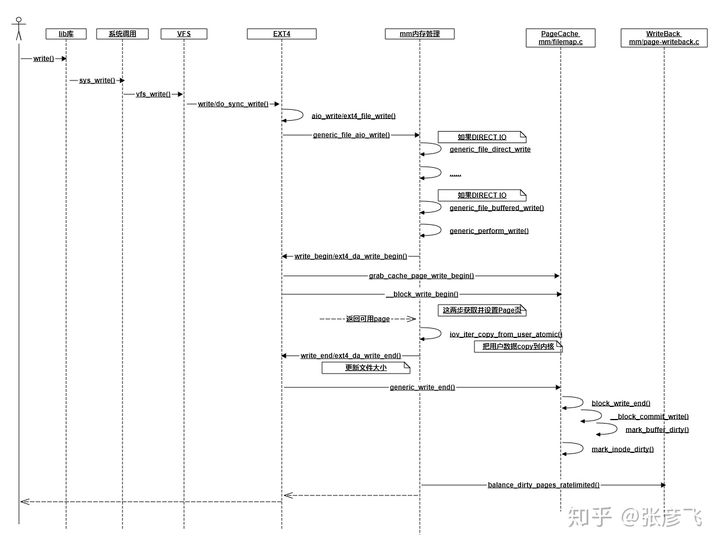
图1 write函数内部实现
在上面的流程图里,所有的写操作最终到哪儿了呢?在最后面的_block_commit_write中,只是make dirty。然后大部分情况下你的函数调用就返回了(稍后再说balancedirty_pages_ratelimited)。数据现在还在内存中的PageCache里,并没有真正写到硬盘。
为什么要这样实现,不直接写硬盘呢?原因就在于硬盘尤其是机械硬盘,性能是在是太慢了。一块服务器级别的万转盘,最坏随机访问平均延迟都是毫秒级别的,换算成IOPS只有100多不到200。设想一下,假如你的后端接口里每个用户来访问都需要一次随机磁盘IO,不管你多牛的服务器,每秒200的qps都将直接打爆你的硬盘,相信作为为百万/千万/过亿用户提供接口的你,这个是你绝对不能忍的。
Linux这么搞也是有副作用的,如果接下来服务器发生掉电,内存里东西全丢。所以Linux还有另外一个“补丁”-延迟写,帮我们缓解这个问题。注意下,我说的是缓解,并没有彻底解决。
再说下balance_dirty_pages_ratelimited,虽然绝大部分情况下,都是直接写到Page Cache里就返回了。但在一种情况下,用户进程必须得等待写入完成才可以返回,那就是对balance_dirty_pages_ratelimited的判断如果超出限制了。该函数判断当前脏页是否已经超过脏页上限dirty_bytes、dirty_ratio,超过了就必须得等待。这两个参数只有一个会生效,另外1个是0。拿dirty_ratio来说,如果设置的是30,就说明如果脏页比例超过内存的30%,则write函数调用就必须等待写入完成才能返回。可以在你的机器下的/proc/sys/vm/目录来查看这两个配置。
1
2
3
4
# cat /proc/sys/vm/dirty_bytes
0
# cat /proc/sys/vm/dirty_ratio
30
内核延迟写
内核是什么时候真正把数据写到硬盘中呢?为了快速摸清楚全貌,我想到的办法是用systemtap工具,找到内核写IO过程中的一个关键函数,然后在其中把函数调用堆栈打出来。查了半天资料以后,我决定用do_writepages这个函数。
```plain text #!/usr/bin/stap probe kernel.function(“do_writepages”) { printf(“——————————————————–\n”); print_backtrace(); printf(“——————————————————–\n”); }
1
2
3
4
5
6
7
8
9
10
11
12
13
14
systemtab跟踪以后,打印信息如下:
```plain text
0xffffffff8118efe0 : do_writepages+0x0/0x40 [kernel]
0xffffffff8122d7d0 : __writeback_single_inode+0x40/0x220 [kernel]
0xffffffff8122e414 : writeback_sb_inodes+0x1c4/0x490 [kernel]
0xffffffff8122e77f : __writeback_inodes_wb+0x9f/0xd0 [kernel]
0xffffffff8122efb3 : wb_writeback+0x263/0x2f0 [kernel]
0xffffffff8122f35c : bdi_writeback_workfn+0x1cc/0x460 [kernel]
0xffffffff810a881a : process_one_work+0x17a/0x440 [kernel]
0xffffffff810a94e6 : worker_thread+0x126/0x3c0 [kernel]
0xffffffff810b098f : kthread+0xcf/0xe0 [kernel]
0xffffffff816b4f18 : ret_from_fork+0x58/0x90 [kernel]
从上面的输出我们可以看出,真正的写文件过程操作是由worker内核线程发出来的(和我们自己的应用程序进程没有半毛钱关系,此时我们的应用程序的write函数调用早就返回了)。这个worker线程写回是周期性执行的,它的周期取决于内核参数dirty_writeback_centisecs的设置,根据参数名也大概能看出来,它的单位是百分之一秒。
```plain text
cat /proc/sys/vm/dirty_writeback_centisecs
500
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
我查看到我的配置是500,就是说每5秒会周期性地来执行一遍。回顾我们的问题,我们最关心的问题的啥时候写入的,围绕这个思路不过多发散。于是沿着这个调用栈不断地跟踪,跳转,终于找到了下面的代码。如下代码里我们看到,如果是for_background模式,且over_bground_thresh判断成功,就会开始回写了。
```plain text
static long wb_writeback(struct bdi_writeback *wb,
struct wb_writeback_work *work)
{
work->older_than_this = &oldest_jif;
...
if (work->for_background && !over_bground_thresh(wb->bdi))
break;
...
if (work->for_kupdate) {
oldest_jif = jiffies -
msecs_to_jiffies(dirty_expire_interval * 10);
} else ...
}
static long wb_check_background_flush(struct bdi_writeback *wb)
{
if (over_bground_thresh(wb->bdi)) {
...
return wb_writeback(wb, &work);
}
}
那么over_bground_thresh函数判断的是啥呢?其实就是判断当前的脏页是不是超过内核参数里dirty_background_ratio或dirty_background_bytes的配置,没超过的话就不写了(代码位于fs/fs-writeback.c:1440,限于篇幅我就不贴了)。这两个参数只有一个会真正生效,其中dirty_background_ratio配置的是比例、dirty_background_bytes配置的是字节。
在我的机器上的这两个参数配置如下,表示脏页比例超过10%就开始回写。
```plain text
cat /proc/sys/vm/dirty_background_bytes
0
cat /proc/sys/vm/dirty_background_ratio
10
1
2
3
4
5
6
7
8
9
10
11
12
那如果脏页一直都不超过这个比例怎么办呢,就不写了吗? 不是的。在上面的wb_writeback函数中我们看到了,如果是for_kupdate模式,会记录一个过期标记到work->older_than_this,再往后面的代码中把符合这个过期条件的页面也写回了。dirty_expire_interval这个变量是从哪儿来的呢? 在kernel/sysctl.c里,我们发现了蛛丝马迹。哦,原来它是来自/proc/sys/vm/dirty_expire_centisecs这个配置。
```plain text
1158 {
1159 .procname = "dirty_expire_centisecs",
1160 .data = &dirty_expire_interval,
1161 .maxlen = sizeof(dirty_expire_interval),
1162 .mode = 0644,
1163 .proc_handler = proc_dointvec_minmax,
1164 .extra1 = &zero,
1165 },
在我的机器上,它的值是3000。单位是百分之一秒,所以就是脏页过了30秒就会被内核线程认为需要写回到磁盘了。
```plain text
cat /proc/sys/vm/dirty_expire_centisecs
3000 ```
结论
我们demo代码中的写入,其实绝大部分情况都是写入到PageCache中就返回了,这时并没有真正写入磁盘。我们的数据会在如下三个时机下被真正发起写磁盘IO请求:
- 第一种情况,如果write系统调用时,如果发现PageCache中脏页占比太多,超过了dirty_ratio或dirty_bytes,write就必须等待了。
- 第二种情况,write写到PageCache就已经返回了。worker内核线程异步运行的时候,再次判断脏页占比,如果超过了dirty_background_ratio或dirty_background_bytes,也发起写回请求。
- 第三种情况,这时同样write调用已经返回了。worker内核线程异步运行的时候,虽然系统内脏页一直没有超过dirty_background_ratio或dirty_background_bytes,但是脏页在内存中呆的时间超过dirty_expire_centisecs了,也会发起会写。
如果对以上配置不满意,你可以自己通过修改/etc/sysctl.conf来调整,修改完了别忘了执行sysctl -p。
最后我们要认识到,这套write pagecache+回写的机制第一目标是性能,不是保证不丢失我们写入的数据的。如果这时候掉电,脏页时间未超过dirty_expire_centisecs的就真的丢了。如果你做的是和钱相关非常重要的业务,必须保证落盘完成才能返回,那么你就可能需要考虑使用fsync。