Deepseek 私有化部署
Linux 安装 ollama
自动安装
- 进入官网下载页面
- 一行命令自动下载并安装
curl -fsSLhttps://ollama.com/install.sh| sh
[!tip] 💡 ⚠️需要注意网络问题,直接访问ollama会比较卡,网速很慢,极大可能下载失败。
手动安装
[!tip] 💡 如果您正在从先前的版本中升级,则应首先使用
sudo rm -rf /usr/lib/ollama删除旧库。
1. 确认系统要求
- 操作系统:支持 Ubuntu、Debian、CentOS 等主流 Linux 发行版。
- 依赖:确保已安装
curl和tar工具。
2. 下载 Ollama 安装包
- 访问 Ollama 的官方网站或 GitHub 仓库,获取最新的 Linux 安装包(如
.tar.gz或.deb文件)。 - 使用
curl或wget下载安装包:
1
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
[!warning] ⚠️ 需要注意网络问题,ollama官网下载速度很慢,可以找镜像网站去下载,选择与服务器相匹配的版本。
3. 解压安装包
- 使用
tar解压下载的文件:
1
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
- 启动 Ollama
1
ollama serve
- 新开启一个终端窗口,测试服务是否启动
1
ollama -v
4. 配置为系统服务(可选)
- 为 Ollama 创建用户及用户组
1
2
sudo useradd -r -s /bin/false -U -m -d /usr/share/ollama ollama
sudo usermod -a -G ollama $(whoami)
- 创建 systemd 服务文件
/etc/systemd/system/ollama.service:
1
sudo vim /etc/systemd/system/ollama.service
- 添加以下内容:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=$PATH"
# 自定义监听的端口,默认为:127.0.0.1:11434
#Environment="OLLAMA_HOST=0.0.0.0:11434”
[Install]
WantedBy=default.target
[!tip] 💡 ⚠️默认的ollama配置启动后,仅监听127.0.0.1:11434。需要配置监听范围及监听端口Environment=”OLLAMA_HOST=0.0.0.0:11434”
- 启用并启动服务:
1
2
3
sudo systemctl enable ollama
sudo systemctl start ollama
- 启动Ollama并验证运行状态:
1
2
3
4
# 启动 ollama
sudo systemctl start ollama
# 查看 ollama 运行状态
sudo systemctl status ollama
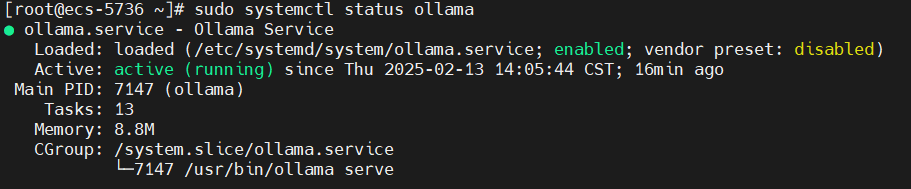
ollama -v 显示:

[!warning] ⚠️ 特别注意:当在
/etc/systemd/system/ollama.service中修改了监听端口后,即使通过systemctl 的方式启动成功,在运行 ollama -v 命令时也会提示无法连接到运行的 ollama 服务上。同时会影响后续下载模型的命令,同样会提示无法连接到 ollama 服务,导致服务下载模型。
5. 自定义
要自定义Ollama的安装,您可以通过运行来编辑Systemd服务文件或环境变量:
1
sudo systemctl edit ollama
或者,手动创建一个覆盖文件 /etc/systemd/system/ollama.service.d/override.conf :
1
2
[Service]
Environment="OLLAMA_DEBUG=1"
6. 更新
通过再次运行安装脚本来更新Ollama:
1
curl -fsSL https://ollama.com/install.sh | sh
或者,重新下载 Ollama 安装包:
1
2
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz
sudo tar -C /usr -xzf ollama-linux-amd64.tgz
[!warning] ⚠️ 需要注意网络问题,ollama官网下载速度很慢,可以找镜像网站去下载,选择与服务器相匹配的版本。
7. 安装特定版本
将Ollama_version环境变量与安装脚本一起安装特定版本的Ollama,包括预释放。
可以从发行版中找到版本号
比如:
1
curl -fsSL https://ollama.com/install.sh | OLLAMA_VERSION=0.5.7 sh
8. 查看运行日志
1
journalctl -e -u ollama
9. 卸载
卸载 ollama 服务:
1
2
3
sudo systemctl stop ollama
sudo systemctl disable ollama
sudo rm /etc/systemd/system/ollama.service
从以下bin目录中删除Ollama二进制文件
- /usr/local/bin
- /usr/bin
- /bin
1
sudo rm $(which ollama)
删除下载的模型和Ollama服务用户和组:
1
2
3
sudo rm -r /usr/share/ollama
sudo userdel ollama
sudo groupdel ollama
删除已安装的库:
1
sudo rm -rf /usr/local/lib/ollama
拉取并安装 DeepSeek
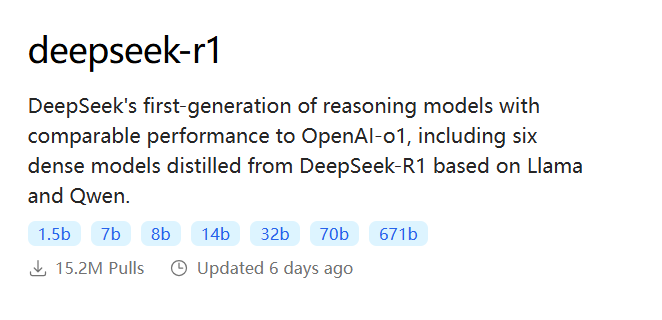
目前DeepSeek-R1可选的模型有满血版671B,和蒸馏版1.5B、7B、8B、14B、32B、70B:
每个版本及对应的电脑硬件要求:
DeepSeek-R1 模型硬件要求
| 模型版本 | CPU 核心数 | 内存 | 存储大小 | 存储类型 | GPU 显存 | GPU 型号 | 应用场景 |
|---|---|---|---|---|---|---|---|
| DeepSeek-R1-671B | 64 核 + | 512 GB | 1 TB + | SSD | 256GB+ | 多节点分布式训练(如 8x A100/H100) | 超大规模 AI 研究、通用人工智能(AGI)探索 |
| DeepSeek-R1-1.5B | 4 核 + | 8GB + | 16GB + | SSD | 4GB + | 非必需(纯 CPU 推理),若 GPU 加速可选 4GB+ 显存 | 低资源设备部署,如树莓派、旧款笔记本、嵌入式系统或物联网设备 |
| DeepSeek-R1-7B | 8 核 + | 16GB + | 32GB + | SSD | 8GB + | 推荐 8GB+ 显存(如 RTX 3070/4060) | 中小型企业本地开发测试、中等复杂度 NLP 任务,例如文本摘要、翻译、轻量级多轮对话系统 |
| DeepSeek-R1-8B | 8 核 + | 16GB + | 32GB + | SSD | 8GB + | 推荐 8GB+ 显存(如 RTX 3070/4060) | 需更高精度的轻量级任务(如代码生成、逻辑推理) |
| DeepSeek-R1-14B | 12 核 + | 32GB + | 32GB + | SSD | 16GB + | 16GB+ 显存(如 RTX 4090 或 A5000) | 企业级复杂任务、长文本理解与生成 |
| DeepSeek-R1-32B | 16 核 + | 64GB + | 64GB + | SSD | 24GB + | 24GB+ 显存(如 A100 40GB 或双卡 RTX 3090) | 高精度专业领域任务、多模态任务预处理 |
| DeepSeek-R1-70B | 32 核 + | 128GB + | 128GB + | SSD | 64GB + | 多卡并行(如 2x A100 80GB 或 4x RTX 4090) | 科研机构/大型企业、高复杂度生成任务 |
硬件要求说明:
- CPU 核心数: 每个版本对 CPU 核心数的要求决定了计算处理的能力,核心数越多,系统可以同时处理更多的任务。
- 推荐 CPU 型号: 根据不同版本的规模和计算需求,推荐的 CPU 型号帮助选择性能合适的处理器。
- 内存: 用于存储模型的中间结果和大规模数据。模型越大,对内存的需求也就越高。
- 存储类型与大小: 推荐使用 SSD,尤其是 NVMe SSD,能够提供更快的数据读取和写入速度。存储大小根据模型和数据量的要求而不同。
- GPU 数量与显卡型号: GPU 用于加速深度学习模型的训练和推理。GPU 数量决定了计算的并行能力,显卡型号影响性能。
- GPU 显存: 显存大小决定了每个 GPU 能处理的模型大小,显存越大,能够处理的模型也就越大。
[!tip] 💡 当使用纯CPU推理时,对CPU和内存的要求更高。
下载模型
运行下面的命令,下载对应的模型
1
ollama run deepseek-r1:7B

安装成功后的界面

可以直接使用了,简单提问试一下:

安装 Page Assist
安装Page Assist
通过 Chrome应用商店安装扩展插件,进入应用市场,搜索Page Assist
点击扩展插件,就可以看到刚刚加载的插件,点击📌将插件固定到浏览器中,方便以后随时打开使用
点击插件图标就可以打开UI界面了,和chatGPT的聊天界面类似,可以选择对应的模型开始提问。
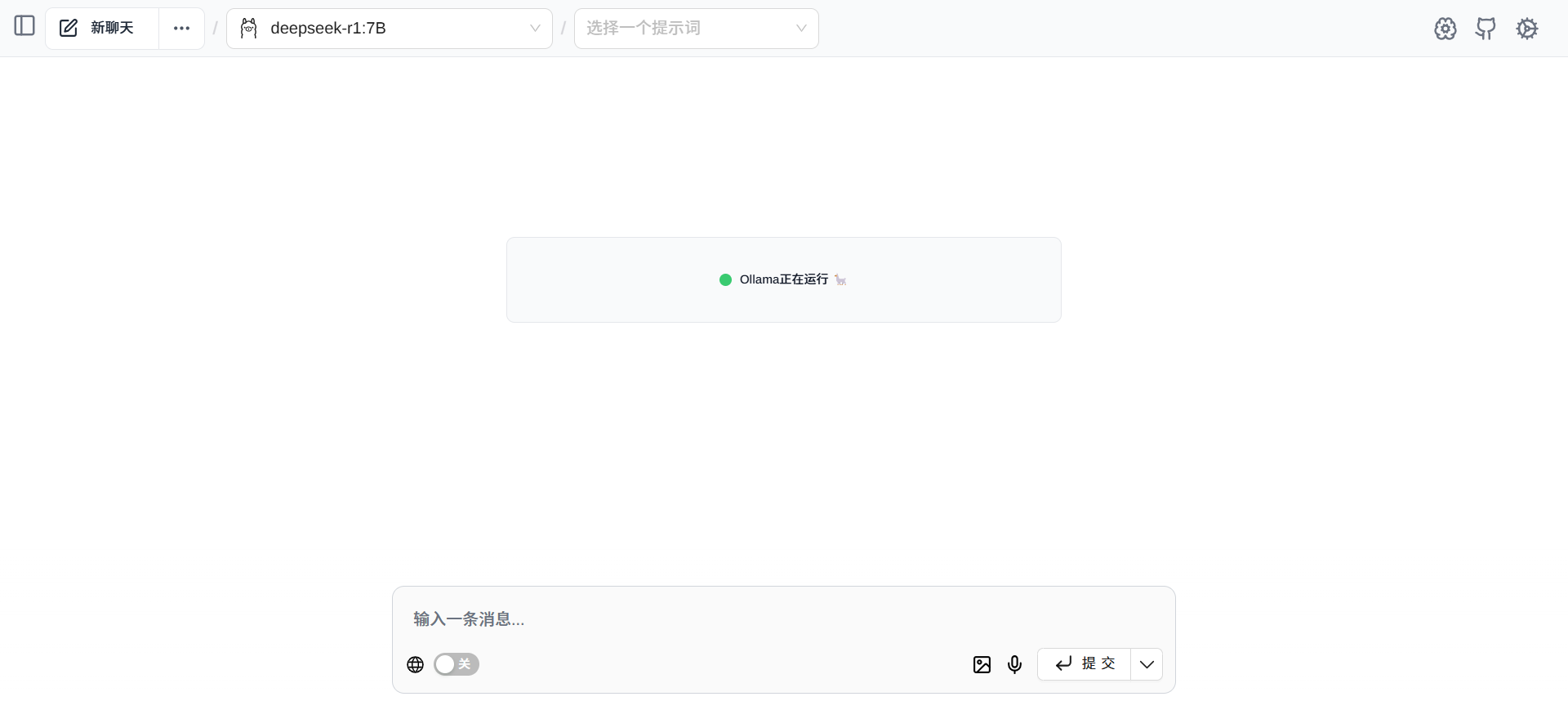
点击模型下拉框,可以查看已经安装的模型,目前已经安装了1.5B和7B的deepseek蒸馏版模型。
接下来,可以选择一个模型提问试试

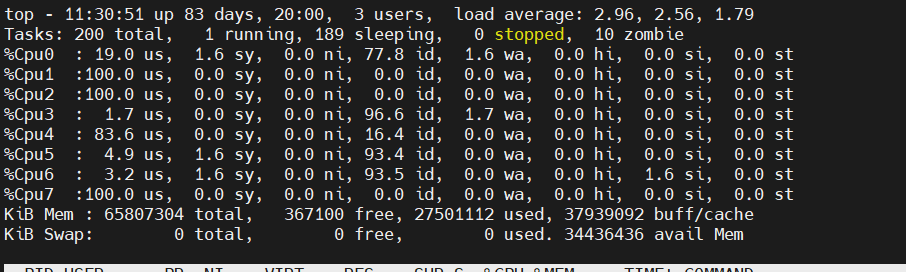
此时服务器CPU情况,推理速度很慢,且服务器资源占用量很大。
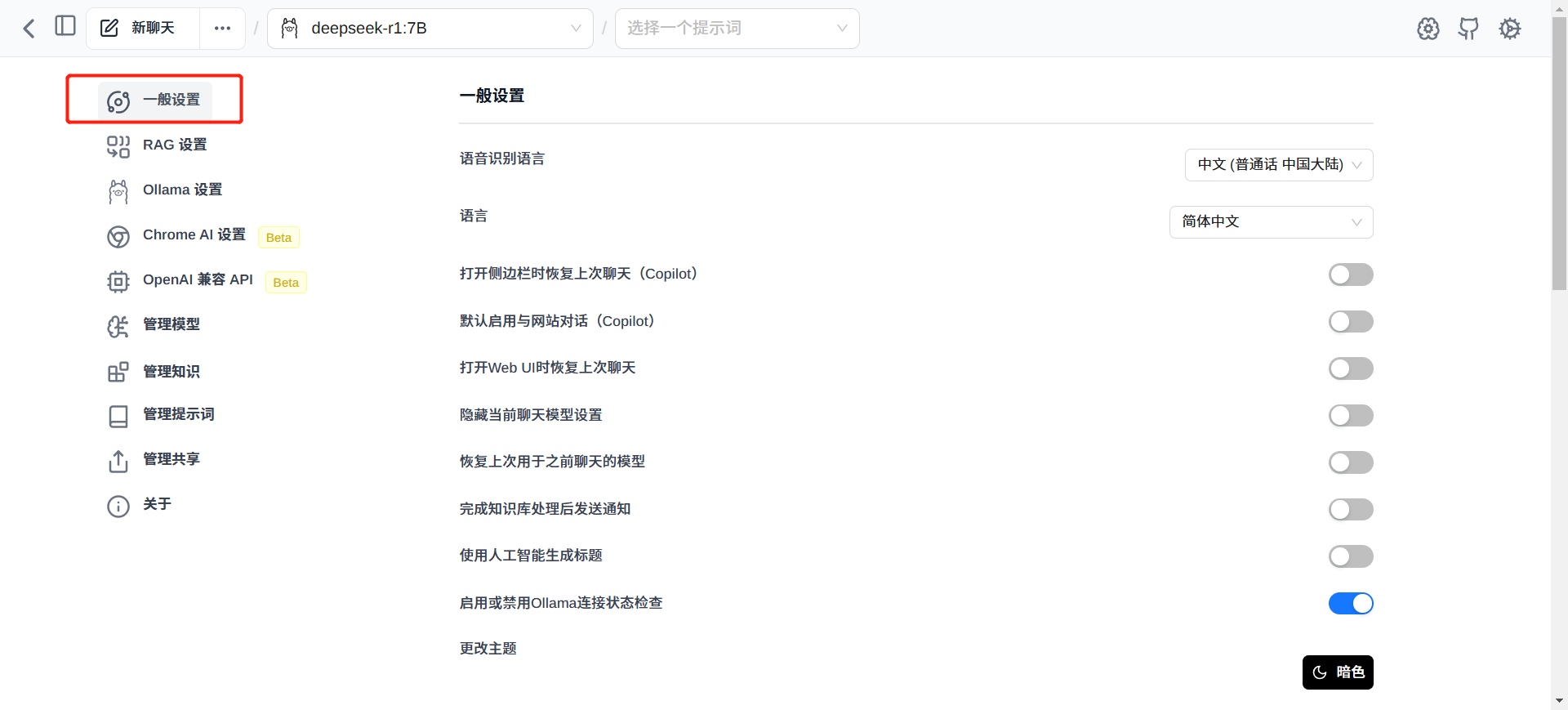
点击右上角的齿轮进入设置页面,可以进行一些基础的设置,如语言,语音识别语言等等。
同时可以管理网络搜索,选择搜索引擎,是否默认联网搜索等。

在“OpenAI 兼容 API”设置项中,会列出所有已添加的服务提供商,
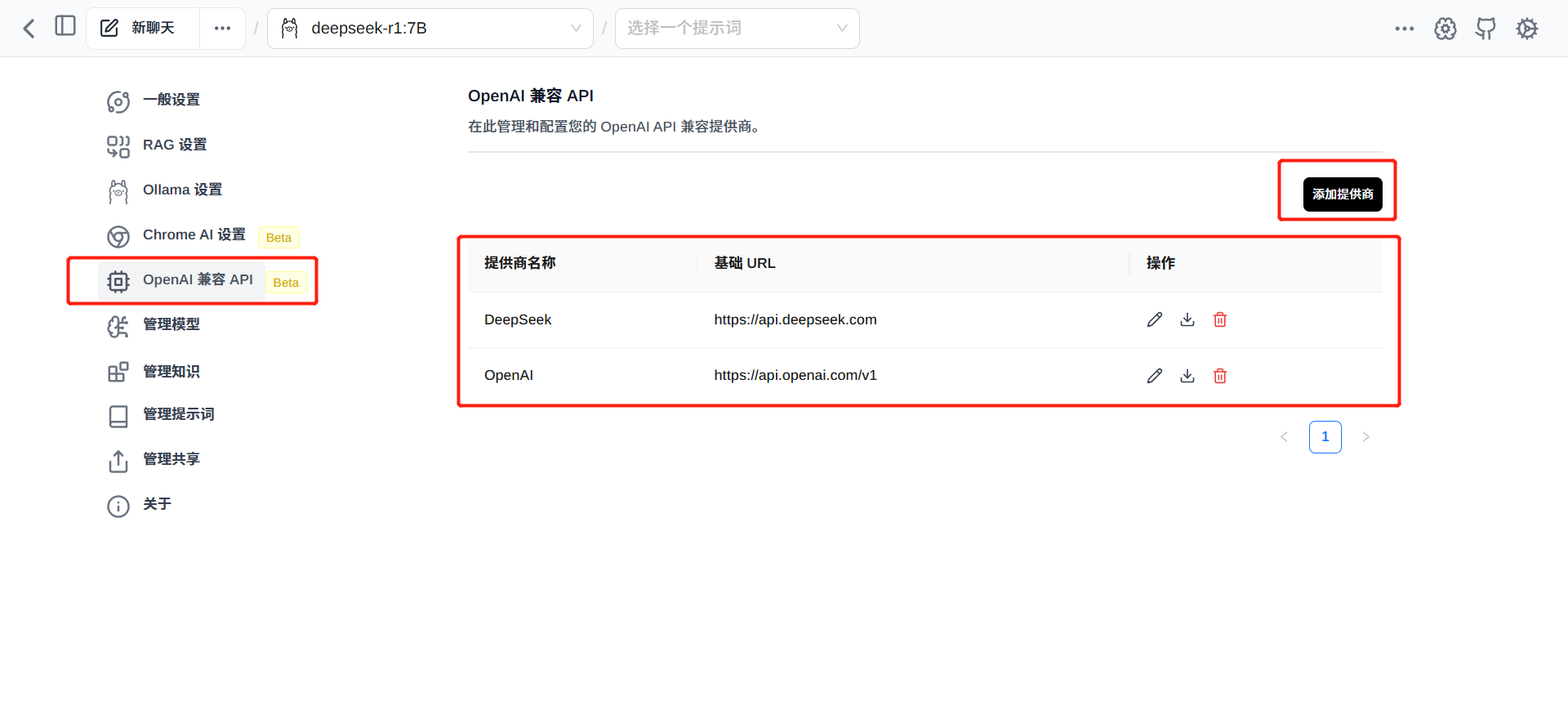
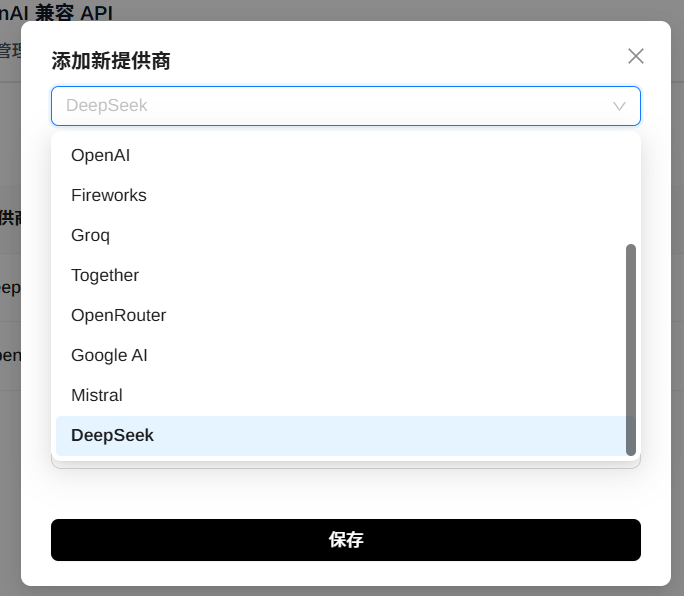
点击“添加提供商”可以添加新的大模型服务提供商
比如,选择“DeepSeek”,会自动带出提供商名称和基础URL,当然也可以修改;填入对应的API key就可以使用了。
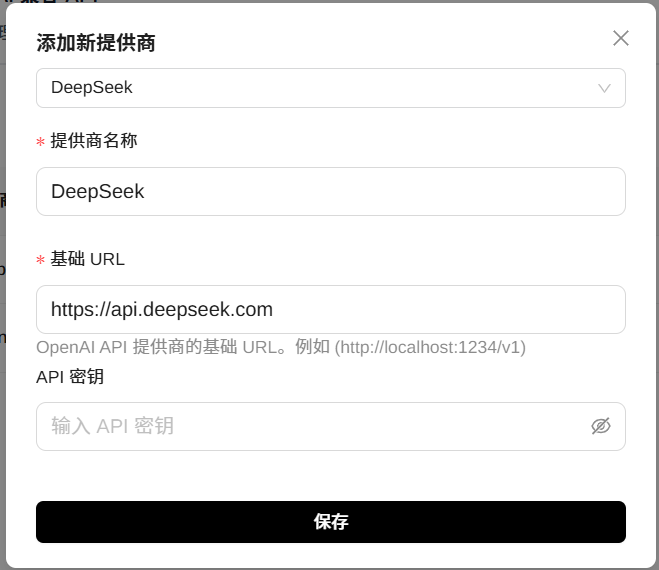
添加完成后,点击下载按钮,可以下载对应的模型
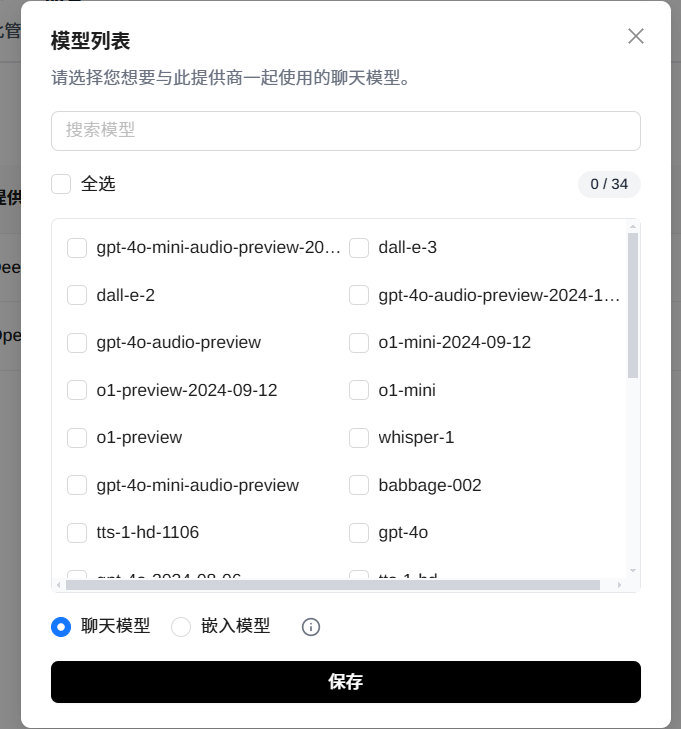
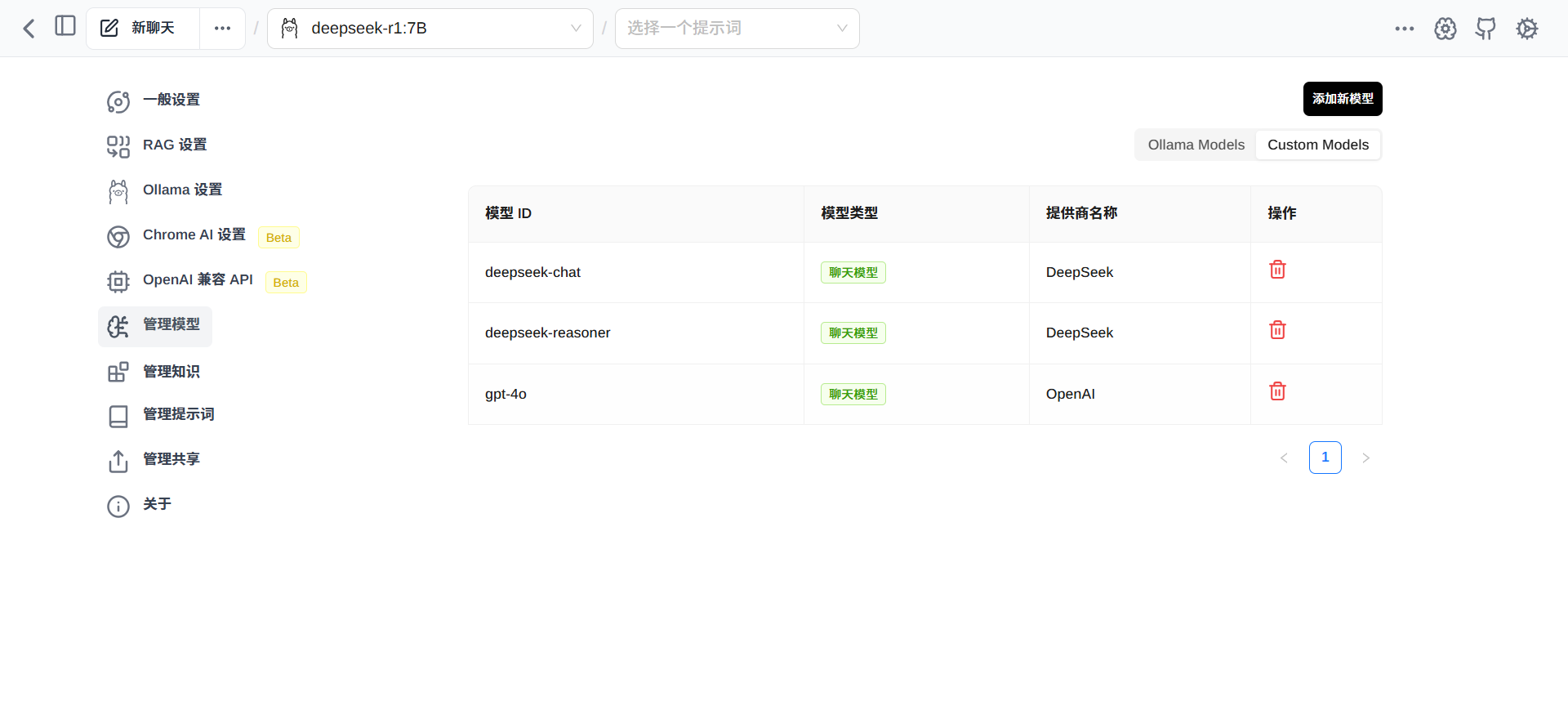
所有已下载的模型,可以在“管理模型”菜单中的 Custom Models 中列出
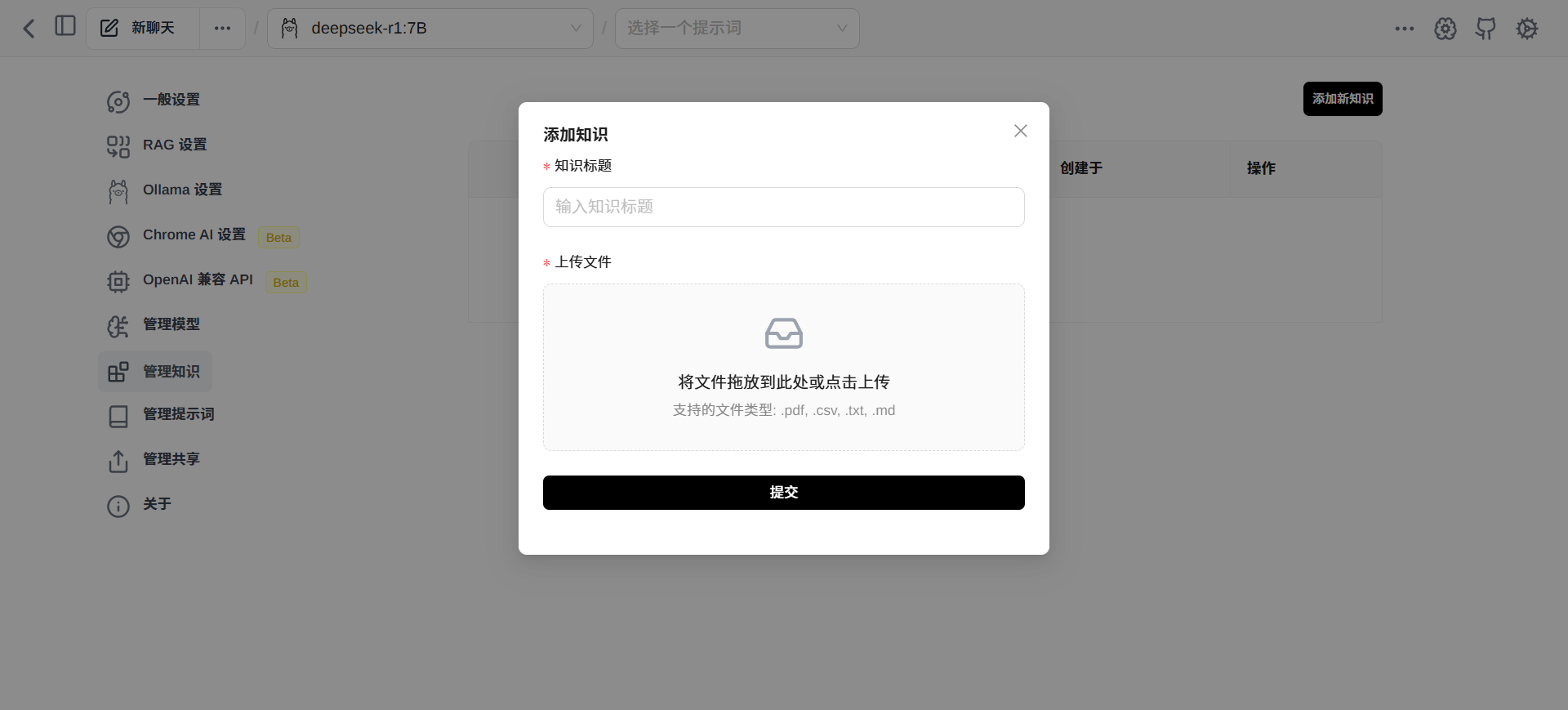
“管理知识”菜单栏,可以添加本地知识库,让DeepSeek更专业。