离线安装 Ollama 并运行 DeepSeek
背景
本次目标是在麒麟银河操作系统上安装DeepSeek,
离线安装 Ollama
略
可参考 DeepSeek私有化部署
离线安装 Open WebUI
离线安装 Python
进入 Python 官网下载符合操作系统版本的安装包
解压安装包: 将 Python 安装包和依赖库安装包传输到离线环境中,并解压 Python 安装包:an装步骤
安装步骤
- 解压安装包: 将 Python 安装包和依赖库安装包传输到离线环境中,并解压 Python 安装包:
1
tar -zxvf Python-x.x.x.tar.gz # 将 x.x.x 替换为实际版本号
- 安装依赖库: 进入依赖库安装包所在的目录,按照依赖关系依次安装依赖库。例如,对于 CentOS/RHEL:
1
rpm -ivh <package_name>.rpm
对于 Debian/Ubuntu:
1
dpkg -i <package_name>.deb
- 配置安装: 进入解压后的 Python 安装包目录,执行以下命令进行配置:Bash
1
./configure --prefix=/opt/python3 --with-openssl=/usr/include/openssl
1
2
- `-prefix` 指定安装目录。
- `-with-openssl` 指定 OpenSSL 库的路径,如果您的 OpenSSL 安装在其他位置,请修改此路径。
- 编译和安装: 执行以下命令进行编译和安装:Bash
1
2
make
sudo make install
- 创建软链接: 为了方便使用,您可以创建软链接:Bash
1
2
sudo ln -s /opt/python3/bin/python3 /usr/bin/python3
sudo ln -s /opt/python3/bin/pip3 /usr/bin/pip3
安装 Openssl
- 下载 OpenSSL 安装包: 访问 OpenSSL 官网(https://www.openssl.org/),下载您需要的 OpenSSL 版本的 tar.gz 压缩包。请确保下载与您的 Linux 系统架构(如 x86_64、arm64 等)匹配的版本。
- 准备安装目录: 在您希望安装 OpenSSL 的位置创建一个目录,例如
/opt/openssl。
安装步骤
- 解压安装包: 将下载的 OpenSSL 安装包传输到您的 Linux 服务器,并解压它:
1
tar -zxvf openssl-x.x.x.tar.gz # 将 x.x.x 替换为实际版本号
- 进入解压后的目录:
1
cd openssl-x.x.x # 将 x.x.x 替换为实际版本号
- 配置安装: 运行配置脚本,指定安装目录和其他选项:
1
./configure --prefix=/opt/openssl shared
1
2
- `-prefix=/opt/openssl` 指定 OpenSSL 的安装目录。
- `shared` 选项表示编译动态链接库。
您还可以根据需要添加其他配置选项,例如:
-with-xxx: 启用对 xxx 功能的支持。-disable-xxx: 禁用 xxx 功能。 您可以通过./configure --help命令查看所有可用的配置选项。
- 编译: 运行
make命令开始编译:
1
make
这个过程可能需要一些时间,取决于您的服务器性能。
- 安装: 运行
make install命令安装 OpenSSL:
1
sudo make install
这将把 OpenSSL 安装到您指定的目录中。
配置环境变量(可选)
为了方便使用 OpenSSL,您可以将其添加到系统的环境变量中。编辑 ~/.bashrc 文件(或 /etc/profile 文件,如果您希望对所有用户生效),添加以下行:
1
2
export PATH=$PATH:/opt/openssl/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/openssl/lib
然后运行以下命令使配置生效:
1
source ~/.bashrc
验证安装
运行以下命令验证 OpenSSL 是否安装成功:
1
openssl version
如果显示 OpenSSL 版本号,则表示安装成功。
注意事项
- 请确保下载的 OpenSSL 版本与您的 Linux 系统兼容。
- 如果在配置或编译过程中遇到错误,请仔细阅读错误信息,并根据提示解决。
- 如果您需要安装其他依赖库,请在安装 OpenSSL 之前安装它们。
希望这些步骤能帮助您在 Linux 环境中成功安装 OpenSSL tar.gz 包。
Ollama 离线导入模型
从 Safetensors 权重导入微调的适配器
首先,创建一个Modelfile替换为FROM命令指向您用于微调的基本模型,并且ADAPTER命令,该命令指向带有 Safetensors 适配器的目录:
1
2
FROM <base model name>
ADAPTER /opt/models/safetensors/adapter/directory
确保在FROM命令,否则将得到不稳定的结果。大多数框架使用不同的量化方法,因此最好使用非量化(即非 QLoRA)适配器。如果您的适配器与您的 Modelfile用ADAPTER .以指定适配器路径。
现在运行ollama create从Modelfile创建时间:
1
ollama create my-model
最后,测试模型:
1
ollama run my-model
Ollama 支持基于多种不同模型架构导入适配器,包括:
- ParLlama(包括ParLlama 2、ParLlama 3、ParLlama 3.1 和ParLlama 3.2);
- Mistral (包括 Mistral 1、Mistral 2 和 Mixtral);和
- Gemma(包括 Gemma 1 和 Gemma 2)
您可以使用微调框架或工具创建适配器,该框架或工具可以以 Safetensors 格式输出适配器,例如:
从 Safetensors 权重导入模型
首先,创建一个Modelfile替换为FROM命令,该命令指向包含 Safetensors 权重的目录:
1
FROM /opt/models/safetensors/directory
如果您在权重所在的目录中创建 Modelfile,则可以使用命令FROM ..
现在运行ollama create命令从您创建Modelfile:
1
ollama create my-model
最后,测试模型:
1
ollama run my-model
Ollama 支持导入多种不同架构的模型,包括:
- ParLlama(包括ParLlama 2、ParLlama 3、ParLlama 3.1 和ParLlama 3.2);
- Mistral (包括 Mistral 1、Mistral 2 和 Mixtral);
- Gemma(包括 Gemma 1 和 Gemma 2);和
- PHI3
这包括导入基础模型以及已与基础模型融合的任何微调模型。
导入基于 GGUF 的模型或适配器
如果您有基于 GGUF 的模型或适配器,则可以将其导入 Ollama。您可以通过以下方式获取 GGUF 型号或适配器:
- 使用
convert_hf_to_gguf.py从 Llama.cpp; - 使用
convert_lora_to_gguf.py从 Llama.cpp;或从 HuggingFace 等位置下载模型或适配器
要导入 GGUF 模型,请创建一个Modelfile含:
1
FROM /opt/models/file.gguf
对于 GGUF 适配器,请创建Modelfile跟:
1
2
FROM <model name>
ADAPTER /opt/models/file.gguf
导入 GGUF 适配器时,请务必使用与创建适配器时使用的基本模型相同的基本模型。您可以使用:
- 来自 Ollama 的模型
- 一个 GGUF 文件
- 基于 Safetensors 的模型
创建Modelfile,请使用ollama create命令构建模型。
1
ollama create <my-model>
量化模型
量化模型可以让您更快地运行模型,并且内存消耗更少,但准确性会降低。这允许您在更适度的硬件上运行模型。
Ollama 可以使用-q/--quantizeflag 替换为ollama create命令。
首先,使用要量化的基于 FP16 或 FP32 的模型创建一个 Modelfile。
1
FROM /path/to/my/gemma/f16/model
用ollama create以创建量化模型。
1
2
3
4
5
6
7
$ ollama create --quantize q4_K_M mymodel
transferring model data
quantizing F16 model to Q4_K_M
creating new layer sha256:735e246cc1abfd06e9cdcf95504d6789a6cd1ad7577108a70d9902fef503c1bd
creating new layer sha256:0853f0ad24e5865173bbf9ffcc7b0f5d56b66fd690ab1009867e45e7d2c4db0f
writing manifest
success
支持的量化
- q4_0
- q4_1
- q5_0
- q5_1
- q8_0
K-means 量化
- q3_K_S
- q3_K_M
- q3_K_L
- q4_K_S
- q4_K_M
- q5_K_S
- q5_K_M
- q6_K
在 ollama.com 上共享模型
您可以通过将您创建的任何模型推送到 ollama.com 来共享该模型,以便其他用户可以试用。
首先,使用浏览器转到 Ollama 注册页面。如果您已经有账户,则可以跳过此步骤。
这Username字段将用作模型名称的一部分(例如jmorganca/mymodel),因此请确保您对所选的用户名感到满意。
现在,您已经创建了一个帐户并已登录,请转到 Ollama Keys Settings 页面。
按照页面上的说明确定您的 Ollama 公钥所在的位置。
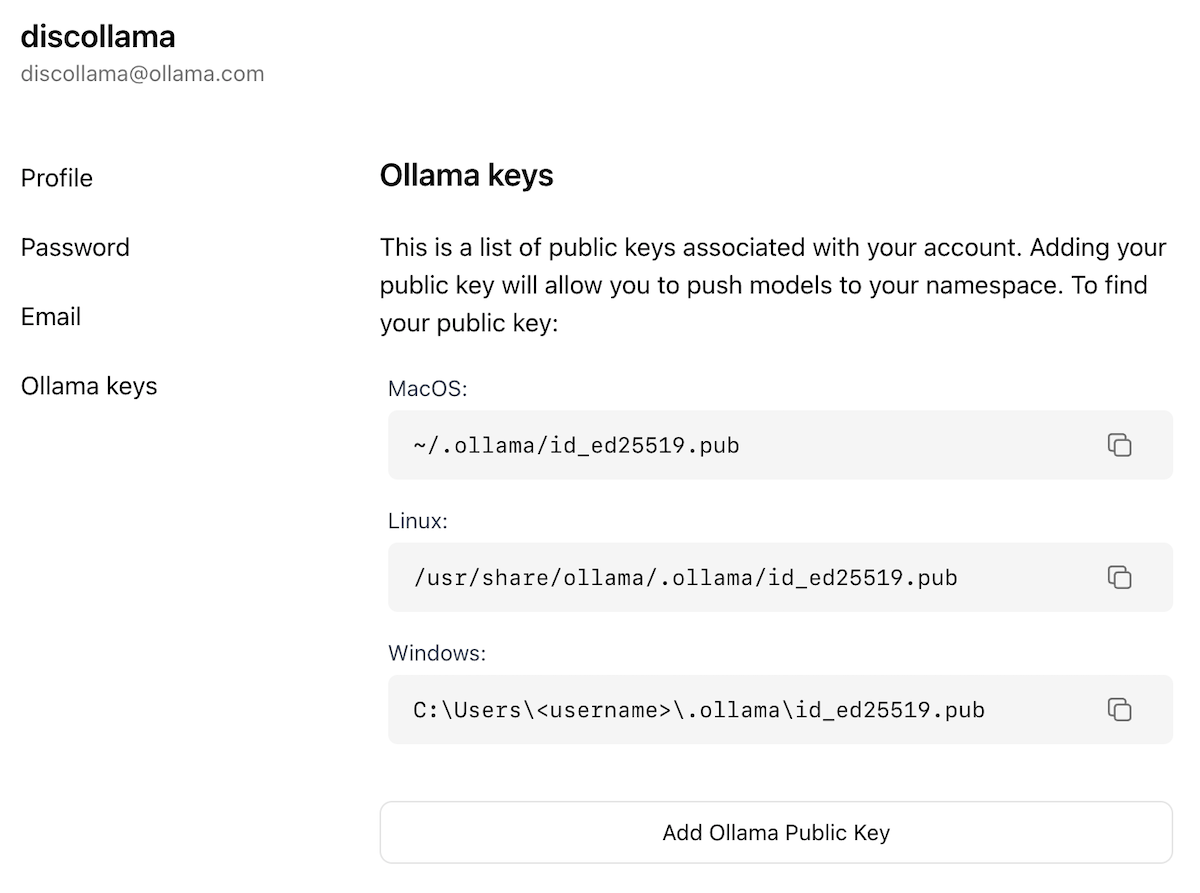
单击Add Ollama Public Key按钮,然后将 Ollama 公钥的内容复制并粘贴到文本字段中。
要将模型推送到 ollama.com,请首先确保使用你的用户名正确命名它。您可能需要使用ollama cp要复制的命令 您的 model 为其指定正确的名称。对模型的名称感到满意后,请使用ollama push 命令将其推送到 ollama.com。
1
2
ollama cp mymodel myuser/mymodel
ollama push myuser/mymodel
推送模型后,其他用户可以使用以下命令拉取并运行它:
1
ollama run myuser/mymodel
参考文献
- Ollama内网离线部署大模型
- **最全 Ollama 大模型部署指南,非常详细收藏我这一篇就够了! **
[**Ollama 中文文档 Ollama 官方文档**](https://ollama.cadn.net.cn/#quickstart) - Ollama自定义导入DeepSeek-R1-Distill-Qwen-1.5B模型