Pytorch网络搭建与训练
0. Pytorch安装

Pytorch安装较为简单,本书不做过多介绍,进入Pytorch官网,选择对应的版本环境,利用下方生成的命令行安装即可。
1. MINST识别简单案例
我们先通过一个简单的例子来了解一下使用Pytorch搭建一个模型的完整流程,参考下面这张图,我们先通过文字来解释一下神经网络的工作原理。
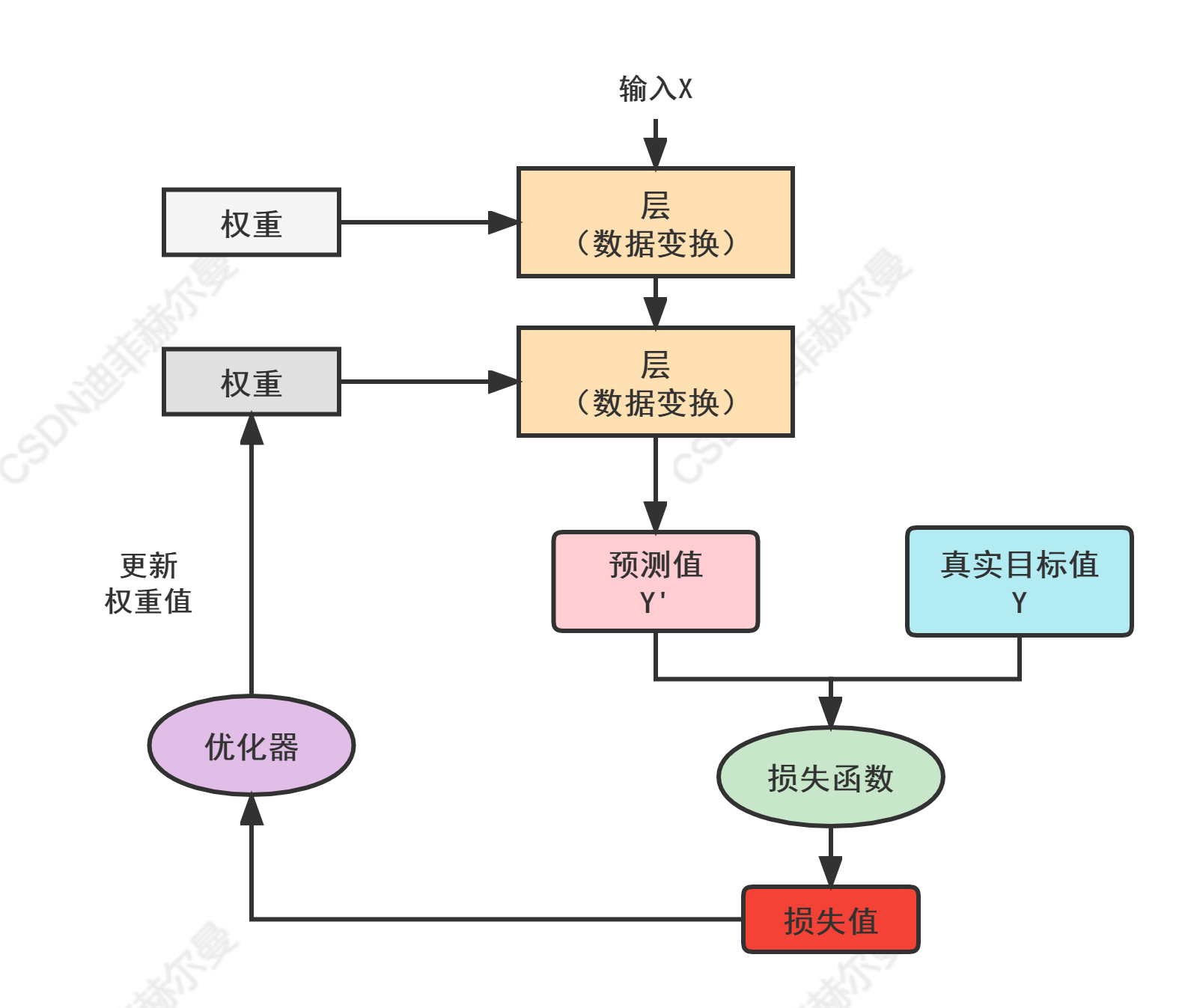
神经网络中每层对输入数据所做的具体操作保存在该层的权重(weight)中,其本质是一串数字。权重也被称之为该层的参数(parameter)。学习的意思就是为神经网络的所有层找到一组权重值,使得该网络能够将每个输入与目标正确的一一对应。但通常神经网络中包含上千万个参数,这时候我们就要通过损失函数来衡量输入值与期望值之间的距离,紧接着,我们使用这个距离值作为反馈信号来对权重进行微调,这种微调操作我们就通过优化器来完成,优化器就实现了我们所谓的反向传播算法。
但是在一开始,我们对神经网络的权重是随机赋值的,经过一次这样的变换输入结果和理想值还是差距很大,这也代表着损失值依然很高。但是当我们加大训练次数,权重值也会一点一点的向正确的方向靠近,损失值也会逐渐下降,这就是我们说的训练循环,将这种训练重复足够多的次数得到的权重值可以使损失函数最小,具有最小损失的网络,其输出值与目标值就非常的接近,这样的话,我们就达到了最终的目的。
下面就通过一个具体的神经网络实例,来让大家了解神经网络的工作原理。
1.1 准备数据集
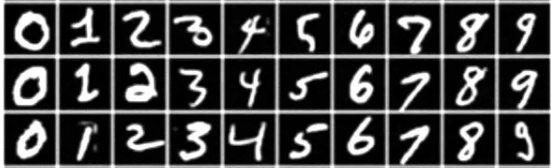
我这里选择的实例是非常经典的手写字体识别,我们要将手写数字的灰度图像划分到10个类别中。MNIST数据集包含60000张训练图像和10000张测试图像,MNIST问题经常被当做深度学习领域中的“hello world”,下面是该数据集中一些图像样本。
1
2
3
4
5
6
7
8
train_dataset = datasets.MNIST(root='./',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='./',
train=False,
transform=transforms.ToTensor(),
download=True)
root代表数据存放的路径,“./”就代表与我目前这个文件同级别的位置
将train设置为True,表示使用MNIST数据集中的训练集
ToTensor()函数就是将我们加载的图片转换为Tensor的形式
download=True 这个代表是否要下载数据集。如果设置为True,当在root中检测不到数据集,系统会自动下载,当下载一次后,我们后续可以将参数设置为False
当训练集准备完毕时,我们以同样的方式准备测试集(测试集 train=False)
1.2 加载数据集
当数据集准备完成后我们通过DataLoader加载数据集,这里我们设置批次大小为64
1
2
3
4
5
6
train_loader = DataLoader(dataset=train_dataset,
batch_size=64,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=64,
shuffle=True)
加载后我们可以在控制台打印一下train_loader和test_loader的长度
1
2
3
len(train_loader)
Out[1]: 938len(test_loader)
Out[2]: 157
我们设置的batch_sizes为64,MINST训练集一共60000张图片,每次拿64张图,一共需要拿938次
测试集一共10000张图片,每次拿64张图,一共需要拿157次
1
2
3
len(train_loader)
Out[3]: 1875len(test_loader)
Out[4]: 313
如果我们batch_size设置为32,每次拿32张图,训练集一共需要拿1875次,测试集一共需要拿313次
这里所说的“拿的次数”,就是Iteration,1个Iteration就是使用batch_size个样本训练一次;
1.3 构建网络
1
2
3
4
5
6
7
8
9
10
11
12
13
# 定义网络结构class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(784,10)
self.softmax = nn.Softmax(dim=1)
def forward(self,x):
# ([64, 1, 28, 28])->(64,784)
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.softmax(x)
return x
# 定义模型
my_model = Net()
在这部分我们就可以构建网络结构了,这里我们采用一个非常简单的网络结构,即一个线性层加上一个激活函数(中间涉及到的维度转换大家可以先不用看)。
1.4 配置损失函数和优化器
1
2
3
4
# 定义损失函数
mse_loss = nn.MSELoss()
# 定义优化器
optimizer = optim.SGD(my_model.parameters(), lr=0.1) #lr代表学习率
损失函数我们采用MCELoss,即均方损失函数:
\[loss (xi, yi) = (xi − yi)2\]优化器选择SGD,学习率设置为0.1
1.5 模型训练与测试
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 模型训练
def train():
for i,data in enumerate(train_loader):
# 获得一个批次的数据和标签
inputs, labels = data
# 获得模型预测结果(64,10)
out = my_model(inputs)
#----------现阶段One-hot这部分代码大家可以忽略-----------------------
# to onehot,把数据标签变成独热编码
# (64)-(64,1)
labels = labels.reshape(-1,1)
# tensor.scatter(dim, index, src)
# dim:对哪个维度进行独热编码
# index:要将src中对应的值放到tensor的哪个位置
# src:插入index的数值
one_hot = torch.zeros(inputs.shape[0],10).scatter(1, labels, 1)
# 计算loss,mes_loss的两个数据的shape要一致
loss = mse_loss(out, one_hot)
# 梯度清零
optimizer.zero_grad()
# 计算梯度
loss.backward()
# 更新权值
optimizer.step()
1
2
3
4
5
6
7
8
9
10
11
def test():
correct = 0
for i,data in enumerate(test_loader):
# 获得一个批次的数据和标签
inputs, labels = data
# 获得模型预测结果(64,10)
out = my_model(inputs)
# 获得最大值,以及最大值所在的位置
_, predicted = torch.max(out, 1)
correct += (predicted == labels).sum()
print("Test acc:{0}".format(correct.item()/len(test_dataset)))
当训练和测试函数写好后,我们就可以开始训练了,我这里设置epoch为30,训练结果如下:
1
2
3
4
5
if __name__ == '__main__':
for epoch in range(30):
print('epoch:', epoch)
train()
test()
1
2
3
4
5
6
7
8
9
epoch: 0
Test acc:0.8191
epoch: 1
Test acc:0.865
。
。
。
epoch: 29
Test acc:0.9167
到这里一个完整的模型训练过程就结束了,大家可以把这段代码当作搭建一个模型最基本的骨架,我们只要了解搭建一个模型的步骤即可,后面我会详细解释每个模块的使用方式,不断地丰满我们这个模型。
1.6 完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
import numpy as np
from torch import nn, optim
from torch.autograd import Variable
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch
# 准备MNIST训练集
train_dataset = datasets.MNIST(root='./', # root代表数据存放的路径,“./”就代表与我目前这个文件同级别的位置
train=True, # 将train设置为True就代表我们载入的是训练集的数据
transform=transforms.ToTensor(), # .ToTensor()函数就是将我们加载的图片转换为Tensor的形式
download=True) # 这个代表是否要下载数据集,如果设置为True,当在root中检测不到数据集,系统会自动下载
# 准备MNIST测试集
# 和训练集格式基本相同,差别在于train的参数设置为了False
test_dataset = datasets.MNIST(root='./',
train=False,
transform=transforms.ToTensor(),
download=True)
# 装载训练集数据
train_loader = DataLoader(dataset=train_dataset, # dataset的名字就是我们刚才准备的的train_dataset
batch_size=64, # 模型批次大小
shuffle=True) # 是否打乱
# 装载训测试集数据
test_loader = DataLoader(dataset=test_dataset,
batch_size=64,
shuffle=True)
# for i, data in enumerate(train_loader):
# inputs, labels = data # data里面有两个值,数据和标签
# print(inputs.shape)
# print(labels.shape)
# break # 每个批次数据格式都是相同的,所以用break控制只打印一次
#>>> torch.Size([64, 1, 28, 28])
#>>> torch.Size([64])
# 64 代表批次大小。我们上一步设置的是64
# 1 代表通道数 。MNIST数据集是灰度图,所以只有一个通道
# 28 代表图像尺寸。28像素×28像素
# 64 代表64个标签数值,数值范围就是0-9之间,表示我们该批次64张图的标签
# len(train_loader)
# >>>938
# 我们设置的批次大小为64,MINST一共60032张图片,每次拿64张图,一共需要拿938次
# 定义网络结构
class Net(nn.Module):
def __init__(self): # 固定格式
super(Net, self).__init__() # 固定格式
self.fc1 = nn.Linear(784, 10) # 我们简单定义一个784个输入,10个输出的层
self.softmax = nn.Softmax(dim=1) # 加一个激活函数,增加模型的非线性能力。这里为什么要限定第1维度呢?
# 因为我们上层的输出值是(64,10),所以我们要把第1个维度(维度从0开始算)的值做一个概率的转换,
# 将网络的输出值转化为概率值
def forward(self, x): # 固定格式
# ([64, 1, 28, 28])->(64,784)
x = x.view(x.size()[0], -1) # 这部分比较特殊,由于我们设置的Linear的输入是784,但是我们图像的格式是[64, 1, 28, 28],所以这里我们要做一个转换
x = self.fc1(x) # 这里加上我们上面定义的网络
x = self.softmax(x)
return x
# 定义模型
my_model = Net()
# 定义损失函数
mse_loss = nn.MSELoss()
# 定义优化器
optimizer = optim.SGD(my_model.parameters(), lr=0.1) # lr代表学习率
# 模型训练
def train():
for i, data in enumerate(train_loader):
# 获得一个批次的数据和标签
inputs, labels = data
# 获得模型预测结果(64,10)
out = my_model(inputs)
# to onehot,把数据标签变成独热编码
# (64)-(64,1)
labels = labels.reshape(-1, 1)
# tensor.scatter(dim, index, src)
# dim:对哪个维度进行独热编码
# index:要将src中对应的值放到tensor的哪个位置。
# src:插入index的数值
one_hot = torch.zeros(inputs.shape[0], 10).scatter(1, labels, 1)
# 计算loss,mes_loss的两个数据的shape要一致
loss = mse_loss(out, one_hot)
# 梯度清零
optimizer.zero_grad()
# 计算梯度
loss.backward()
# 修改权值
optimizer.step()
# 模型测试
def test():
correct = 0
for i, data in enumerate(test_loader):
# 获得一个批次的数据和标签
inputs, labels = data
# 获得模型预测结果(64,10)
out = my_model(inputs)
# 获得最大值,以及最大值所在的位置
_, predicted = torch.max(out, 1) # 1代表维度。 我们要拿到10个值里面概率最大的值
# 预测正确的数量
correct += (predicted == labels).sum() # 使用64个预测值和64个标签做对比,判断他们是否相等;
# 也就是判断这64个值里面有多少个预测值和真实标签是相同的
print("Test acc:{0}".format(correct.item() / len(test_dataset)))
if __name__ == '__main__':
for epoch in range(30):
print('epoch:', epoch)
train()
test()
2. Pytorch数据读取机制
在数据读取部分我们主要解决三个问题:
- 读取哪些数据?
- 从哪里读取数据?
- 怎么读取数据?
2.1 Dataloader
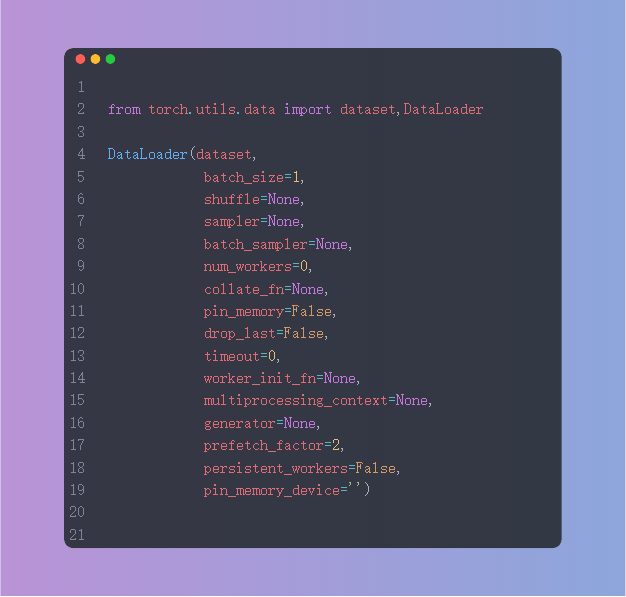
这里我们主要介绍几个常用的参数:
- dataset:Dataset类,决定数据从哪读取及如何读取
- batch_size:每个批次要加载多少个样本,默认为1
- shuffle:在每个周期是否重新打乱数据
- num_workers:是否已多进程的形式读取数据
- drop_last:当样本不能被batch_size整除时,是否舍弃最后一批数据
2.2 Dataset

Dataset类是用来定义数据从哪读取及如何读取的为问题,Pytorch中给的Dataset是一个抽象类,我们所有定义的Dataset都要继承它,并且要重写__getitem__(self, item),getitem的作用就是接收一个索引,返回一个样本。
2.2 读取Pytorch内置数据集
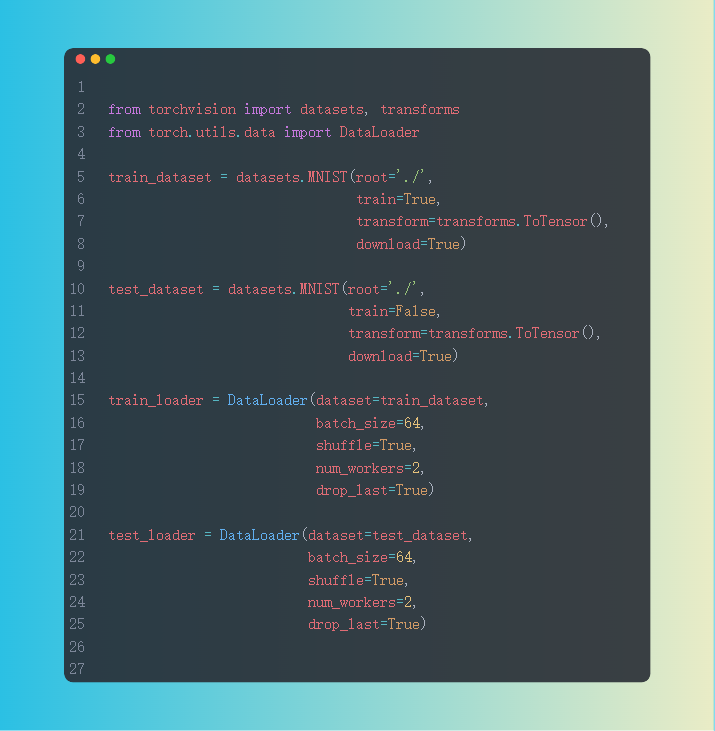
读取内置数据集的操作较为简单,不需要我们自己定义Datasets类,我们只需要指定想使用的数据集与参数即可。
这里我依然使用MNIST数据集,通过datasets准备数据集,通过DataLoader加载数据集。
2.3 读取自定义数据集
在实际的应用过程中数据集的格式各种各样,那么用torchvision自带的库就不能用了,需要自定义数据读取方式,我这里给出一个比较通用的模板,具体任务中,大家还需要一些小小的改动。这段代码要求我们在数据处理时先用os库遍历数据集文件,提取图片的名字和对应的label,生成CSV文件。
在写自定义类时起手直接写上这个固定格式,然后再向里面填东西。

定义好MYData类后实例化,然后使用DataLoader加载就可以了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
class MYData(Dataset):
def __init__(self, image_path, transform=None):
self.imgs_info = pd.read_csv(image_path)
def __getitem__(self, index):
img_path, label = self.imgs_info['img_path'], self.imgs_info['weather']
img = Image.open(img_path)
img = img.convert('RGB')
if transform is not None:
img = transform(img)
returnimg, label
def __len__(self):
return len(self.imgs_info)
train_csv_path = r'./dataset/train.csv'
train_transforms = transforms.Compose(transforms.ToTensor())
train_dataset = MYData(train_csv_path, transform=train_transforms)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
3. 数据预处理transforms模块
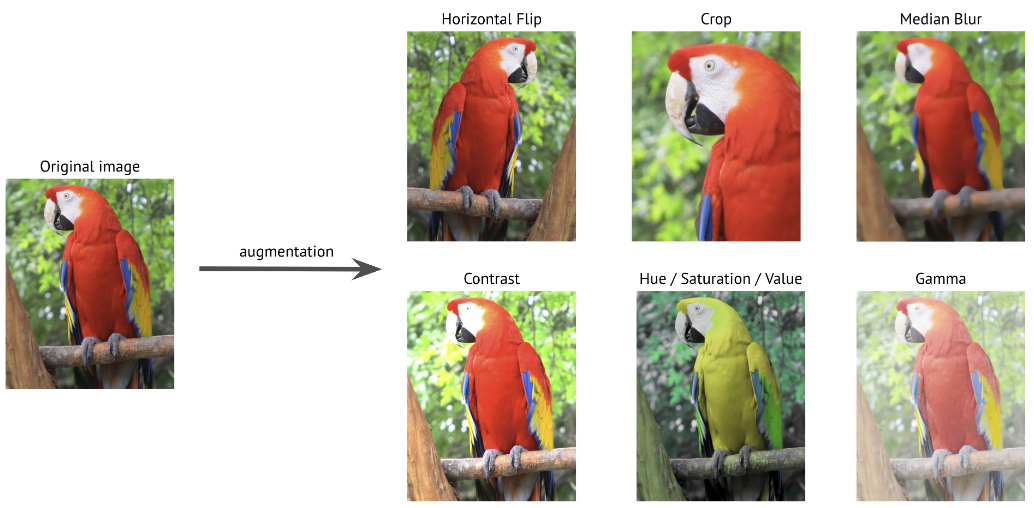
Pytorch的torchvision.transforms模块中提供了大量的数据增强方法,我们可以选择将transforms部分写在Dataset的__getitem__(self, item)里面或者Dataset外面,以2.3中的transforms.Compose(transforms.ToTensor())为例子,我们只需要将数据增强方法写入该模块内。

即:
1
2
3
4
5
6
7
8
train_transforms=transforms.Compose(
[transforms.RandomResizedCrop(size=640, scale=(0.5, 1.0)),
transforms.RandomRotation(degrees=15),
transforms.RandomHorizontalFlip(),
transforms.CenterCrop(size=224),
transforms.ToTensor(),
transforms.Normalize([0.888, 0.555, 0.777],
[0.121, 0.221, 0.321])
这样网络在加载数据集时就会自动增强数据集,增强模型的鲁棒性。
4. Pytorch容器机制
我们主要介绍以下四种容器,在实际代码中前两种见的比较多:
- nn.Module
- nn.Sequetial
- nn.ModuleList
- nn.ModuleDict
4.1 nn.Module
这个是所有神经网络模块的基类,也是平时使用最多的类,模型可以子类化这个类。也可以把子模块作为常规属性来分配。

4.2 nn.Sequential
Sequential是一个顺序的容器。模块将按照它们在构造函数中传递的顺序被添加到其中。或者也可以传入一个模块的OrderedDict。Sequential的forward()方法接受任何输入并将其转发给它所包含的第一个模块。然后,它将每个后续模块的输出与输入依次 “串联”,最后返回最后一个模块的输出。与手动调用模块序列相比,序列提供的价值在于它允许将整个容器视为一个单一的模块,这样在序列上执行的转换适用于它所存储的每个模块。

4.3 nn.ModuleList
nn.ModuleList将子模块保存在一个列表中。使得模块可以像普通的Python列表一样被索引。

4.4 nn.ModuleDict
nn.ModuleDict用于包装一组网络层,以索引方式调用网络层主要方法。

小结:
- nn.Sequential:顺序性,各网络层之间严格按顺序执行,常用于block构建。
- nn.ModuleList:迭代性,常用于大量重复网络构建,通过for循环实现重复构建。
- nn.ModuleDict:索引性,常用于可选择的网络层。
5. 网络搭建模块torch.nn
终于来到了这里,torch.nn可能是我们在整个框架中使用最多的部分,这里掌握的程度直接决定了我们复现模型的能力,下面我们就讲解如何通过堆叠卷积池化等模块去生成一个网络。
5.1 nn.Conv2d

功能:对多个二维信号进行二维卷积
主要参数:
- in_channels:输入通道数
- out_channels:输出通道数,等价于卷积核个数
- kernel_size:卷积核尺寸
- stride:步长
- padding :填充个数
- dilation:空洞卷积大小
- groups:分组卷积设置
- bias:偏置
5.2 nn.ConvTranspose2d

功能:转置卷积实现上采样
主要参数:
- in_channels:输入通道数
- out_channels:输出通道数
- kernel_size:卷积核尺寸
- stride:步长
- padding :填充个数
- dilation:空洞卷积大小
- groups:分组卷积设置
- bias:偏置
5.3 nn.MaxPool2d

功能:对二维图像进行最大值池化
主要参数:
- kernel_size:池化核尺寸
- stride:步长
- padding :填充个数
- dilation:池化核间隔大小
- ceil_mode:尺寸向上取整
- return_indices:记录池化像素索引
5.4 nn.AvgPool2d

功能:对二维图像进行平均值池化
主要参数:
- kernel_size:池化核尺寸
- stride:步长
- padding :填充个数
- ceil_mode:尺寸向上取整
- count_include_pad:填充值用于计算
- divisor_override :除法因子
5.5 nn.Linear

功能:对一维信号进行线性组合
主要参数:
- in_features:输入结点数
- out_features:输出结点数
- bias :是否需要偏置
6.权重初始化方式
这里不多说,就是简单的函数调用

7.损失函数
同样是简单的函数调用。

| 损失函数 | 别名 | 功能 |
|---|---|---|
| L1Loss | L1 范数损失/最小绝对值偏差/最小绝对值误差 | 计算output和target之差的绝对值,可选返回同维度的tensor或者是一个标量。 |
| MSELoss | L2 范数损失/最小均方值偏差/最小均方值误差 | 计算output和target之差的平方,可选返回同维度的tensor或者是一个标量。 |
| CrossEntropyLoss | 交叉熵损失 | 将输入经过softmax激活函数之后,再计算其与target的交叉熵损失。即该方法将nn.LogSoftmax()和 nn.NLLLoss()进行了结合。严格意义上的交叉熵损失函数应该是nn.NLLLoss()。 |
| PoissonNLLLoss | 目标泊松分布的负对数似然损失 | 用于target服从泊松分布的分类任务。 |
| KLDivLoss | KL散度/相对熵 | 计算input和target之间的KL散度( Kullback–Leibler divergence) 。 |
| BCELoss | 二分类交叉熵损失 | 二分类任务时的交叉熵计算函数。此函数可以认为是nn.CrossEntropyLoss函数的特例。 |
| SmoothL1Loss | 平滑版的L1 Loss | 计算平滑L1损失,属于 Huber Loss中的一种(因为参数δ固定为1了)。 |
8.优化器
随着版本的不断升级,优化器也越来越多,但SGD永远是最经典的。

9.学率调整策略
这里的部分和第二章介绍过的学习率调整策略正好对应上了。
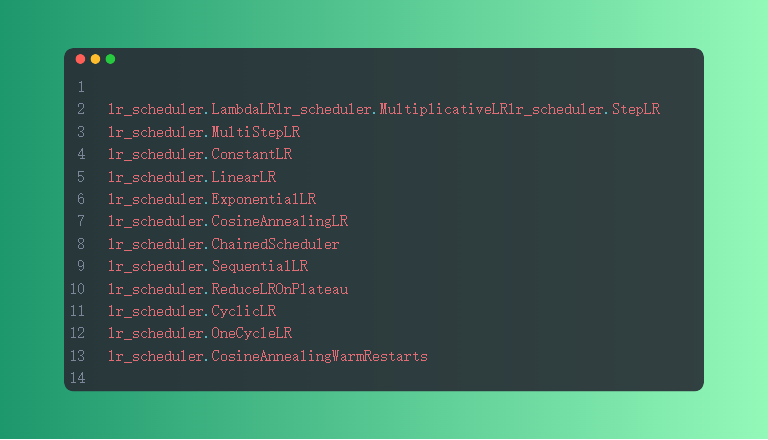
10.代码实战
10.1 复现VGG16网络结构
前面的代码部分我只能介绍这么多,更多的东西还得是通过动手来学习的,下面我们从复现一个网络结构开始,逐步地去掌握框架的使用方式。
VGG有6种子模型,分别是A、A-LRN、B、C、D、E,我们常看到的基本是D、E这两种模型,即VGG16,VGG19,我们这里来复现VGG16。(为了和图片保持一直,并没有加上激活函数层)
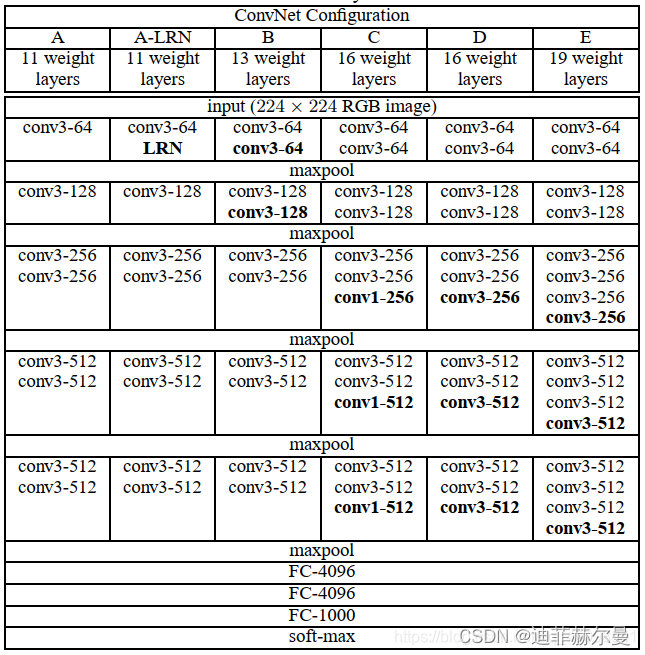
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
from torch import nn
import torch
from torchsummary import summary
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.sum_Module = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.MaxPool2d(2, 2),
nn.Flatten(),
nn.Linear(7 * 7*512, 4096),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.Dropout(0.5),
nn.Linear(4096, 1000)
)
def forward(self, x):
x = self.sum_Module(x),
return x
if __name__ == '__main__':
YOLO = VGG16()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
inputs = YOLO.to(device)
summary(inputs, (3, 224, 224),batch_size=1, device="cuda") # 分别是输入数据的三个维度
在搭建好结构后我们通过torchsummary就可以打印出来我们模型的结构和参数量
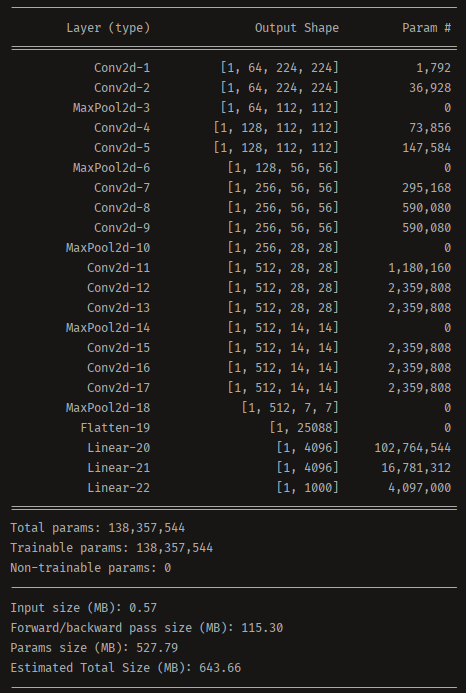
10.2 SPP结构
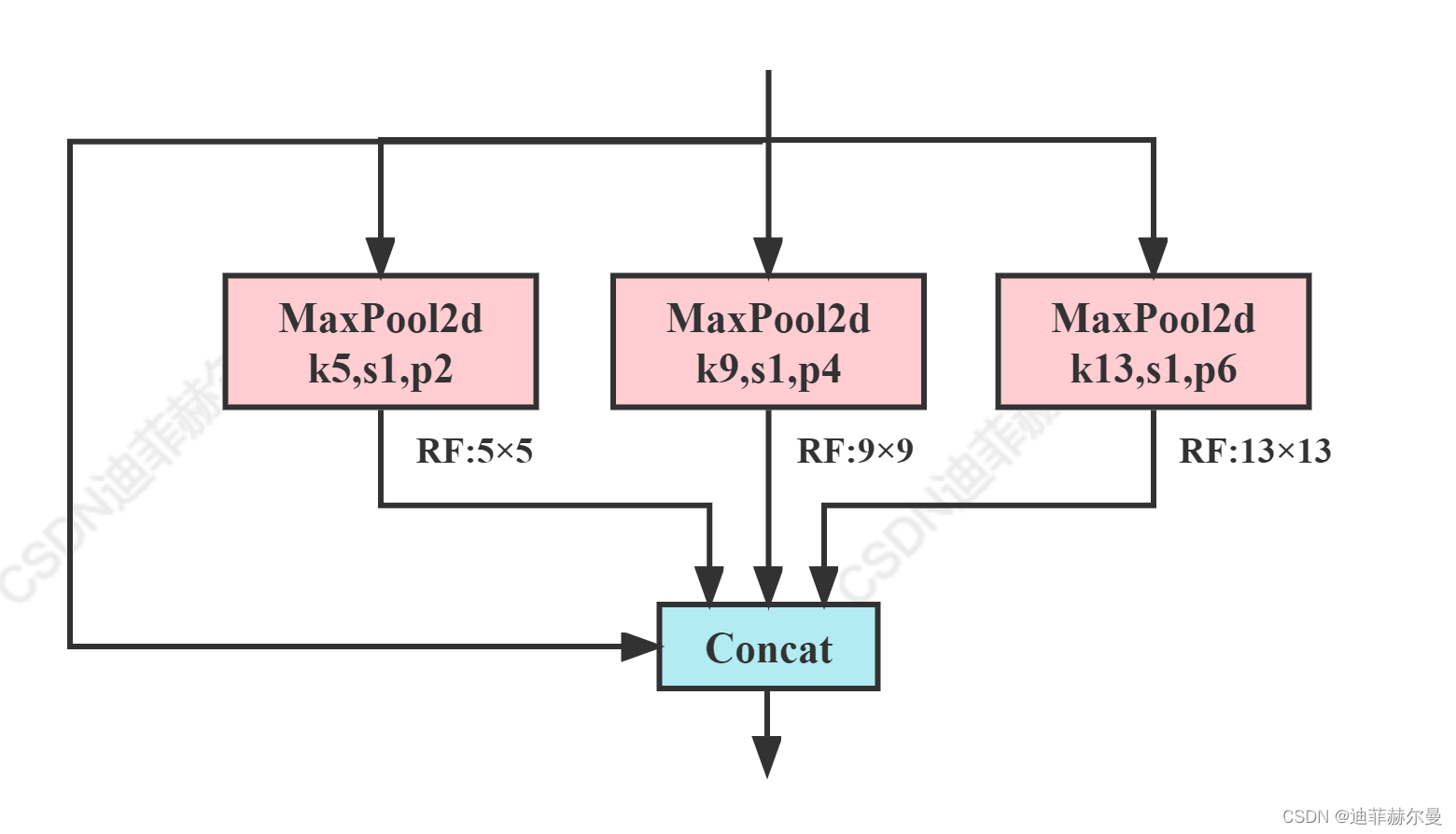
上图的SPP结构我提供了两种编写方式,上面一种是比较常规的编写方式,下面的一种就是在高Star项目里经常见到的写法,使用了nn.ModuleList容器。
1
2
3
4
5
6
7
8
9
10
11
12
13
class SPP(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(5, 1, padding=2)
self.maxpool2 = nn.MaxPool2d(9, 1, padding=4)
self.maxpool3 = nn.MaxPool2d(13, 1, padding=6)
def forward(self, x):
o1 = self.maxpool1(x)
o2 = self.maxpool2(x)
o3 = self.maxpool3(x)
return torch.cat([x, o1, o2, o3], dim=1)
1
2
3
4
5
6
7
class SPP(nn.Module):
def __init__(self, k=(5, 9, 13)):
super().__init__()
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
return torch.cat([x] + [m(x) for m in self.m], 1)
10.3 Bottleneck结构
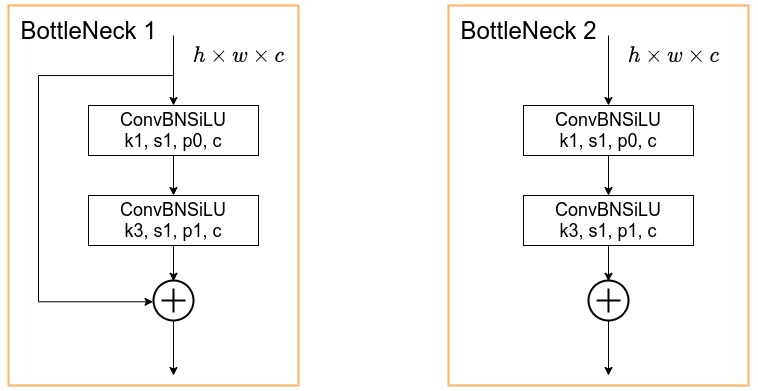
这是YOLOv5作者写的代码,里面有一个非常巧妙的设计,当shortcut设置为True或False时模型会使用不同的结构,这样大大提高了代码的复用性。并且这里还额外设置了参数g和e,通过给这两个参数设置不同的值可以快速地控制分组卷积的组数和压缩通道的倍数。
1
2
3
4
5
6
7
8
9
10
11
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
10.4 CSP Bottleneck结构
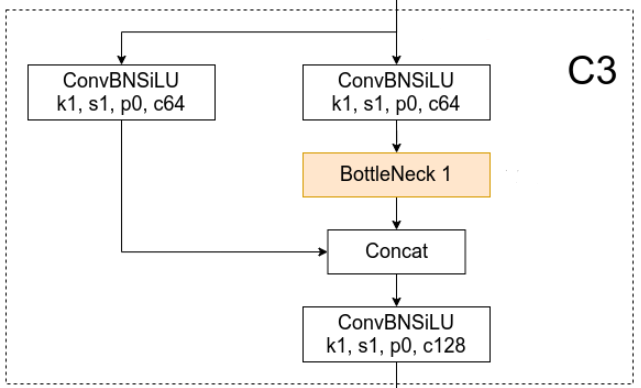
C3结构其实就是带有三个卷积的CSP Bottleneck结构,将10.3的封装好的Bottleneck结构加入到了C3模块中,就构成了一个新的网络结构。此案例是想让大家了解模块的复用性。
1
2
3
4
5
6
7
8
9
10
11
class C3(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
10.5 复现Darknet53网络结构
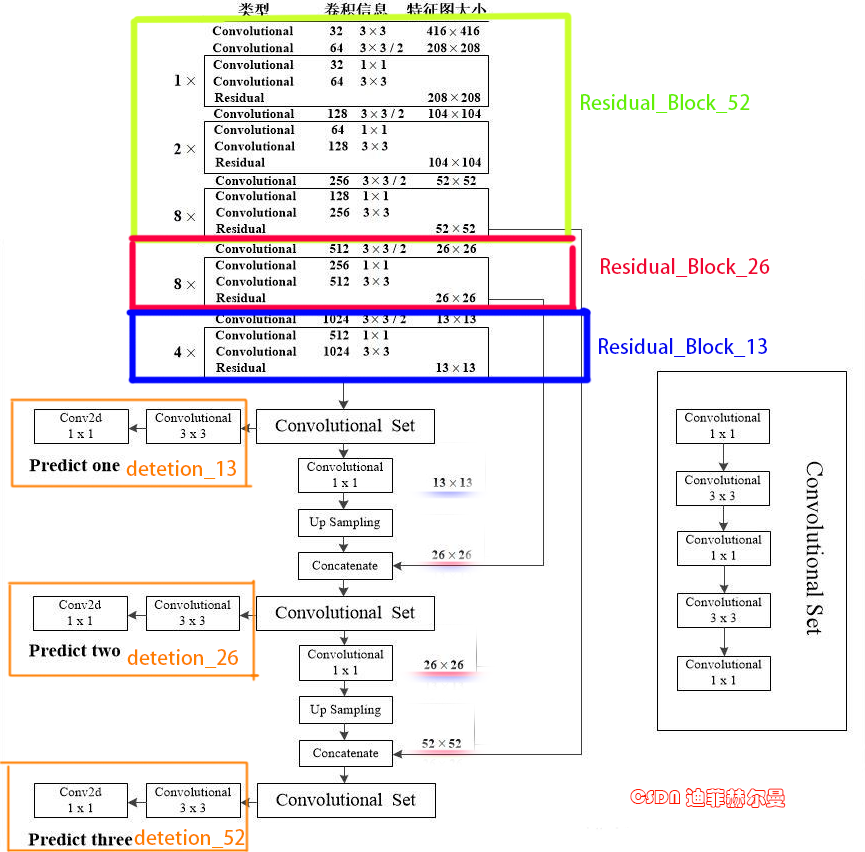
下面我们来复现一个完整的网络结构,我已经将各个模块进行了划分,为便于大家阅读,我模块的命名规则是与上图保持一致的,写法比较基础。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
from torch import nn
from torch.nn import functional
import torch
class ConvolutionalLayers(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding,bias=False):
super(ConvolutionalLayers, self).__init__()
self.sub_module = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding,bias=bias),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU()
)
def forward(self,x):
return self.sub_module(x)
class Residual(nn.Module):
def __init__(self, in_channels):
super(Residual, self).__init__()
self.sub_module = nn.Sequential(
ConvolutionalLayers(in_channels, in_channels // 2, 1, 1, 0),
ConvolutionalLayers(in_channels // 2, in_channels, 3, 1, 1),
)
def forward(self, x):
return x + self.sub_module(x) #残差块的实现方式要注意一下
class Convolutional_Set(nn.Module):
def __init__(self, in_channels, out_channels):
super(Convolutional_Set, self).__init__()
self.sub_module = nn.Sequential(
ConvolutionalLayers(in_channels, out_channels, 1, 1, 0),
ConvolutionalLayers(out_channels, in_channels, 3, 1, 1),
ConvolutionalLayers(in_channels, out_channels, 1, 1, 0),
ConvolutionalLayers(out_channels, in_channels, 3, 1, 1),
ConvolutionalLayers(in_channels, out_channels, 1, 1, 0),
)
def forward(self, x):
return self.sub_module(x)
class UpSamplingLayers(nn.Module):
def __init__(self):
super(UpSamplingLayers, self).__init__()
def forward(self,x):
return functional.interpolate(x,scale_factor=2,mode='nearest')
class Darknet53(nn.Module):
def __init__(self):
super(Darknet53, self).__init__()
self.Residual_Block_52=nn.Sequential(
ConvolutionalLayers(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1),
ConvolutionalLayers(in_channels=32, out_channels=64, kernel_size=3, stride=2, padding=1),
Residual(64),
ConvolutionalLayers(in_channels=64, out_channels=128, kernel_size=3, stride=2, padding=1),
Residual(128),
Residual(128),
ConvolutionalLayers(in_channels=128, out_channels=256, kernel_size=3, stride=2, padding=1),
Residual(256),
Residual(256),
Residual(256),
Residual(256),
Residual(256),
Residual(256),
Residual(256),
Residual(256),
)
self.Residual_Block_26=nn.Sequential(
ConvolutionalLayers(in_channels=256, out_channels=512, kernel_size=3, stride=2, padding=1),
Residual(512),
Residual(512),
Residual(512),
Residual(512),
Residual(512),
Residual(512),
Residual(512),
Residual(512),
)
self.Residual_Block_13 = nn.Sequential(
ConvolutionalLayers(in_channels=512, out_channels=1024, kernel_size=3, stride=2, padding=1),
Residual(1024),
Residual(1024),
Residual(1024),
Residual(1024),
)
#----------------------------------------------------------
self.convset_13=nn.Sequential(
Convolutional_Set(1024,512)
)
#Predict one
self.detetion_13=nn.Sequential(
ConvolutionalLayers(in_channels=512,out_channels=1024,kernel_size=3,stride=1,padding=1),
nn.Conv2d(1024,24,1,1,0)
)
self.up_13to26=nn.Sequential(
ConvolutionalLayers(512,256,3,1,1),
UpSamplingLayers()
)
#------------------------------------------------------------
self.convset_26 = nn.Sequential(
Convolutional_Set(768,256)
)
# Predict two
self.detetion_26 = nn.Sequential(
ConvolutionalLayers(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.Conv2d(512, 24, 1, 1, 0)
)
self.up_26to52 = nn.Sequential(
ConvolutionalLayers(256, 128, 3, 1, 1),
UpSamplingLayers()
)
#------------------------------------------------------------
self.convset_52 = nn.Sequential(
Convolutional_Set(384, 128)
)
# Predict three
self.detetion_52 = nn.Sequential(
ConvolutionalLayers(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.Conv2d(256, 24, 1, 1, 0)
)
def forward(self,x):
Residual_output_52 = self.Residual_Block_52(x)
Residual_output_26 = self.Residual_Block_26(Residual_output_52)
Residual_output_13 = self.Residual_Block_13(Residual_output_26)
convset_out_13 = self.convset_13(Residual_output_13)
detetion_out_13 = self.detetion_13(convset_out_13)
up_out_26 = self.up_13to26(convset_out_13)
route_out_26 = torch.cat((up_out_26,Residual_output_26), dim=1)
convset_out_26 = self.convset_26(route_out_26)
detetion_out_26 = self.detetion_26(convset_out_26)
up_out_52 = self.up_26to52(convset_out_26)
route_out_52 = torch.cat((up_out_52, Residual_output_52), dim=1)
convset_out_52 = self.convset_52(route_out_52)
detetion_out_52 = self.detetion_52(convset_out_52)
return detetion_out_13, detetion_out_26, detetion_out_52
if __name__ == '__main__':
yolo = Darknet53()
x = torch.randn(1, 3, 416, 416)
y = yolo(x)
print(y[0].shape)
print(y[1].shape)
print(y[2].shape)
10.6 复现ShuffleNet v2网络结构
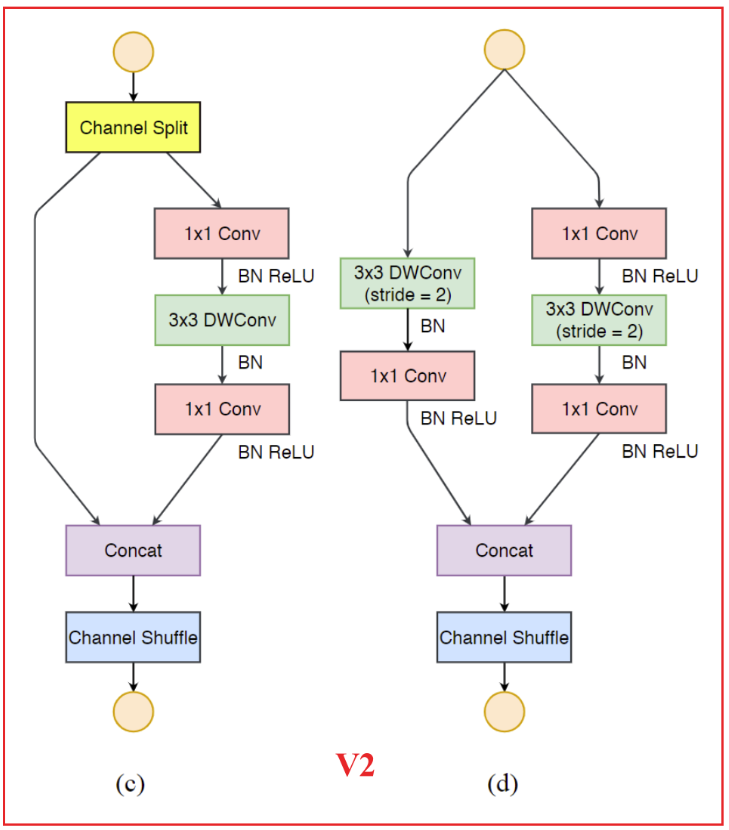
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
from torch import nn
from torch.nn import functional
import torch
from torchsummary import summary
# 通道重排,跨group信息交流
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
class CBRM(nn.Module):
def __init__(self, c1, c2): # ch_in, ch_out
super(CBRM, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c2),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
def forward(self, x):
return self.maxpool(self.conv(x))
class Shuffle_Block(nn.Module):
def __init__(self, inp, oup, stride):
super(Shuffle_Block, self).__init__()
if not (1 <= stride <= 3): #ShuffleNet模块有两种,一种常规特征提取,另一种降采样的特征提取
raise ValueError('illegal stride value')
self.stride = stride
branch_features = oup // 2
assert (self.stride != 1) or (inp == branch_features << 1)
if self.stride > 1:
self.branch1 = nn.Sequential(
self.depthwise_conv(inp, inp, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(inp),
nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(inp if (self.stride > 1) else branch_features,
branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
@staticmethod
def depthwise_conv(i, o, kernel_size, stride=1, padding=0, bias=False):
return nn.Conv2d(i, o, kernel_size, stride, padding, bias=bias, groups=i)
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1) # 按照维度1进行split
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
class ShuffleNetV2(nn.Module):
def __init__(self):
super(ShuffleNetV2, self).__init__()
self.MobileNet_01 = nn.Sequential(
CBRM(3, 32), # 160x160
Shuffle_Block(32, 128, 2), # 80x80
Shuffle_Block(128, 128, 1), # 80x80
Shuffle_Block(128, 256, 2), # 40x40
Shuffle_Block(256, 256, 1), # 40x40
Shuffle_Block(256, 512, 2), # 20x20
Shuffle_Block(512, 512, 1), # 20x20
)
def forward(self, x):
x = self.MobileNet_01(x)
return x
if __name__ == '__main__':
shufflenetv2 = ShuffleNetV2()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
inputs = shufflenetv2.to(device)
summary(inputs, (3, 640, 640), batch_size=1, device="cuda") # 分别是输入数据的三个维度
#print(shufflenetv2)
11. 迁移学习训练过程
1
2
3
4
5
6
7
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import numpy as np
from PIL import Image
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 数据预处理
transform = transforms.Compose([
transforms.RandomResizedCrop(224),# 对图像进行随机的crop以后再resize成固定大小
transforms.RandomRotation(20), # 随机旋转角度
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转
transforms.ToTensor()
])
# 读取数据
root = 'D:\Pycharm_Projects\datasets\Small_DogVsCat'
train_dataset = datasets.ImageFolder(root + '/train', transform)
test_dataset = datasets.ImageFolder(root + '/val', transform)
# 导入数据
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=8, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=8, shuffle=True)
1
2
3
4
classes = train_dataset.classes
classes_index = train_dataset.class_to_idx
print(classes)
print(classes_index)
```plain text [‘Cat’, ‘Dog’] {‘Cat’: 0, ‘Dog’: 1}
1
2
3
4
```python
model = models.vgg16(pretrained = True)
print(model)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
1
2
3
4
5
6
7
8
9
# 如果我们想只训练模型的全连接层
for param in model.parameters():
param.requires_grad = False
# 构建新的全连接层
model.classifier = torch.nn.Sequential(torch.nn.Linear(25088, 100),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(100, 2))
1
2
3
4
5
LR = 0.0001
# 定义代价函数
entropy_loss = nn.CrossEntropyLoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), LR, momentum=0.9)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
def train():
model.train()
for i, data in enumerate(train_loader):
# 获得数据和对应的标签
inputs, labels = data
# 获得模型预测结果,(64,10)
out = model(inputs)
# 交叉熵代价函数out(batch,C),labels(batch)
loss = entropy_loss(out, labels)
# 梯度清0
optimizer.zero_grad()
# 计算梯度
loss.backward()
# 修改权值
optimizer.step()
def test():
model.eval()
correct = 0
for i, data in enumerate(test_loader):
# 获得数据和对应的标签
inputs, labels = data
# 获得模型预测结果
out = model(inputs)
# 获得最大值,以及最大值所在的位置
_, predicted = torch.max(out, 1)
# 预测正确的数量
correct += (predicted == labels).sum()
print("Test acc: {0}".format(correct.item() / len(test_dataset)))
correct = 0
for i, data in enumerate(train_loader):
# 获得数据和对应的标签
inputs, labels = data
# 获得模型预测结果
out = model(inputs)
# 获得最大值,以及最大值所在的位置
_, predicted = torch.max(out, 1)
# 预测正确的数量
correct += (predicted == labels).sum()
print("Train acc: {0}".format(correct.item() / len(train_dataset)))
1
2
3
4
5
6
for epoch in range(0, 10):
print('epoch:',epoch)
train()
test()
torch.save(model.state_dict(), 'cat_dog_cnn.pth')
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
epoch: 0
Test acc: 0.65
Train acc: 0.5166666666666667
epoch: 1
Test acc: 0.55
Train acc: 0.5833333333333334
epoch: 2
Test acc: 0.6
Train acc: 0.7666666666666667
epoch: 3
Test acc: 0.85
Train acc: 0.7666666666666667
epoch: 4
Test acc: 0.75
Train acc: 0.8333333333333334
epoch: 5
Test acc: 0.85
Train acc: 0.8
epoch: 6
Test acc: 0.75
Train acc: 0.75
epoch: 7
Test acc: 0.75
Train acc: 0.85
epoch: 8
Test acc: 0.75
Train acc: 0.7666666666666667
epoch: 9
Test acc: 0.85
Train acc: 0.8
1
2
3
4
5
6
7
8
9
10
model = models.vgg16(pretrained = True)
# 构建新的全连接层
model.classifier = torch.nn.Sequential(torch.nn.Linear(25088, 100),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(100, 2))
model.load_state_dict(torch.load('cat_dog_cnn.pth'))
model.eval()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=100, bias=True)
(1): ReLU()
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=100, out_features=2, bias=True)
)
)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--no-mps', action='store_true', default=False,
help='disables macOS GPU training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
if use_cuda:
device = torch.device("cuda")
else:
device = torch.device("cpu")
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
if args.save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
if __name__ == '__main__':
main()
1
2
3
4
5
6
7
label = np.array(['cat','dog'])
# 数据预处理
transform = transforms.Compose([
transforms.Resize(224),
transforms.ToTensor()
])
1
2
3
4
5
6
7
8
9
10
11
def predict(image_path):
# 打开图片
img = Image.open(image_path)
# 数据处理,再增加一个维度
img = transform(img).unsqueeze(0)
# 预测得到结果
outputs = model(img)
# 获得最大值所在位置
_, predicted = torch.max(outputs,1)
# 转化为类别名称
print(label[predicted.item()])
1
predict(r"D:\Pycharm_Projects\datasets\Small_DogVsCat\val\Dog\dog.1251.jpg")
1
dog
12. 完整模型训练过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
# 准备数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# length 长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 如果train_data_size=10, 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用 DataLoader 来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 搭建神经网络
class My_Module(nn.Module):
def __init__(self):
super(My_Module, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64 * 4 * 4, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
if __name__ == '__main__':
YOLO = My_Module()
input = torch.ones((64, 3, 32, 32))
output = YOLO(input)
print(output.shape)
# 创建网络模型
YOLO = My_Module()
# 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器
# learning_rate = 0.01
# 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
learning_rate = 1e-2
optimizer = torch.optim.SGD(YOLO.parameters(), lr=learning_rate)
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs_train")
for i in range(epoch):
print("-------第 {} 轮训练开始-------".format(i + 1))
# 训练步骤开始
YOLO.train()
for data in train_dataloader:
imgs, targets = data
outputs = YOLO(imgs)
loss = loss_fn(outputs, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 测试步骤开始
YOLO.eval()
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = YOLO(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy / test_data_size))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy / test_data_size, total_test_step)
total_test_step = total_test_step + 1
torch.save(YOLO, "YOLO_{}.pth".format(i))
print("模型已保存")
writer.close()
13. 分类网络通用代码模板
关于Pytorch模型搭建部分只能讲解这么多,主要是想让大家了解一下自己搭建模型的流程,但是在实际学习中很少自己搭建模型,所以我着重的讲了一下怎么搭建模块,掌握了这个搭建模块的方法才可以自己研究论文的创新点,有时候在代码上一点简单的改动就会产生一篇不错的论文,比如GhostConv等,但是想彻底掌握Pytorch还要大家自己多动手学习,感谢大家支持~ 下一篇马上就来 ~。