点云研究现状
基于Lidar的object检测模型包括:Point-based,Voxel-base,Point-Voxel-based,Multi-view-based。
1.1 Point-based经典模型:PointNet,PointNet++,[PointRCNN(CVPR19),IA-SSD(CVPR22)等]。基于 Point-based 的模型,直接对点云进行处理,可以减少位置信息的损失,但同时也带来了巨大的计算资源消耗,使其很难做到实时。
1.2 Voxel-based经典模型:[PointPillars(CVPR19),CenterPoint(CVPR21)等]。基于 Voxel-base 的模型,相较于 Point-base 的模型在推理速度上有所提升,但是由于模型中使用了三维卷积的 backbone,所以也仍然很难做到实时。相较于其他的模型,PointPillars 在推理速度方面有着明显的优势(遥遥领先),同时又能保持着不错的准确性。
1.3 Point-Voxel-based经典模型:[PV-RCNN(CVPR20),HVPR(CVPR21)等]。1.4 Multi-view-based经典模型:[PIXOR(CVPR18)等]。
相较于其他的模型,PointPillars 在推理速度方面有着明显的优势(遥遥领先),同时又能保持着不错的准确性。 //这个我已经复现
本质是要做到 实时性开销和信息完整准确之间的平衡 逐个点云的点单独处理 必然准确信息完整不丢失但是慢 处理成立体格子位素 必然会丢失一部分位置信息 不够准确完整但是快 所以pointpillars方法 综合考虑以上两者进行优化
pointpillars算法最突出的是提出一种柱形的编码功能,点云依然采取常用的体素组织起来。VoxelNet 直接采用体素3D卷积,SECOND采用稀疏卷积,pointpillars采用pillar方式转换成为2D卷积来加深网络,以此来提高效率与精度。至于后面接SSD还是RPN等网络,只是相对于2d卷积下的网络根据应用场景与需求来进行选取。
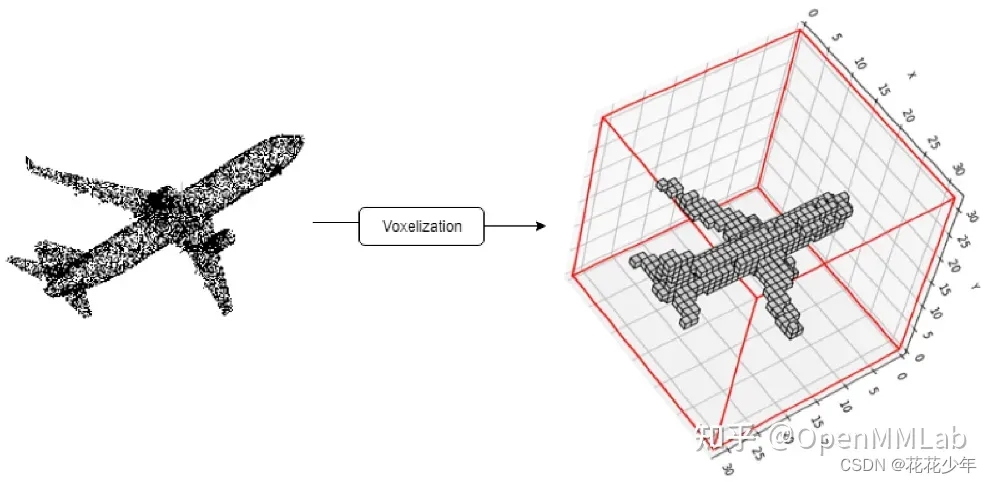
voxel-base 的模型中常常使用 voxelization(体素化)。在实际使用过程中我们都希望我们的模型又快有准,所以为了可以权衡速度和精度,VoxelNet 提出了使用 voxelization(体素化)的方法来处理点云。 点云是三维空间中的物体表示,因此一个自然的思路是将空间在长宽高三个方向划分格子,每个格子称为 voxel(体素),通过处理将其转换为 3 维数组的形式,再使用 3D 卷积和 2D 卷积的网络处理
SSD YOLO 都是单阶段网络 速度快 准确度低 一次性多个目标框分类回归 RPN+fast RCNN=faster RCNN 双阶段网路 先选出目标所在的候选框 然后再对候选框中的内容拟合分类 所以准确度高 但是速度慢
体素化也会带来一些问题,例如不可避免的会造成一些信息的丢失,对体素参数较为敏感,以及转换成 3 维数组后提取特征时通常需要用到 3 维卷积。3 维的卷积是一个相当耗时的操作,所以当我们设置体素化的粒度过大时会导致较多的信息丢失,但如果粒度过小又会导致计算时间几何增加。
PointPillars 在 VoxelNet 中的 voxel 的基础上提出了一种改进版本的点云表征方法 pillar,可以将点云转换成伪图像的形式,进而通过 2D 卷积实现目标检测,相较于 VoxelNet 将点云转换成 voxel 形式然后使用相当耗时的 3 维卷积来处理特征,PointPillars 这种使用 2 维卷积的网络在推理速度上有很大的优势。 什么是 pillar?原文中的描述是“ a pillar is a voxel with unlimited spatial extent in the z direction ”,其实很简单,将空间的 x,y 轴两个方向上划分格子,然后再将每个格子在 z 轴上拉伸,使其可以覆盖整个空间 z 轴,就可以得到一个 pillar,且空间中的每个点都可以划分到某个 pillar 中。
点云配准 和滤波 与 2D 3D融合相机标定 也都值得研究 以上为对 @高焜 @杨光剑 课题的一些任务要求
Jetson + ROS + autoawre.ai 测试框架和数据集 结合CVPR顶会的文章进行复现和改进
同时 输电线缆 架空线和直埋通道防外力破坏的工程项目也在进行 可以作为场景的验证
研一 同学感兴趣的都可以研究 3D激光雷达Lidar 点云数据的定位 识别 跟踪 等 是比较新的内容道理和SSD YOLO faster RCNN等二维卷积算法密切相关 目前都是基于attention 注意力机制 transformer等来改进