机器学习基础
一 机器学习基础
1. 标量、向量、矩阵、张量的概念及示例
1.1 标量、向量、矩阵、张量概念
一般来说,当前所有的机器学习系统都使用张量作为基本的数据结构。张量对这个领域非常的重要,重要到Google的TensorFlow都以它来命名。那么什么是张量呢?
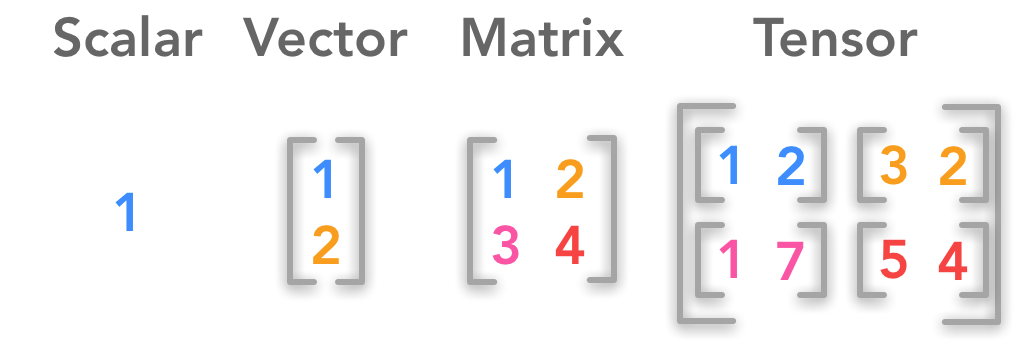
标量(0D张量)
仅包含一个数字的张量叫做标量(scalar,也叫标量张量、零维张量、0D张量)。在Numpy中,一个 float32 或 float64 的数字就是一个标量。
向量(1D张量)
数字组成的数组叫做向量(vector)或一维张量(1D张量)。通过次序中的索引,我们可以确定每个单独的数。通常我们赋予向量粗体的小写变量名称,比如 x 。向量中的元素可以通过带脚标的斜体表示。向量 x 的第一个元素是 x1,第二个元素是 x2,以此类推。
矩阵(2D张量)
向量组成的二维数组叫做矩阵(matrix)。其中的每一个元素由两个索引确定,一个索引表示为矩阵中的一行,另一个索引表示为矩阵中的一列,每个索引都有数值型的取值,我们通常会赋予矩阵粗体的大写变量名称,比如 A。
张量
超过二维的数组叫做张量(tensor)。一般地,一个数组中的元素分布在若干维坐标的规则网格中,我们将其称之为张量。使用 A 来表示张量 “A”。张量 A 中坐标为 (i, j, k) 的元素记作 A(i, j, k) 。
1.2 标量、向量、矩阵、张量代码示例
1
2
3
4
5
6
import numpy as np
scalar = np.array(1) #标量
vector = np.array([1,2,3,4]) #向量
matrix = np.array([[1,2,3],[4,5,6],[7,8,9]]) #矩阵
tensor = np.array([[[1,2],[3,4]],[[5,6],[7,8]]])#张量
1.3 标量、向量、矩阵、张量具体应用示例
- 向量数据: 2D 张量,形状为 (samples, features)
- 时间序列数据或序列数据: 3D 张量,形状为 (samples, timesteps, features)
- 图像: 4D 张量,形状为 (samples, height, width, channels) or (samples, channels, height, width)
- 视频: 5D 张量,形状为 (samples, frames, height, width, channels) or (samples, frames, channels, height, width)
向量数据
人口统计数据集,其中包括每个人的年龄、邮编和收入。每个人可以表示为包含 3 个值的向量,而整个数据集包含 100000 个人,因此可以存储在形状为 (100000, 3) 的 2D 张量中。
时间序列数据或序列数据
股票价格数据集,每一分钟,我们将股票的当前价格、前一分钟的最高价格和前一分钟的最低价格保存下来。因此每分钟被编码为一个 3D 张量,整个交易日被编码为一个形状为 (390, 3) 的 2D 张量(一个交易日有 390 分钟),而250天的数据则可以保存在一个形状为 (250, 390, 3) 的 3D 张量中。这里每个样本就是一天的股票数据。
图像数据
图像通常有3个维度,高度,宽度和颜色深度。随然灰度图只有一个颜色通道,因此可以保存在2D张量中,但按照惯例,图像张量始终都是3D张量,灰度图像的彩色通道只有1维。因此,如果图像大小为 256 × 256,那么128张灰度图组成的批量可以保存在一个形状为 (128, 256, 256, 1)的张量中,而128张彩色图像组成的批量则可以保存在一个形状为(128, 256, 256, 3)的张量中。
视频数据
一个以每秒 4 帧采样的 60 秒YouTube视频片段,视频尺寸为 144 × 256,这个视频有 240帧。4个这样的视频片段组成的批量将保存在形状为 (4, 240, 144, 256, 3) 的张量中。
2. 机器学习的学习方式
2.1 监督学习
监督学习(supervised learning)是指从标注数据中学习预测模型的机器学习问题。标注数据表示输入输出的对应关系,预测模型对给定的输入产生相应的输出。监督学习的本质是学习输入到输出的映射的统计规律。
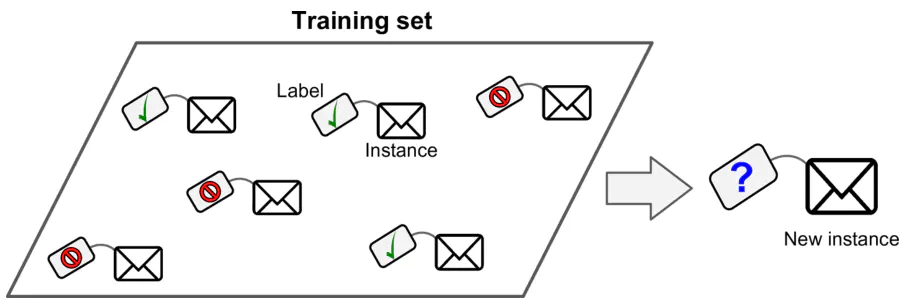
2.1.1 常见的监督学习算法
- k-Nearest Neighbors(K近邻算法)
- Linear Regression(线性回归)
- Logistic Regression (逻辑回归)
- Support Vector Machines (SVMs)(支持向量机)
- Decision Trees and Random Forests (决策树和随机深林)
- Neural networks (神经网络)
2.2 无监督学习
无监督学习(unsupervised learning)是指从无标注数据中学习预测模型的机器学习问题。无监督学习的本质是学习数据中的统计规律或潜在结构。
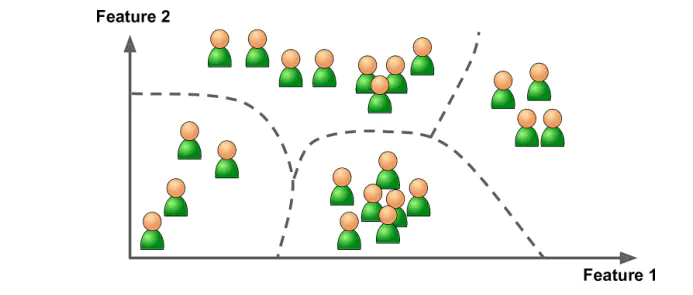
2.2.1 常见的无监督学习算法
分类(Clustering)
- k-Means
- Hierarchical Cluster Analysis (HCA)
- Expectation Maximization
可视化和降维(Visualization and dimensionality reduction)
- Principal Component Analysis (PCA)
- Kernel PCA
- Locally-Linear Embedding (LLE)
- t-distributed Stochastic Neighbor Embedding (t-SNE)
关联规则学习(Association rule learning)
- Apriori
- Eclat
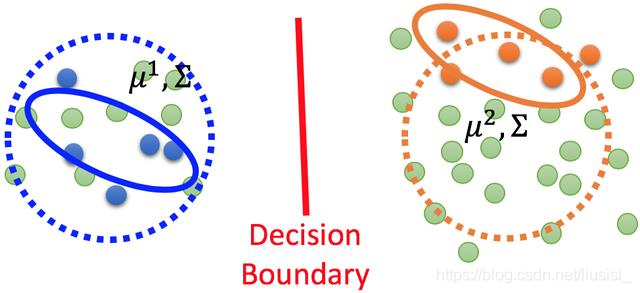
2.3 半监督学习
半监督学习(semi-supervised learning)是指利用标注数据和未标注数据学习预测模型的机器学习问题。通常有少量标注数据、大量未标注数据,因为标注数据的构建往往需要人工,成本较高,未标注数据的收集不需要太多成本。半监督学习旨在利用未标注数据中的信息,辅助标注数据,进行监督学习,以较低的成本达到较好的学习效果。
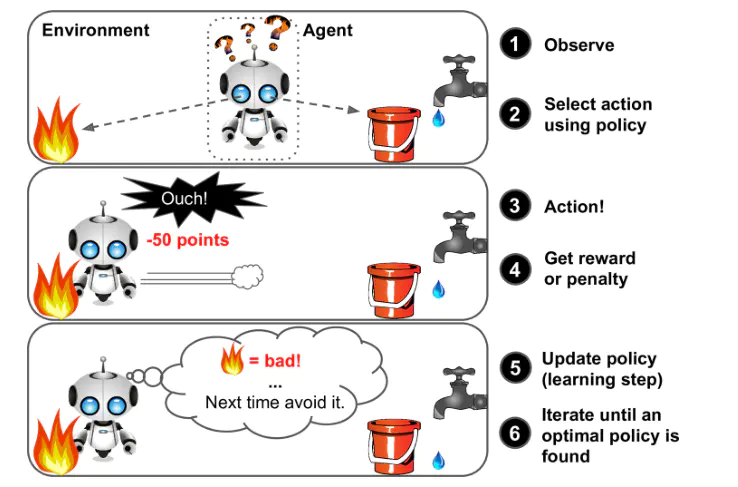
2.4 强化学习
强化学习(reinforcement learning)是指智能系统在与环境的连续互动中学习最优行为策略的机器学习问题。假设智能系统与环境的互动基于马尔可夫决策过程,智能系统能观测到的是与环境互动得到的数据序列。强化学习的本质是学习最优的序贯决策。
3. 机器学习分类和回归
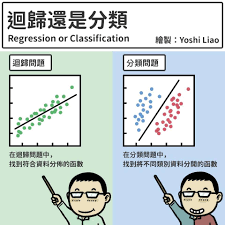
分类算法和回归算法是对真实世界不同建模的方法。
- 分类模型是认为模型的输出是离散的,例如大自然的生物被划分为不同的种类。
- 回归模型的输出是连续的,例如人的身高变化过程是一个连续过程。
因此在实际应用中,我们应该根据具体任务决定采用分类模型还是回归模型。
3.1 常见分类算法对比
| 算法 | 优点 | 缺点 |
|---|---|---|
| 贝叶斯分类法(Bayes) | 1)所需估计的参数少,对于缺失数据不敏感。2)有着坚实的数学基础,以及稳定的分类效率。 | 1)需要假设属性之间相互独立,但这往往并不成立。2)需要知道先验概率。3)分类决策存在错误率。 |
| 决策树(Decision Tree) | 1)不需要任何领域知识或参数假设。2)适合高维数据。3)简单易于理解。4)短时间内处理大量数据,得到可行且效果较好的结果。5)能够同时处理数据型和常规性属性。 | 1)对于各类别样本数量不一致数据,信息增益偏向于那些具有更多数值的特征。2)易于过拟合。3)忽略属性之间的相关性。4)不支持在线学习。 |
| 支持向量机(SVM) | 1)可以解决小样本下机器学习的问题。2)提高泛化性能。3)可以解决高维、非线性问题。超高维文本分类仍受欢迎。4)避免神经网络结构选择和局部极小的问题。 | 1)对缺失数据敏感。2)内存消耗大,难以解释。3)运行和调参复杂。 |
| K近邻(K-Nearest Neighbor) | 1)思想简单,理论成熟,既可以用来做分类也可以用来做回归;2)可用于非线性分类;3)训练时间复杂度为O(n);4)准确度高,对数据没有假设,对outlier不敏感; | 1)计算量太大。2)对于样本分类不均衡的问题,会产生误判。3)需要大量的内存。4)输出的可解释性不强。 |
| 逻辑回归(Logistic Regression) | 1)速度快。2)简单易于理解,直接看到各个特征的权重。3)能容易地更新模型吸收新的数据。4)如果想要一个概率框架,动态调整分类阀值。 | 特征处理复杂。需要归一化和较多的特征工程。 |
| 神经网络(Neural Network) | 1)分类准确率高。2)并行处理能力强。3)分布式存储和学习能力强。4)鲁棒性较强,不易受噪声影响。 | 1)需要大量参数(网络拓扑、阀值、阈值)。2)结果难以解释。3)训练时间过长。 |
| Adaboosting(Adaptive Boosting) | 1)adaboost是一种有很高精度的分类器。2)可以使用各种方法构建子分类器,Adaboost算法提供的是框架。3)当使用简单分类器时,计算出的结果是可以理解的。而且弱分类器构造极其简单。4)简单,不用做特征筛选。5)不用担心overfitting。 | 对outlier比较敏感 |
3.2 回归算法的分类
依据因变量不同,可以有如下划分:
- 如果是连续的,就是多重线性回归。
- 如果是二项分布,就是逻辑回归。
- 如果是泊松(Poisson)分布,就是泊松回归。
- 如果是负二项分布,就是负二项回归。
- 逻辑回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释。所以实际中最常用的就是二分类的逻辑回归。
3.3 逻辑回归适用性
逻辑回归可用于以下几个方面:
- 用于概率预测。用于可能性预测时,得到的结果有可比性。比如根据模型进而预测在不同的自变量情况下,发生某病或某种情况的概率有多大。
- 用于分类。实际上跟预测有些类似,也是根据模型,判断某人属于某种疾病或属于某种情况的概率有多大,也就是看一下这个人有多大的可能性是属于某种疾病。进行分类时,仅需要设定一个阈值即可,可能性高于阈值是一类,低于阈值是另一类。
- 寻找危险因素。寻找某一疾病的危险因素等。
- 仅能用于线性问题。只有当目标和特征是线性关系时,才能用逻辑回归。在应用逻辑回归时注意两点:一是当知道模型是非线性时,不适用逻辑回归;二是当使用逻辑回归时,应注意选择和目标为线性关系的特征。
- 各特征之间不需要满足条件独立假设,但各个特征的贡献独立计算。
3.4 线性回归与逻辑回归的区别
线性回归与逻辑回归的区别如下描述:
- 线性回归的样本的输出,都是连续值, y ∈ (−∞, +∞) ,而逻辑回归中 y ∈ (0, 1) ,只能取 0 和 1。
- 对于拟合函数也有本质上的差别:
线性回归: f(x) = θTx = θ1x1 + θ2x2 + … + θnxn
| 逻辑回归: f(x) = P(y = 1 | x; θ) = g(θTx) 其中, $g(z)=\frac{1}{1+e^{-z}}$ |
可以看出,线性回归的拟合函数,是对 f(x) 的输出变量 y 的拟合,而逻辑回归的拟合函数是对为1类样本的概率的拟合。
那么,为什么要以1类样本的概率进行拟合呢,为什么可以这样拟合呢?
θTx = 0 就相当于 1类和0类的决策边界:
当 θTx > 0 ,则 y > 0.5;若 θTx → +∞,则 y → 1 ,即 y为1类;
当 θTx < 0 ,则 y < 0.5;若 θTx → −∞,则 y → 0 ,即 y为0类;
这个时候就能看出区别,在线性回归中 θTx 为预测值的拟合函数;而在逻辑回归中 θTx 为决策边界。下表为线性回归和逻辑回归的区别。
| 线性回归 | 逻辑回归 | |
|---|---|---|
| 目的 | 预测 | 分类 |
| y(i) | 未知 | (0, 1) |
| 函数 | 拟合函数 | 预测函数 |
| 参数计算方式 | 最小二乘法 | 极大似然估计 |
3.5 机器学习分类回归术语表
- 样本(sample)或输入(input):进入模型的数据点。
- 预测(prediction)或输出(output):从模型出来的结果。
- 目标(target):真实值。对外部数据源,理想情况下,模型应该能够预测出目标。
- 预测误差(perdiction error)或损失值(loss value):模型预测与目标之间的距离。
- 类别(class):分类问题中供选择的一组标签。例如,对猫狗图像进行分类时,“狗”和“猫”就是两个类别。
- 标签(label):分类问题中类别标注的具体例子。比如,如果1,2,3,4号图像被标注为包含类别“狗”,那么“狗”就是1,2,3,4号图像的标签。
- 真值(ground-truth)或标注(annotation):数据集的所有目标,通常由人工收集。
- 二分类(binary calssification):一种分类任务,每个输入样本都应该被划分到两个互斥的类别中。
- 多分类(multiclass classification):一种分类任务,每个输入样本都应该划分到两个以上的类别中,比如手写数字分类。
- 多标签分类(multilabel calssification):一种分类任务,每个输入样本都可以分配多个标签。举个例子,如果一幅图像里可能既有猫又有狗,那么应该同时标注“猫”标签和“狗”标签。每幅图像的标签个数通常是可变的。
- 标量回归(scalar regression):目标是连续标量值的任务。预测房价就是一个很好的例子,不同的目标价格形成一个连续的空间。
- 向量回归(vector regression):目标是一组连续值(比如一个连续向量)的任务。如果对多个值(比如图像边界框的坐标)进行回归,那就是向量回归。
- 小批量(mini-batch)或批量(batch):模型同时处理的一小部分样本(样本数通常为8~128)。样本数通常取2的幂,这样便于GPU上的内存分配。训练时,小批量用来为模型权重计算一次梯度下降更新。
- 优化(optimization):指调节模型以在训练数据上得到最佳性能(即机器学习中的学习)
- 泛化(generalization):指训练好的模型在前所未见的数据上的性能好坏。机器学习的目的就是得到更好的泛化。
4. 损失函数
4.1 什么是损失函数
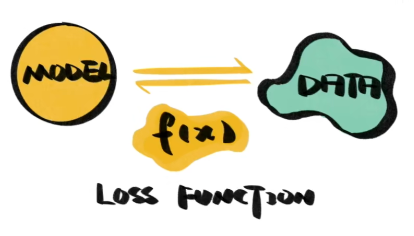
损失函数(Loss Function)又叫做误差函数,用来衡量算法的运行情况,估量模型的预测值与真实值的不一致程度,是一个非负实值函数,通常使用 L(Y, f(x)) 来表示。损失函数越小,模型的鲁棒性就越好。简单的理解就是每一个样本经过模型后会得到一个预测值,然后得到的预测值和真实值的差值就成为损失。
4.2 损失函数的作用
机器学习通过对算法中的目标函数进行不断求解优化,得到最终想要的结果。分类和回归问题中,通常使用损失函数或代价函数作为目标函数。
损失函数用来评价预测值和真实值不一样的程度。通常损失函数越好,模型的性能也越好。
4.3 常用的损失函数
4.3.1 0-1损失函数(zero-one loss)
如果预测值和目标值相等,值为 0,如果不相等,值为 1。
\[L(Y, f(x))= \begin{cases} 1,& Y\ne f(x)\\ 0,& Y = f(x) \end{cases}\]一般的在实际使用中,相等的条件过于严格,可适当放宽条件:
\[L(Y,f(x))= \begin{cases} 1,& |Y-f(x)|\geqslant T \\ 0,& |Y-f(x)|< T \end{cases}\]4.3.2 绝对值损失函数
绝对值损失函数是计算预测值与目标值的差的绝对值:
\[L(Y, f(x)) = |Y − f(x)|\]4.3.3 平方损失函数
\[L(Y, f(x)) = ∑N(Y − f(x))2\]4.3.4 对数损失函数
\[L(Y, P(Y|X)) = -\log{P(Y|X)}=-\frac{1}{N}\sum_{i=1}^N\sum_{j=1}^M y_{ij}log(p_{ij})\]4.3.5 交叉熵损失函数(Cross-entropy loss)
交叉熵函数,主要用于神经网络的分类:
\[L(Y, f(X))=-\frac{1}{m} \sum_{i}^{m} y_{i} \log(f(x_{i}))+(1-y_{i}) \log(1-f(x_{i})) \quad y_{i} \in\{0,1\}\]4.3.6 指数损失函数
\[L(Y, f(x)) = exp (−Yf(x))\]4.3.7 L1 Loss
L1损失函数也叫做最小化绝对误差(Least Abosulote Error,LAE)。LAE就是最小化真实值 yi 和预测值 f(xi) 之间差值的绝对值的和,其公式如下:
\[L=\sum_{i=1}^{n} |y_{i} - f(x_{i})|\]4.3.8 L2损失函数(LSE)
L2范数损失函数,也被称为最小平方误差(Least Square Error,LSE)。总的来说,它是把目标值与估计值的差值的平方和最小化,其公式如下:
\[L=\sum_{i=1}^{n}(y_{i}-f(x_{i}))^{2}\]4.3.9 均方差损失函数(MSE)
均方误差(Mean Square Error,MSE )是模型预测值 f(x) 与真实样本值 Y 之间差值平方和的平均值,其公式如下:
\[MSE = \frac{1}{n} \sum_{i=1}^{n}(y_{i} - f(x_{i}))^{2}\]4.3.10 平均绝对误差(MAE)
平均绝对误差(Mean Absolute Error,MAE) 是指模型预测值和真实值之间距离绝对值的平均值,其公式如下:
\[MAE = \frac{1}{n} \sum_{i=1}^{n}|y_{i} - f(x_{i})|\]5. 随机梯度下降
5.1 什么是梯度下降?
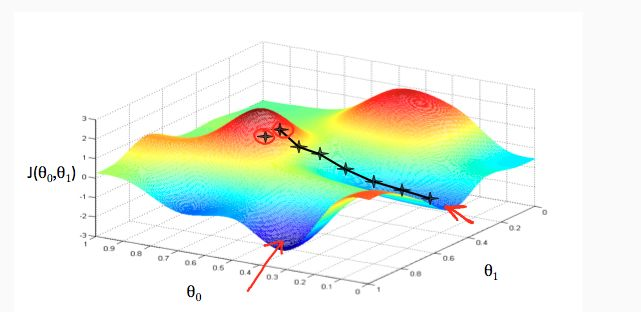
关于梯度下降其实并没有严格的定义,所以接下来我用一个比喻来抽象的讲解梯度下降的概念,顺便把前面介绍的分类、回归和损失函数都串起来回顾一下。
根据已有数据的分布来预测可能的新数据,这是回归。希望一条线将数据分割成不同的类别,这是分类。无论回归还是分类,我们的目标都是让搭建好的模型尽可能的模拟已有的数据,除了模型的结构,决定模型能否模拟成功的关键是参数,只有几个参数还好,模型中的参数成千上万,我们无法一一手动设定,这时就需要机器自己去寻找,这个过程就是我们常说的学习或是训练。在训练过程中,我们通常使用一个工具来帮助模型调整参数,它就是损失函数。 那什么是损失函数?在训练开始之前,模型代表的分布与真实的分布之间会存在一定的差异,我们以一个函数去表示误差,这个函数就是损失函数,有时也被称为误差函数,既然损失函数代表的是误差,那么一旦我们找到函数值最小的位置,就等于找到了接近正确的分布。
如何去找这个位置?如果我们的损失函数是一个开口向上的二次函数,导数就是我们最好的向导,导数为零的位置是二次函数的最低点,无论从哪里开始,只要不断向导数绝对值更低的方向调整,就能找到损失函数的最低点。真实的损失还是更像崎岖不平的山区,找到最低点没那么容易,这时我们就需要梯度,虽然他不知道最低点在哪,但可以像导数一样为我们指出向下的方向,顺着他的指引,我们总会来到山下。
至于梯度下降,就是沿着梯度所指出的方向一步一步向下走,去寻找损失函数最小的过程,然后我们就找到了接近正确的模型。
另一个经典的比喻就是假设你现在在山顶,想要以最快的速度下山,你可以看清自己的位置以及所处位置的坡度,那么沿着坡向下走,最终你会走到山底。但是如果你被蒙上双眼,那么你则只能凭借脚踩石头的感觉判断当前位置的坡度,精确性就大大下降,有时候你认为的坡,实际上可能并不是坡,走一段时间后发现没有下山,或者曲曲折折走了好多路才能下山。 类似的,批量梯度下降法(Batch Gradient Descent,BGD)就好比正常下山,而随机梯度下降法(stochastic gradi-ent descent,SGD)就好比蒙着眼睛下山。
5.2 梯度下降的优缺点
优点:
- 高效率。在梯度下降法的求解过程中,只需求解损失函数的一阶导数,计算的代价比较小,可以在很多大规模数据集上应用。
缺点:
- 求解的是局部最优值,即由于方向选择的问题,得到的结果不一定是全局最优解。
- 步长过小使得函数收敛速度慢,步长过大又容易找不到最优解。
- 靠近极小值时收敛速度减慢。
- 可能会“之字形”地下降。
5.3 梯度下降的变种
- 批量梯度下降法BGD(Batch Gradient Descent)
- 针对的是整个数据集,通过对所有的样本的计算来求解梯度的方向;
- 优点:全局最优解;易于并行实现;
- 缺点:当样本数据很多时,计算量开销大,计算速度慢。
- 小批量梯度下降法MBGD(mini-batch Gradient Descent)
- 把数据分为若干个批,按批来更新参数,这样,一个批中的一组数据共同决定了本次梯度的方向,下降起来就不容易跑偏,减少了随机性;
- 优点:减少了计算的开销量,降低了随机性。
- 随机梯度下降法SGD(stochastic gradient descent)
- 每个数据都计算一下损失函数,然后求梯度更新参数;
- 优点:计算速度快;
- 缺点:收敛性能不好,随机梯度下降法仅仅用一个样本决定梯度方向,导致解有可能不是全局最优。
- Online GD
- Online GD于Mini-batch GD/SGD的区别在于,所有训练数据只用一次,然后丢弃;
- 优点:在于可预测最终模型的变化趋势。 -
5.4 各种梯度下降法性能比较
| BGD | SGD | Mini-batch GD | Online GD | |
|---|---|---|---|---|
| 训练集 | 固定 | 固定 | 固定 | 实时更新 |
| 单次迭代样本数 | 整个训练集 | 单个样本 | 训练集的子集 | 根据具体算法定 |
| 算法复杂度 | 高 | 低 | 一般 | 低 |
| 时效性 | 低 | 一般 | 一般 | 高 |
| 收敛性 | 稳定 | 不稳定 | 较稳定 | 不稳定 |
6. 模型评估
6.1 模型评估常用方法
模型评估作为机器学习领域一项不可分割的部分,却常常被大家忽略,其实在机器学习领域中重要的不仅仅是模型结构和参数量,对模型的评估也是至关重要的,只有选择那些与应用场景匹配的评估方法才能更好的解决实际问题。
一般情况来说,单一评分标准无法完全评估一个机器学习模型。只用好坏去评估某个模型是一种欠妥的评估方式。下面介绍常用的分类模型和回归模型评估方法。
分类模型常用评估方法:
| 指标 | 描述 |
|---|---|
| Accuracy | 准确率 |
| Precision | 精准度/查准率 |
| Recall | 召回率/查全率 |
| P-R曲线 | 查准率为纵轴,查全率为横轴 |
| F1 | F1值 |
| Confusion Matrix | 混淆矩阵 |
| ROC | ROC曲线 |
| AUC | ROC曲线下的面积 |
| AP | P-R曲线下的面积 |
回归模型常用评估方法:
| 指标 | 描述 |
|---|---|
| Mean Square Error (MSE, RMSE) | 平均方差 |
| Absolute Error (MAE, RAE) | 绝对误差 |
| R-Squared | R平方值 |
6.2 误差、偏差和方差
在机器学习中,Bias(偏差),Error(误差),和Variance(方差)存在以下区别和联系:
误差:
- 误差(error):一般地,我们把学习器的实际预测输出与样本的真是输出之间的差异称为“误差”。
- Error = Bias + Variance + Noise,Error反映的是整个模型的准确度。
噪声:
- 噪声:描述了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
偏差:
- Bias衡量模型拟合训练数据的能力(训练数据不一定是整个 training dataset,而是只用于训练它的那一部分数据,例如:mini-batch),Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度。
- Bias 越小,拟合能力越高(可能产生overfitting);反之,拟合能力越低(可能产生underfitting)。
- 偏差越大,越偏离真实数据,如下图第二行所示。
方差:
- 方差公式:$S_{N}^{2}=\frac{1}{N}\sum_{i=1}^{N}(x_{i}-\bar{x})^{2}$
- Variance描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,模型的稳定程度越差。
- Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。
- Variance越小,模型的泛化的能力越高;反之,模型的泛化的能力越低。
- 如果模型在训练集上拟合效果比较优秀,但是在测试集上拟合效果比较差劣,则方差较大,说明模型的稳定程度较差,出现这种现象可能是由于模型对训练集过拟合造成的。 如下图右列所示。
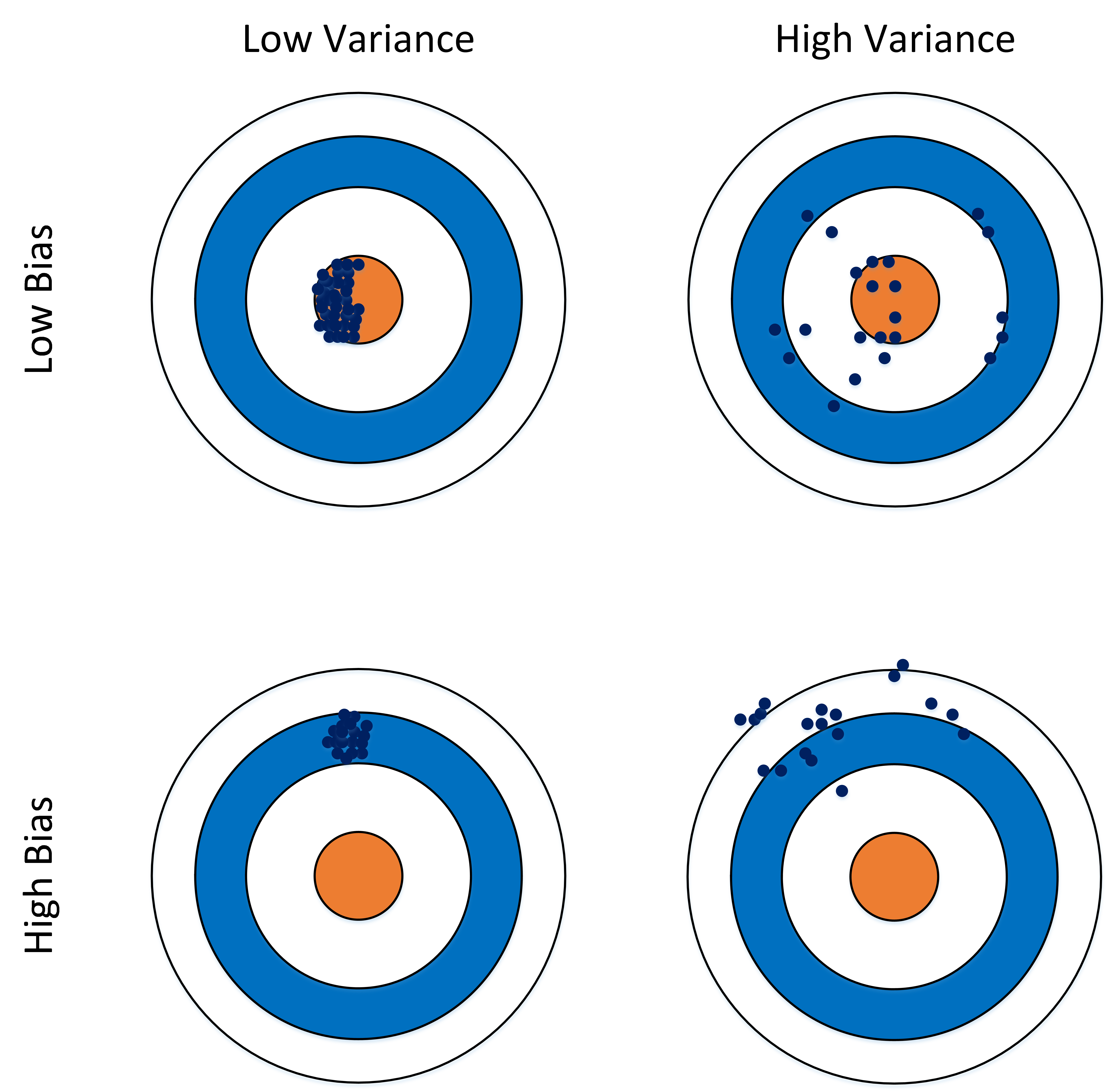
6.3 经验误差与泛化误差
经验误差(empirical error):也叫训练误差(training error),模型在训练集上的误差。
泛化误差(generalization error):模型在新样本集(测试集)上的误差称为“泛化误差”。
6.4 过拟合与欠拟合
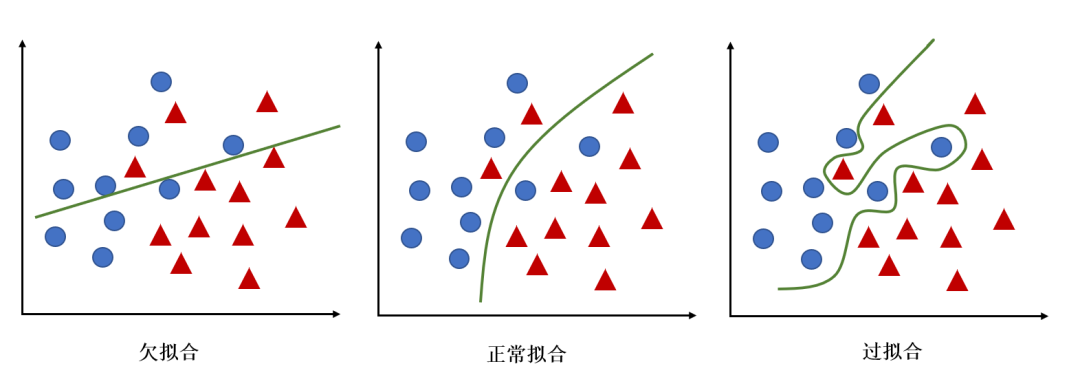
根据不同的坐标方式,欠拟合与过拟合有不同的图解方式
- 当横轴为训练样本数量,纵轴为误差时
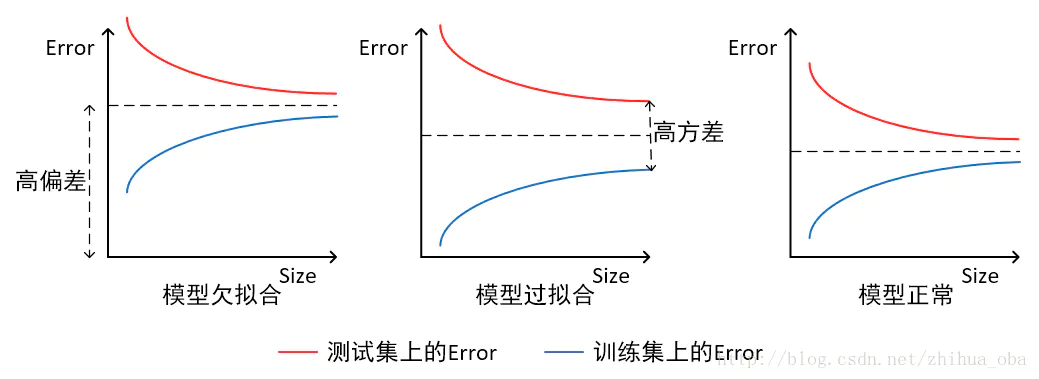
- 模型欠拟合:在训练集以及测试集上同时具有较高的误差,此时模型的偏差较大;
- 模型过拟合:在训练集上具有较低的误差,在测试集上具有较高的误差,此时模型的方差较大。
- 模型正常:在训练集以及测试集上,同时具有相对较低的偏差以及方差。
- 当横轴为模型复杂程度,纵轴为误差时
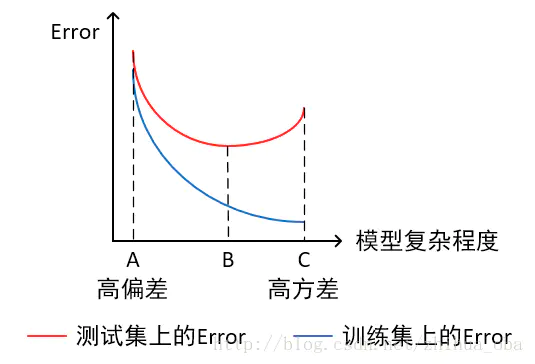
- 模型欠拟合:模型在点A处,在训练集以及测试集上同时具有较高的误差,此时模型的偏差较大。
- 模型过拟合:模型在点C处,在训练集上具有较低的误差,在测试集上具有较高的误差,此时模型的方差较大。
- 模型正常:模型复杂程度控制在点B处为最优。
- 当横轴为正则项系数,纵轴为误差时
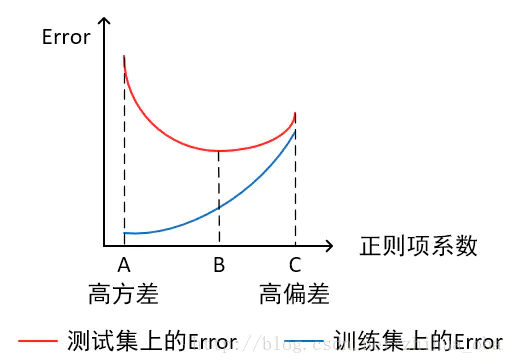
- 模型欠拟合:模型在点C处,在训练集以及测试集上同时具有较高的误差,此时模型的偏差较大。
- 模型过拟合:模型在点A处,在训练集上具有较低的误差,在测试集上具有较高的误差,此时模型的方差较大。 它通常发生在模型过于复杂的情况下,如参数过多等,会使得模型的预测性能变弱,并且增加数据的波动性。虽然模型在训练时的效果可以表现的很完美,基本上记住了数据的全部特点,但这种模型在未知数据的表现能力会大减折扣,因为简单的模型泛化能力通常都是很弱的。
- 模型正常:模型复杂程度控制在点B处为最优。
6.5 如何解决过拟合与欠拟合
如何解决欠拟合:
- 添加其他特征项。组合、泛化、相关性、上下文特征、平台特征等特征是特征添加的重要手段,有时候特征项不够会导致模型欠拟合。
- 添加多项式特征。例如将线性模型添加二次项或三次项使模型泛化能力更强。
- 可以增加模型的复杂程度。
- 减小正则化系数。正则化的目的是用来防止过拟合的,但是现在模型出现了欠拟合,则需要减少正则化参数。
如何解决过拟合:
- 重新清洗数据,数据不纯会导致过拟合,此类情况需要重新清洗数据。
- 增加训练样本数量。 使⽤更多的训练数据是解决过拟合最有效的⼿段。我们可以通过⼀定的规则来扩充训练数据,⽐如在图像分类问题上,可以通过图像的平移、旋转、缩放、加噪声等⽅式扩充数据;也可以⽤GAN⽹络来合成⼤量的新训练数据。
- 降低模型复杂程度。适当降低模型复杂度可以避免模型拟合过多的噪声数据。
- 加⼊正则化⽅法,增⼤正则项系数。给模型的参数加上⼀定的正则约束,⽐如将权值的大小加入到损失函数中
- 采用dropout方法,dropout方法,通俗的讲就是在训练的时候让神经元以一定的概率不工作。
- early stopping。 这是解决过拟合最简单实用的方式。
- 减少迭代次数。
- 增大学习率。
- 添加噪声数据。
- 树结构中,可以对树进行剪枝。
- 减少特征项。
解决欠拟合和过拟合这些方法,需要根据实际问题实际模型进行选择。
6.6 交叉验证的主要作用
为了得到更为稳健可靠的模型,对模型的泛化误差进行评估,得到模型泛化误差的近似值。当有多个模型可以选择时,我们通常选择“泛化误差”最小的模型。
交叉验证的方法有许多种,但是最常用的是:留一交叉验证、k折交叉验证。
6.7 k折交叉验证
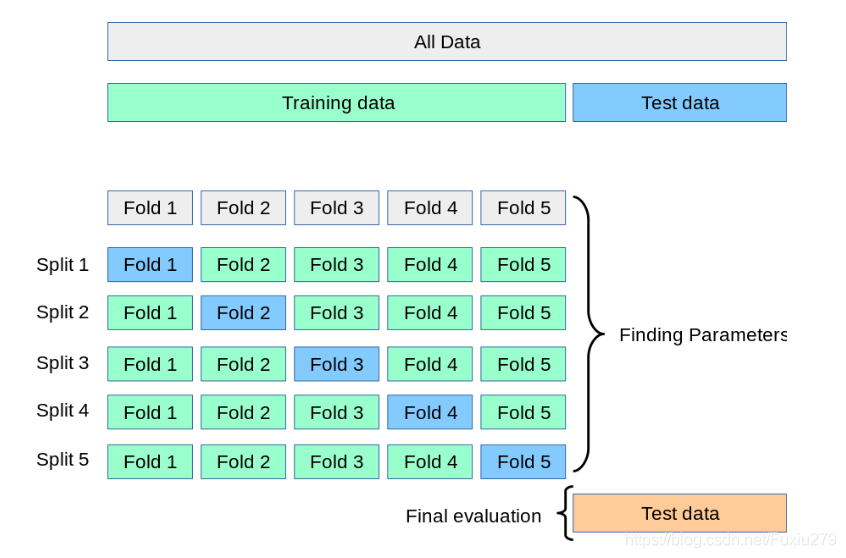
- 将含有N个样本的数据集,分成K份,每份含有 N/K 个样本。选择其中1份作为测试集,另外K-1份作为训练集,测试集就有K种情况。
- 在每种情况中,用训练集训练模型,用测试集测试模型,计算模型的泛化误差。
- 交叉验证重复K次,每份验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测,得到模型最终的泛化误差。
- 将K种情况下,模型的泛化误差取均值,得到模型最终的泛化误差。
- 一般 2 ⩽ K ⩽ 10 。 k折交叉验证的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
- 训练集中样本数量要足够多,一般至少大于总样本数的50%。
- 训练集和测试集必须从完整的数据集中均匀取样。均匀取样的目的是希望减少训练集、测试集与原数据集之间的偏差。当样本数量足够多时,通过随机取样,便可以实现均匀取样的效果。
6.8 混淆矩阵
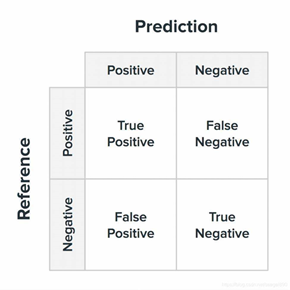
在机器学习领域,混淆矩阵(Confusion Matrix),又称为可能性矩阵或错误矩阵。混淆矩阵是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。
第一种混淆矩阵:
| 真实情况T or F | 预测为正例1,P | 预测为负例0,N |
|---|---|---|
| 本来label标记为1,预测结果真为T、假为F | TP(预测为1,实际为1) | FN(预测为0,实际为1) |
| 本来label标记为0,预测结果真为T、假为F | FP(预测为1,实际为0) | TN(预测为0,实际也为0) |
第二种混淆矩阵:
| 预测情况P or N | 实际label为1,预测对了为T | 实际label为0,预测对了为T |
|---|---|---|
| 预测为正例1,P | TP(预测为1,实际为1) | FP(预测为1,实际为0) |
| 预测为负例0,N | FN(预测为0,实际为1) | TN(预测为0,实际也为0) |
6.9 错误率及精度
- 错误率(Error Rate):分类错误的样本数占样本总数的比例。
- 精度(accuracy):分类正确的样本数占样本总数的比例。
6.10 查准率与查全率
将算法预测的结果分成四种情况:
- 正确肯定(True Positive,TP):预测为真,实际为真
- 正确否定(True Negative,TN):预测为假,实际为假
- 错误肯定(False Positive,FP):预测为真,实际为假
- 错误否定(False Negative,FN):预测为假,实际为真
那么通过这四种数据我们就可以计算出更多的评价指标
查准率 $Precision=\frac{TP}{(TP+FP)}$
即预测出为阳性的样本中,正确的有多少。区别准确率(正确预测出的样本,包括正确预测为阳性、阴性,占总样本比例)。
比如在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
查全率 $Recall = \frac{TP}{(TP+FN)}$
即正确预测为阳性的数量占总样本中阳性数量的比例。
比如在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
6.11 PR曲线
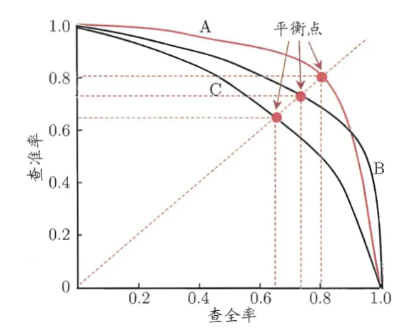
PR曲线中的 P 代表的是 precision(精准率),R代表的是 recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将 recall设置为横坐标, precision设置为纵坐标,准确率和召回率是一对矛盾的度量,一个高时另一个就会偏低,PR曲线的面积叫做 AP,mAP:meanAveragePrecosion,即各类别 AP 的平均值。
如何通过P-R曲线比较两个机器学习模型的效果呢?
- 如果一条曲线完全“包住”另一条曲线,则前者性能优于另一条曲线。
- PR曲线发生了交叉时:以PR曲线下的面积(AP)作为衡量指标,但这个指标通常难以计算。
- 使用 “平衡点”(Break-Even Point),查准率=查全率时的取值,值越大代表效果越优。
6.12 ROC曲线
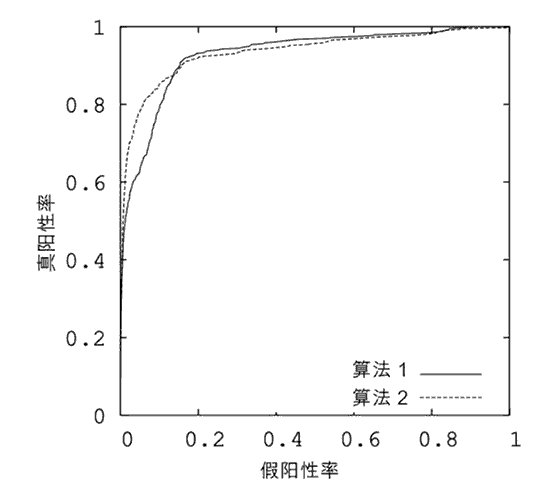
AUC就是衡量学习器优劣的一种性能指标。从定义可知,AUC可通过对 ROC曲线下各部分的面积求和而得,ROC曲线的横坐标为 FPR,纵坐标为 TPR。
真阳性率: $TPR=\frac {TP}{(TP+FN)}$
假阳性率: $FPR = \frac {FP}{(FP+TN)}$
如何利用ROC曲线对比性能?
R O C ROC ROC曲线下的面积( A U C AUC AUC)作为衡量指标,面积越大,性能越好。
6.13 模型有哪些比较检验方法
正确性分析:模型稳定性分析,稳健性分析,收敛性分析,变化趋势分析,极值分析等。 有效性分析:误差分析,参数敏感性分析,模型对比检验等。 有用性分析:关键数据求解,极值点,拐点,变化趋势分析,用数据验证动态模拟等。 高效性分析:时空复杂度分析与现有进行比较等。
6.14 为什么使用标准差
方差公式为:$S^2{N}=\frac{1}{N}\sum{i=1}^{N}(x_{i}-\bar{x})^{2}$
标准差公式为:$S_{N}=\sqrt{\frac{1}{N}\sum_{i=1}^{N}(x_{i}-\bar{x})^{2}}$
样本标准差公式为: $S_{N}=\sqrt{\frac{1}{N-1}\sum_{i=1}^{N}(x_{i}-\bar{x})^{2}}$
与方差相比,使用标准差来表示数据点的离散程度有3个好处:
- 表示离散程度的数字与样本数据点的数量级一致,更适合对数据样本形成感性认知。
- 表示离散程度的数字单位与样本数据的单位一致,更方便做后续的分析运算。
- 在样本数据大致符合正态分布的情况下,标准差具有方便估算的特性:68%的数据点落在平均值前后1个标准差的范围内、95%的数据点落在平均值前后2个标准差的范围内,而99%的数据点将会落在平均值前后3个标准差的范围内。
6.15 类别不平衡产生原因
类别不平衡(class-imbalance)是指分类任务中不同类别的训练样例数目差别很大的情况。
产生原因:分类学习算法通常都会假设不同类别的训练样例数目基本相同。如果不同类别的训练样例数目差别很大,则会影响学习结果,测试结果变差。例如二分类问题中有998个反例,正例有2个,那学习方法只需返回一个永远将新样本预测为反例的分类器,就能达到99.8%的精度;然而这样的分类器没有价值。
6.16 常见的类别不平衡问题解决方法
防止类别不平衡对学习造成的影响,在构建分类模型之前,需要对分类不平衡性问题进行处理。主要解决方法有:
- 数据增强 扩大数据集,增加包含小类样本数据的数据,更多的数据能得到更多的分布信息。
- 对大类数据欠采样 减少大类数据样本个数,使与小样本个数接近。 缺点:欠采样操作时若随机丢弃大类样本,可能会丢失重要信息。
- 对小类数据过采样 过采样:对小类的数据样本进行采样来增加小类的数据样本个数。
- 使用新评价指标 如果当前评价指标不适用,则应寻找其他具有说服力的评价指标。比如准确度这个评价指标在类 别不均衡的分类任务中并不适用,甚至进行误导。因此在类别不均衡分类任务中,需要使用更有 说服力的评价指标来对分类器进行评价。
- 选择新算法 不同的算法适用于不同的任务与数据,应该使用不同的算法进行比较。
- 数据代价加权 例如当分类任务是识别小类,那么可以对分类器的小类样本数据增加权值,降低大类样本的权值,从而使得分类器将重点集中在小类样本身上。
- 转化问题思考角度 例如在分类问题时,把小类的样本作为异常点,将问题转化为异常点检测或变化趋势检测问题。异常点检测即是对那些罕见事件进行识别。变化趋势检测区别于异常点检测在于其通过检测不寻常的变化趋势来识别。
- 将问题细化分析 对问题进行分析与挖掘,将问题划分成多个更小的问题,看这些小问题是否更容易解决。
6.17 评价指标选择案例
案例1 某奢侈品广告主们希望把自家广告定向投放给奢侈品用户。他们先是通过第三方的数据管理平台(Data Management Platform,DMP)拿到了一部分奢侈品用户的数据,并以此数据作为训练集和测试集,训练了一个奢侈品用户的分类模型。
该模型的分类准确率超过了 95%,但在实际广告投放过程中,该模型还是把大部分广告投给了非奢侈品用户,那么这是什么原因造成的呢?
这是凸显评价指标作用的一个典型案例,在回答问题之前我们首先要清楚一个概念。即我们经常听到的准确率,准确率是指分类正确的样本数量占总样本数量的比例。
准确率虽然是分类问题中最简单最直观的评价指标,但存在明显的缺陷。
比如,当负样本占比 99% 时,分类器就算把所有样本都预测为负样本,那也可以获得 99% 的准确率。所以,当正负样本的比例非常不均衡时,准确率这个评价指标对评价模型好坏是没有多大的参考意义的。
继续回到案例1这个问题,奢侈品用户只占据全体用户的一小部分,虽然模型在整体数据上的准确率很高,但是这并不代表仅对奢侈品用户的准确率也达到了相应的高度。那么这就要求我们对评价指标的选择进行进一步的考量。
案例2 Youtube提供视频模糊搜索功能,搜索模型返回的Top5准确率非常高,但是用户在实际的使用过程中却还是经常出现找不到自己目标视频的情况。
针对这个问题,我们还是要引出俩个概念,即精确率和召回率。
精确率是指分类正确的正样本个数占分类器判定为正样本的样本个数的比例。
召回率是指分类正确的正样本个数占真正的正样本个数的比例。
在排序问题中,通常没有一个确定的阈值把得到的结果直接判定为正样本或负样本,而是采用 TopN 返回结果的 Precision 值和 Recall 值来衡量模型的性能,即认为模型返回的 TopN 的结果就是模型判定的正样本,然后计算前N个位置上的准确率 PrecisionN 和前 N 个位置上的召回率 RecallN。
精确率和召回率是既矛盾又统一的两个个体,一方增加必定导致另一方减少,继续回到案例2,模型返回的 Precision5 的质量很高。但在实际应用过程中,用户为了找一些冷门的视频, 往往会寻找排在较靠后位置的结果,甚至翻页去查找目标视频。那么也就是说用户还是经常找不到想要的视频,这说明模型没有把相关的视频都找出来呈现给用户。
显然,问题出在召回率上。如果相关结果有 100 个,即使 Precision5 达到了 100%,那么 Recall5 也仅仅有 5%。
案例小结
通过以上两个案例想让大家明白模型评估的重要性,每项评估指标都有其存在的意义,我们在解决实际问题时绝不能只考虑单一片面的指标,这样的得到的结果是没有多大参考意义的,只有选择那些合适的评价指标才能更好的解决实际场景中的问题。
参考文献
[1] 周志华. 《机器学习》
[2] 李航.《统计学习方法(第2版)》
[3] 诸葛越 、葫芦娃.《百面机器学习》
[4] 弗朗索瓦·肖莱.《Python深度学习》
[5] 伊恩·古德费洛.《深度学习》
[6] 谈继勇.《深度学习》
[7] KnowingAI知智.KnowingAI知智的个人空间_哔哩哔哩_bilibili