Azkaban 全方位技术指南:从编译部署到工作流实践
本文是一篇全面的 Azkaban 技术文档,整合了 Azkaban 的介绍、与 Oozie 的对比、3.x 版本的源码编译与部署、以及 Flow 1.0 和 Flow 2.0 的详细使用教程。无论您是初学者还是有经验的用户,都能从中获得有价值的指导。
一个完整的大数据分析系统,通常由多个任务单元(如数据收集、清洗、存储、分析等)组成,这些任务单元及其依赖关系构成了复杂的工作流。为了有效管理这些工作流,工作流调度系统应运而生,Azkaban 便是其中的佼佼者。
本文将全面介绍 Azkaban,从基本概念、编译部署到两种工作流(Flow 1.0 和 Flow 2.0)的实践,为您提供一份详尽的技术指南。
一、Azkaban 简介
1.1 功能特性
Azkaban 产生于 LinkedIn,并经过多年生产环境的检验,它具备以下功能:
- 兼容任何版本的 Hadoop
- 易于使用的 Web UI
- 可以使用简单的 Web 页面进行工作流上传
- 支持按项目进行独立管理
- 定时任务调度
- 模块化和可插入的插件机制
- 完善的身份验证和授权
- 跟踪用户操作
- 支持失败和成功的电子邮件提醒
- SLA 警报和自动查杀失败任务
- 支持重试失败的任务
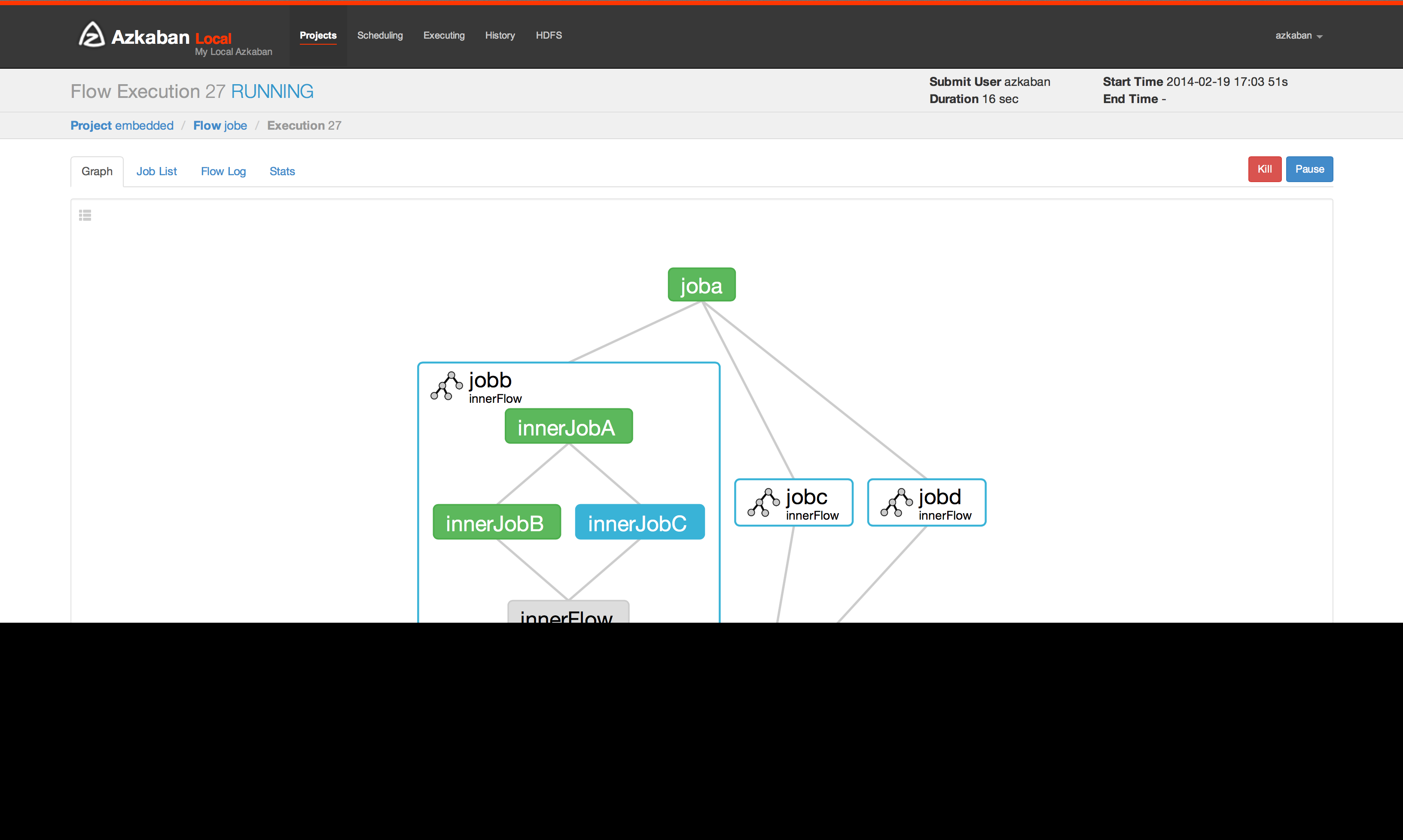
Azkaban 的设计理念是在保证功能实现的基础上兼顾易用性,其页面风格清晰明朗,下图是其 Web UI 界面:
1.2 Azkaban vs. Oozie
Azkaban 和 Oozie 都是目前使用最为广泛的工作流调度程序,其主要区别如下:
| 特性 | Azkaban | Oozie |
|---|---|---|
| 工作流定义 | 使用 Properties 文件 (Flow 1.0) 或更简洁的 YAML 文件 (Flow 2.0)。 | 使用基于 XML 的 Hadoop 流程定义语言 (HPDL),定义较为繁琐。 |
| 资源管理 | 有较严格的权限控制,如用户对工作流的读/写/执行等操作。 | 权限控制相对较弱。 |
| 部署与运行 | 部署简单,3.0后需自行编译。提供单服务模式和分布式多服务模式。 | 部署相对复杂,依赖于 Web 容器(如 Tomcat),元数据需配置外部数据库(如 MySQL)。 |
| 易用性 | Web UI 直观易用,依赖关系、执行日志清晰可见。 | UI 功能相对基础,配置和监控不如 Azkaban 直观。 |
总结:如果您的工作流不是特别复杂,且追求易用性和快速上手,轻量级的 Azkaban 是一个更好的选择。
二、Azkaban 3.x 编译及部署
Azkaban 在 3.0 版本之后不再提供预编译的安装包,需要用户自行下载源码进行编译。
2.1 源码编译
1. 准备环境
编译前,请确保您的环境中已安装以下软件:
- JDK 1.8+
- Git:
yum install git - Gradle: Azkaban 3.70.0 依赖
gradle-4.6-all.zip。您可以在源码的gradle/wrapper/gradle-wrapper.properties文件中查看所需版本。
[!TIP] 编译时程序会自动下载 Gradle,但速度可能很慢。建议手动下载所需版本的 Gradle 压缩包,放置在 gradle/wrapper/ 目录下,并修改 gradle-wrapper.properties 文件中的 distributionUrl,使其指向本地文件路径。 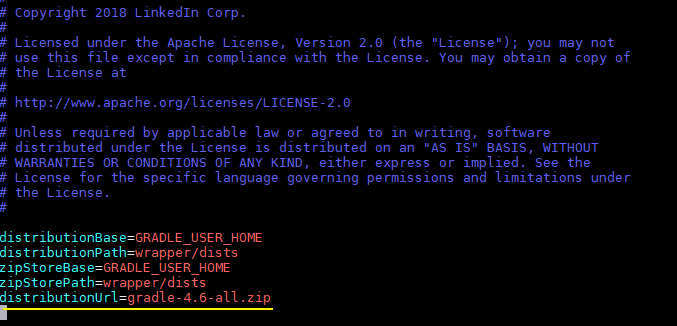
2. 下载源码
1
2
3
4
5
# 下载指定版本
wget https://github.com/azkaban/azkaban/archive/3.70.0.tar.gz
# 解压
tar -zxvf azkaban-3.70.0.tar.gz
cd azkaban-3.70.0/
3. 执行编译
在源码根目录下执行编译命令。编译过程会下载大量依赖,请耐心等待。
1
./gradlew build installDist -x test
编译成功后,您会看到 BUILD SUCCESSFUL 的提示。
2.2 部署模式
Azkaban 3.x 提供两种运行模式:
- Solo Server Mode (单服务模式): Web 管理服务器和执行服务器运行在同一个进程中,元数据默认使用内置的 H2 数据库。适用于测试或小规模场景。
- Multiple-Executor Mode (分布式多服务模式): Web 服务器和执行服务器分离,元数据存储在外部 MySQL 数据库。适合生产环境。
2.3 Solo Server 模式部署
下面以更简单的单服务模式为例进行部署。
1. 解压安装包
编译成功后,安装包位于 azkaban-solo-server/build/distributions/ 目录下。
1
2
3
# 解压
tar -zxvf azkaban-solo-server-3.70.0.tar.gz
cd azkaban-solo-server-3.70.0/
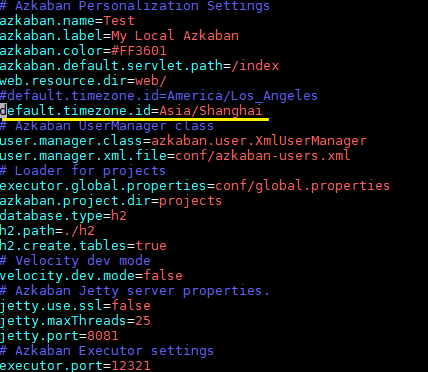
2. 修改时区(可选)
Azkaban 默认时区为 America/Los_Angeles。如果您的定时任务需要基于本地时间,请修改 conf/azkaban.properties 文件中的时区设置。
1
azkaban.default.timezone.id=Asia/Shanghai
3. 启动与验证
在 安装包根目录 下执行启动命令。
1
bin/start-solo.sh
启动后,可以通过 jps 命令查看 AzkabanSingleServer 进程是否存在。然后访问 http://<your-ip>:8081,使用默认用户名 azkaban 和密码 azkaban 登录。
三、工作流实践:Flow 1.0
Flow 1.0 是 Azkaban 传统的、基于 .job 文件的配置方式。每个任务(Job)定义在一个单独的 .job 文件中,使用 Properties 格式。
3.1 基本任务调度
- 创建项目:在 Azkaban UI 上创建一个新项目。
编写 Job 文件:创建一个
.job文件,例如hello.job。1 2 3
# hello.job type=command command=echo 'Hello Azkaban Flow 1.0!'
- 打包上传:将所有
.job文件打包成一个.zip文件,并通过 UI 上传到您的项目中。 - 执行与查看:在 UI 上找到您的 Flow,点击 “Execute Flow” 执行,并可以查看详细的执行日志。
3.2 多任务依赖调度
通过 dependencies 属性可以定义任务之间的依赖关系。
假设有五个任务,D 依赖 A、B、C,E 依赖 D。
- Task-A.job, Task-B.job, Task-C.job:
1 2
type=command command=echo 'Task A' // B, C
- Task-D.job:
1 2 3
type=command command=echo 'Task D' dependencies=Task-A,Task-B,Task-C
- Task-E.job:
1 2 3
type=command command=echo 'Task E' dependencies=Task-D
将这五个 .job 文件打包上传后,Azkaban 会自动解析依赖关系并生成工作流图。
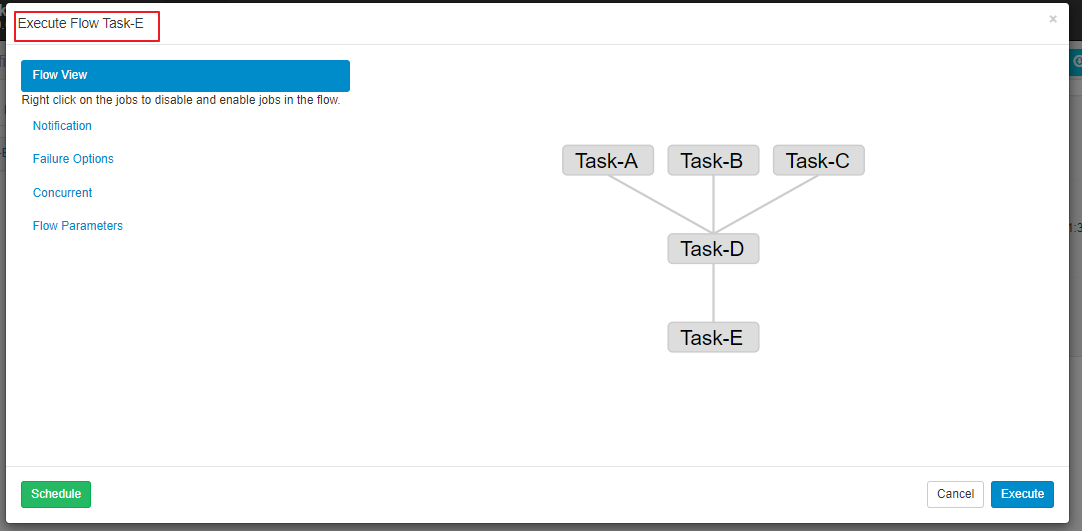
3.3 调度实战示例
调度 Hive 作业
- hive-task.job:
1 2
type=command command=/path/to/hive/bin/hive -f 'test.sql'
- test.sql:
1 2 3 4
CREATE DATABASE IF NOT EXISTS my_db; USE my_db; CREATE TABLE emp(empno int, ename string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; DESC emp;
将 hive-task.job 和 test.sql 一起打包上传。Azkaban 会在执行 command 时,在工作目录下找到 test.sql 文件。
3.4 问题排查
如果遇到 Cannot request memory ... from system for job 的错误,通常是因为执行主机的可用内存不足 3G。如果无法增加内存,可以关闭内存检查。修改 plugins/jobtypes/commonprivate.properties 文件:
1
memCheck.enabled=false
四、工作流实践:Flow 2.0
Flow 2.0 是 Azkaban 推荐的现代工作流定义方式,它使用 YAML 语法,将一个 Flow 内的所有任务和配置都定义在单个 .flow 文件中,更加简洁和强大。
4.1 启用 Flow 2.0
要让 Azkaban 识别 Flow 2.0,您需要在项目压缩包的根目录下包含一个 project.properties 文件,内容如下:
1
azkaban-flow-version:2.0
4.2 YAML 语法简介
- 大小写敏感。
- 使用缩进表示层级关系。
- 使用
#表示注释。 - 键值对用冒号分隔:
key: value(冒号后有空格)。 - 数组用短横线表示:
- item1。
4.3 多任务调度示例
使用 Flow 2.0,之前需要五个 .job 文件的依赖关系现在可以用一个 .flow 文件搞定。
- multi-tasks.flow: ```yaml nodes:
- name: jobE type: command config: command: echo “This is job E” dependsOn:
- jobD
- name: jobD type: command config: command: echo “This is job D” dependsOn:
- jobA
- jobB
- jobC
name: jobA type: command config: command: echo “This is job A”
name: jobB type: command config: command: echo “This is job B”
- name: jobC type: command config: command: echo “This is job C” ```
- name: jobE type: command config: command: echo “This is job E” dependsOn:
4.4 内嵌流 (Embedded Flow)
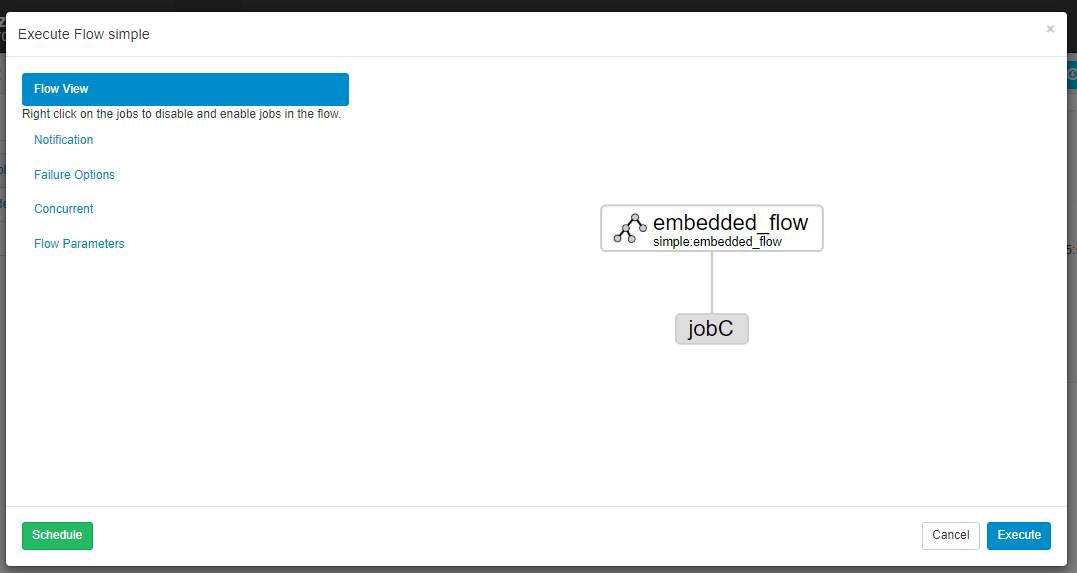
Flow 2.0 的一大亮点是支持在一个 Flow 中嵌套另一个 Flow,这对于构建模块化、可复用的工作流非常有用。
- embedded.flow: ```yaml nodes:
- name: jobC type: command config: command: echo “This is job C” dependsOn:
- embedded_flow # 依赖整个内嵌流
- name: embedded_flow type: flow # 类型为 flow nodes: # 内嵌流自己的节点定义
- name: jobB type: command config: command: echo “This is job B” dependsOn:
- jobA
- name: jobA type: command config: command: echo “This is job A” ```
- name: jobB type: command config: command: echo “This is job B” dependsOn:
- name: jobC type: command config: command: echo “This is job C” dependsOn:
上传后,UI 会展示出清晰的嵌套结构。
五、总结
Azkaban 作为一个轻量级、易于使用的工作流调度系统,非常适合中小型大数据项目。特别是 Flow 2.0 的引入,通过 YAML 和内嵌流等特性,使其在定义复杂工作流时变得更加灵活和强大。希望本篇指南能帮助您快速上手并精通 Azkaban 的使用。