AQS:CLH 同步队列
总阅读量:7472次
摘要: 原创出处http://cmsblogs.com/?p=2188「小明哥」欢迎转载,保留摘要,谢谢!
作为「小明哥」的忠实读者,「老艿艿」略作修改,记录在理解过程中,参考的资料。
此篇博客所有源码均来自 JDK 1.8
在上篇博客《【死磕 Java 并发】—– J.U.C 之 AQS:AQS 简介》中提到,AQS 内部维护着一个 FIFO 队列,该队列就是CLH 同步队列。
1. 简介
CLH 同步队列是一个 FIFO双向队列,AQS 依赖它来完成同步状态的管理:
当前线程如果获取同步状态失败时,AQS则会将当前线程已经等待状态等信息构造成一个节点(Node)并将其加入到CLH同步队列,同时会阻塞当前线程
当同步状态释放时,会把首节点唤醒(公平锁),使其再次尝试获取同步状态。
2. Node
在 CLH 同步队列中,一个节点(Node),表示一个线程,它保存着线程的引用(thread)、状态(waitStatus)、前驱节点(prev)、后继节点(next)。其定义如下:
Node 是 AbstractQueuedSynchronizer 的内部静态类。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
static final class Node {
// 共享
static final Node SHARED = new Node();
// 独占
static final Node EXCLUSIVE = null;
/**
* 因为超时或者中断,节点会被设置为取消状态,被取消的节点时不会参与到竞争中的,他会一直保持取消状态不会转变为其他状态
*/
static final int CANCELLED = 1;
/**
* 后继节点的线程处于等待状态,而当前节点的线程如果释放了同步状态或者被取消,将会通知后继节点,使后继节点的线程得以运行
*/
static final int SIGNAL = -1;
/**
* 节点在等待队列中,节点线程等待在Condition上,当其他线程对Condition调用了signal()后,该节点将会从等待队列中转移到同步队列中,加入到同步状态的获取中
*/
static final int CONDITION = -2;
/**
* 表示下一次共享式同步状态获取,将会无条件地传播下去
*/
static final int PROPAGATE = -3;
/** 等待状态 */
volatile int waitStatus;
/** 前驱节点,当节点添加到同步队列时被设置(尾部添加) */
volatile Node prev;
/** 后继节点 */
volatile Node next;
/** 等待队列中的后续节点。如果当前节点是共享的,那么字段将是一个 SHARED 常量,也就是说节点类型(独占和共享)和等待队列中的后续节点共用同一个字段 */
Node nextWaiter;
/** 获取同步状态的线程 */
volatile Thread thread;
final boolean isShared() {
return nextWaiter == SHARED;
}
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
Node() { // Used to establish initial head or SHARED marker
}
Node(Thread thread, Node mode) { // Used by addWaiter
this.nextWaiter = mode;
this.thread = thread;
}
Node(Thread thread, int waitStatus) { // Used by Condition
this.waitStatus = waitStatus;
this.thread = thread;
}
}
waitStatus字段,等待状态,用来控制线程的阻塞和唤醒,并且可以避免不必要的调用LockSupport的#park(…)和#unpark(…)方法。。目前有4种:CANCELLEDSIGNALCONDITIONPROPAGATE。
实际上,有第5种,INITAL,值为 0 ,初始状态。
胖友请认真看下每个等待状态代表的含义,它不仅仅指的是 Node自己的线程的等待状态,也可以是下一个节点的线程的等待状态。
CLH 同步队列,结构图如下:
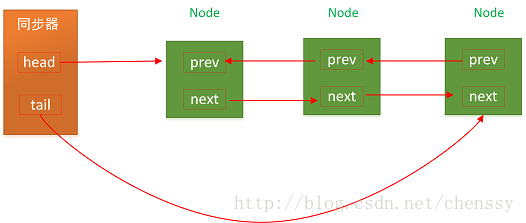
prev和next字段,是AbstractQueuedSynchronizer的字段,分别指向同步队列的头和尾。
head和tail字段,分别指向 Node 节点的前一个和后一个Node 节点,从而实现链式双向队列。再配合上prev和next字段,快速定位到同步队列的头尾。
thread字段,Node 节点对应的线程 Thread。
nextWaiter字段,Node 节点获取同步状态的模型( Mode )。#tryAcquire(int args)和#tryAcquireShared(int args)方法,分别是独占式和共享式获取同步状态。在获取失败时,它们都会调用#addWaiter(Node mode)方法入队。而nextWaiter就是用来表示是哪种模式:
SHARED静态 + 不可变字段,枚举共享模式。
EXCLUSIVE静态 + 不可变字段,枚举独占模式。
#isShared()方法,判断是否为共享式获取同步状态。
#predecessor()方法,获得 Node 节点的前一个Node 节点。在方法的内部,Node p = prev的本地拷贝,是为了避免并发情况下,prev判断完== null时,恰好被修改,从而保证线程安全。
构造方法有3个,分别是:
#Node()方法:用于SHARED的创建。
#Node(Thread thread, Node mode)方法:用于#addWaiter(Node mode)方法。
从mode方法参数中,我们也可以看出它代表获取同步状态的模式。
在本文中,我们会看到这个构造方法的使用。
#Node(Thread thread, int waitStatus)方法,用于#addConditionWaiter()方法。
在本文中,不会使用,所以解释暂时省略。
3. 入列
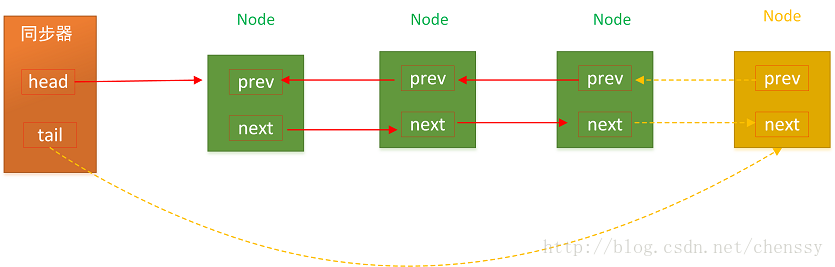
学了数据结构的我们,CLH 队列入列是再简单不过了:
tail指向新节点。
新节点的prev指向当前最后的节点。
当前最后一个节点的next指向当前节点。
过程图如下:
但是,实际上,入队逻辑实现的#addWaiter(Node)方法,需要考虑并发的情况。它通过CAS的方式,来保证正确的添加 Node 。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
private Node addWaiter(Node mode) {
// 新建节点
Node node = new Node(Thread.currentThread(), mode);
// 记录原尾节点
Node pred = tail;
// 快速尝试,添加新节点为尾节点
if (pred != null) {
// 设置新 Node 节点的尾节点为原尾节点
node.prev = pred;
// CAS 设置新的尾节点
if (compareAndSetTail(pred, node)) {
// 成功,原尾节点的下一个节点为新节点
pred.next = node;
return node;
}
}
// 失败,多次尝试,直到成功
enq(node);
return node;
}
第 3 行:创建新节点node。在创建的构造方法,mode方法参数,传递获取同步状态的模式。
第 5 行:记录原尾节点tail。
在下面的代码,会分成2部分:
第 6 至 16 行:快速尝试,添加新节点为尾节点。
第 18 行:添加失败,多次尝试,直到成功添加。
========== 第1部分 ==========
第 7 行:当原尾节点非空,才执行快速尝试的逻辑。在下面的#enq(Node node)方法中,我们会看到,首节点未初始化的时,head和tail都为空。
第 9 行:设置新节点的尾节点为原尾节点。
第 11 行:调用#compareAndSetTail(Node expect, Node update)方法,使用Unsafe来CAS设置尾节点tail为新节点。代码如下:
1
2
3
4
5
6
7
8
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long tailOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("tail"));
// 这块代码,实际在 static 代码块,此处为了方便理解,做了简化。
private final boolean compareAndSetTail(Node expect, Node update) {
return unsafe.compareAndSwapObject(this, tailOffset, expect, update);
}
如果胖友对 Unsafe 不了解,请 Google 之。比较有趣的东东。
第 13 行:添加成功,最终,将原尾节点的下一个节点为新节点。
第 14 行:返回新节点。
如果添加失败,因为存在多线程并发的情况,此时需要执行【第 18 行】的代码。
========== 第2部分 ==========
调用#enq(Node node)方法,多次尝试,直到成功添加。代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
private Node enq(final Node node) {
// 多次尝试,直到成功为止
for (;;) {
// 记录原尾节点
Node t = tail;
// 原尾节点不存在,创建首尾节点都为 new Node()
if (t == null) {
if (compareAndSetHead(new Node()))
tail = head;
// 原尾节点存在,添加新节点为尾节点
} else {
// 设置为尾节点
node.prev = t;
// CAS 设置新的尾节点
if (compareAndSetTail(t, node)) {
// 成功,原尾节点的下一个节点为新节点
t.next = node;
return t;
}
}
}
}
第 3 行:”死“循环,多次尝试,直到成功添加为止【第 18 行】。
第 5 行:记录原尾节点t。 和#addWaiter(Node node)方法的【第 5 行】相同。
第 10 至 19 行:原尾节点存在,添加新节点为尾节点。 和#addWaiter(Node node)方法的【第 7 至 16 行】相同。
第 6 至 9 行:原尾节点不存在,创建首尾节点都为new Node()。注意,此时修改的首尾节点是重新创建(new Node())的,而不是新节点!
这里,笔者的理解是,通过这样的方式,初始化好同步队列的首尾。另外,在 AbstractQueuedSynchronizer 的设计中,head字段,是一个”占位节点”(暂时没想到特别好的比喻),代表最后一个获得到同步状态的节点(线程),实际它已经出列,所以它的Node.next才是真正的队首。当然,同步队列的初始时,new Node()也是满足这个条件,因为有新的Node 进队列,目前就已经有线程获得到同步状态。
#compareAndSetHead(Node update)方法,使用 Unsafe 来 CAS 设置尾节点head为新节点。代码如下:
1
2
3
4
5
6
7
8
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long headOffset = unsafe.objectFieldOffset
(AbstractQueuedSynchronizer.class.getDeclaredField("head"));
// 这块代码,实际在 static 代码块,此处为了方便理解,做了简化。
private final boolean compareAndSetHead(Node update) {
return unsafe.compareAndSwapObject(this, headOffset, null, update);
}
注意,第三个方法参数为null,代表需要原head为空才可以设置。 和#compareAndSetTail(Node expect, Node update)方法,类似。
4. 出列
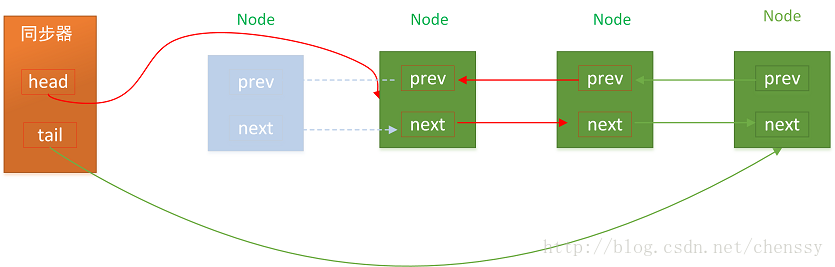
CLH 同步队列遵循 FIFO,首节点的线程释放同步状态后,将会唤醒它的下一个节点(Node.next)。而后继节点将会在获取同步状态成功时,将自己设置为首节点(head)。
这个过程非常简单,head执行该节点并断开原首节点的next和当前节点的prev即可。注意,在这个过程是不需要使用 CAS 来保证的,因为只有一个线程,能够成功获取到同步状态。
过程图如下:
#setHead(Node node)方法,实现上述的出列逻辑。代码如下:
1
2
3
4
5
private void setHead(Node node) {
head = node;
node.thread = null;
node.prev = null;
}